 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree-dimensional Bone Image Synthesis with Generative Adversarial Networks
Oct 26, 2023



Medical image processing has been highlighted as an area where deep learning-based models have the greatest potential. However, in the medical field in particular, problems of data availability and privacy are hampering research progress and thus rapid implementation in clinical routine. The generation of synthetic data not only ensures privacy, but also allows to \textit{draw} new patients with specific characteristics, enabling the development of data-driven models on a much larger scale. This work demonstrates that three-dimensional generative adversarial networks (GANs) can be efficiently trained to generate high-resolution medical volumes with finely detailed voxel-based architectures. In addition, GAN inversion is successfully implemented for the three-dimensional setting and used for extensive research on model interpretability and applications such as image morphing, attribute editing and style mixing. The results are comprehensively validated on a database of three-dimensional HR-pQCT instances representing the bone micro-architecture of the distal radius.
Uncertainty-Aware Null Space Networks for Data-Consistent Image Reconstruction
Apr 14, 2023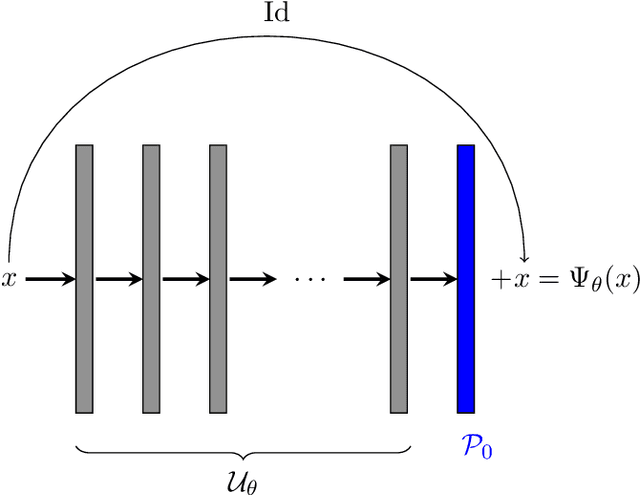
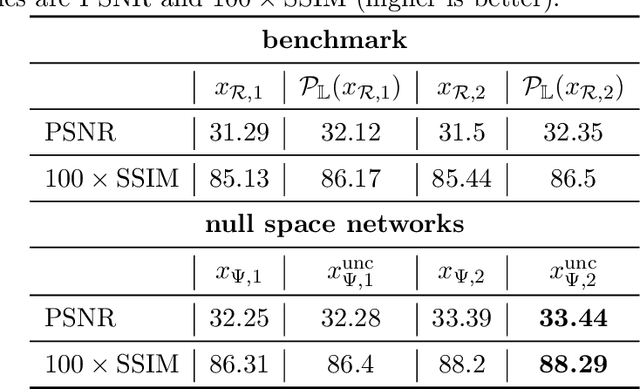
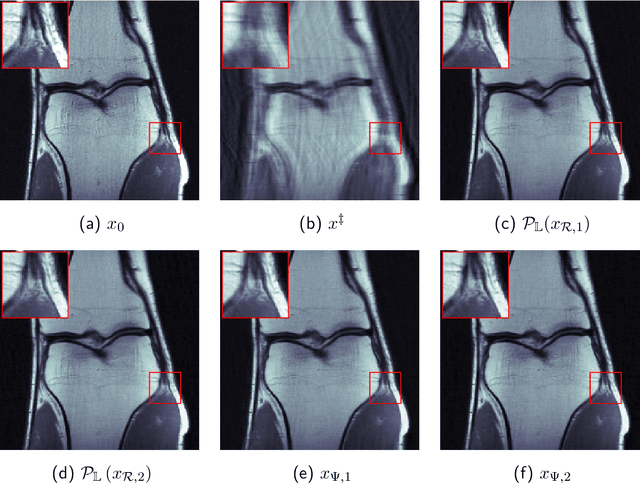
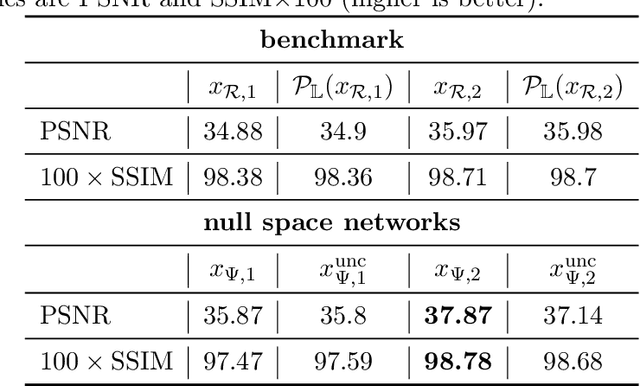
Reconstructing an image from noisy and incomplete measurements is a central task in several image processing applications. In recent years, state-of-the-art reconstruction methods have been developed based on recent advances in deep learning. Especially for highly underdetermined problems, maintaining data consistency is a key goal. This can be achieved either by iterative network architectures or by a subsequent projection of the network reconstruction. However, for such approaches to be used in safety-critical domains such as medical imaging, the network reconstruction should not only provide the user with a reconstructed image, but also with some level of confidence in the reconstruction. In order to meet these two key requirements, this paper combines deep null-space networks with uncertainty quantification. Evaluation of the proposed method includes image reconstruction from undersampled Radon measurements on a toy CT dataset and accelerated MRI reconstruction on the fastMRI dataset. This work is the first approach to solving inverse problems that additionally models data-dependent uncertainty by estimating an input-dependent scale map, providing a robust assessment of reconstruction quality.
Unsupervised Joint Image Transfer and Uncertainty Quantification using Patch Invariant Networks
Jul 09, 2022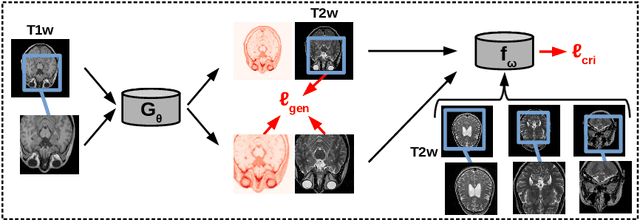
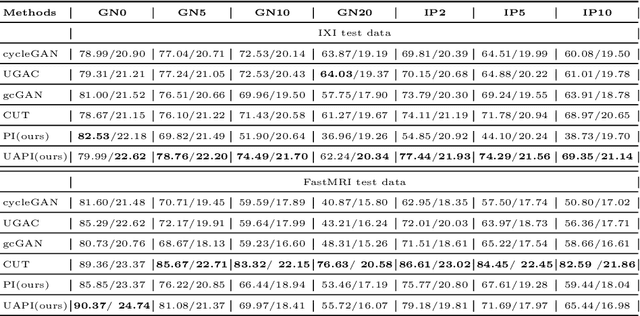

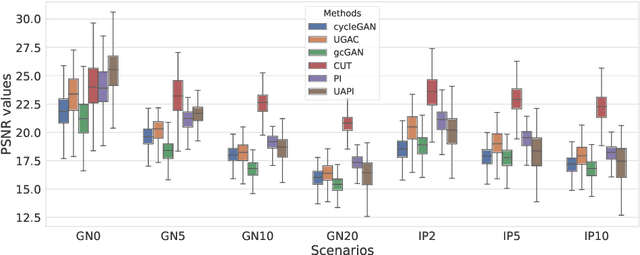
Unsupervised image transfer enables intra- and inter-modality transfer for medical applications where a large amount of paired training data is not abundant. To ensure a structure-preserving mapping from the input to the target domain, existing methods for unpaired medical image transfer are commonly based on cycle-consistency, causing additional computation resources and instability due to the learning of an inverse mapping. This paper presents a novel method for uni-directional domain mapping where no paired data is needed throughout the entire training process. A reasonable transfer is ensured by employing the GAN architecture and a novel generator loss based on patch invariance. To be more precise, generator outputs are evaluated and compared on different scales, which brings increased attention to high-frequency details as well as implicit data augmentation. This novel term also gives the opportunity to predict aleatoric uncertainty by modeling an input-dependent scale map for the patch residuals. The proposed method is comprehensively evaluated on three renowned medical databases. Superior accuracy on these datasets compared to four different state-of-the-art methods for unpaired image transfer suggests the great potential of this approach for uncertainty-aware medical image translation. Implementation of the proposed framework is released here: https://github.com/anger-man/unsupervised-image-transfer-and-uq.
Unsupervised Single-shot Depth Estimation using Perceptual Reconstruction
Feb 16, 2022

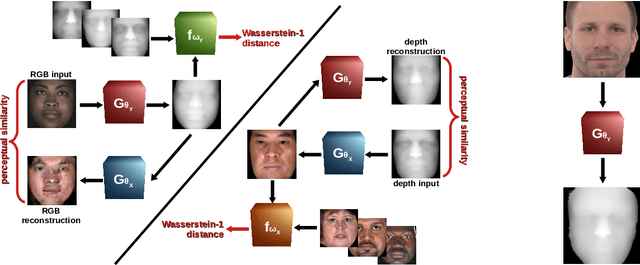

Real-time estimation of actual object depth is a module that is essential to performing various autonomous system tasks such as 3D reconstruction, scene understanding and condition assessment of machinery parts. During the last decade of machine learning, extensive deployment of deep learning methods to computer vision tasks has yielded approaches that succeed in achieving realistic depth synthesis out of a simple RGB modality. While most of these models are based on paired depth data or availability of video sequences and stereo images, methods for single-view depth synthesis in a fully unsupervised setting have hardly been explored. This study presents the most recent advances in the field of generative neural networks, leveraging them to perform fully unsupervised single-shot depth synthesis. Two generators for RGB-to-depth and depth-to-RGB transfer are implemented and simultaneously optimized using the Wasserstein-1 distance and a novel perceptual reconstruction term. To ensure that the proposed method is plausible, we comprehensively evaluate the models using industrial surface depth data as well as the Texas 3D Face Recognition Database and the SURREAL dataset that records body depth. The success observed in this study suggests the great potential for unsupervised single-shot depth estimation in real-world applications.
Unpaired Single-Image Depth Synthesis with cycle-consistent Wasserstein GANs
Mar 31, 2021



Real-time estimation of actual environment depth is an essential module for various autonomous system tasks such as localization, obstacle detection and pose estimation. During the last decade of machine learning, extensive deployment of deep learning methods to computer vision tasks yielded successful approaches for realistic depth synthesis out of a simple RGB modality. While most of these models rest on paired depth data or availability of video sequences and stereo images, there is a lack of methods facing single-image depth synthesis in an unsupervised manner. Therefore, in this study, latest advancements in the field of generative neural networks are leveraged to fully unsupervised single-image depth synthesis. To be more exact, two cycle-consistent generators for RGB-to-depth and depth-to-RGB transfer are implemented and simultaneously optimized using the Wasserstein-1 distance. To ensure plausibility of the proposed method, we apply the models to a self acquised industrial data set as well as to the renown NYU Depth v2 data set, which allows comparison with existing approaches. The observed success in this study suggests high potential for unpaired single-image depth estimation in real world applications.
Machine Learning for Nondestructive Wear Assessment in Large Internal Combustion Engines
Mar 15, 2021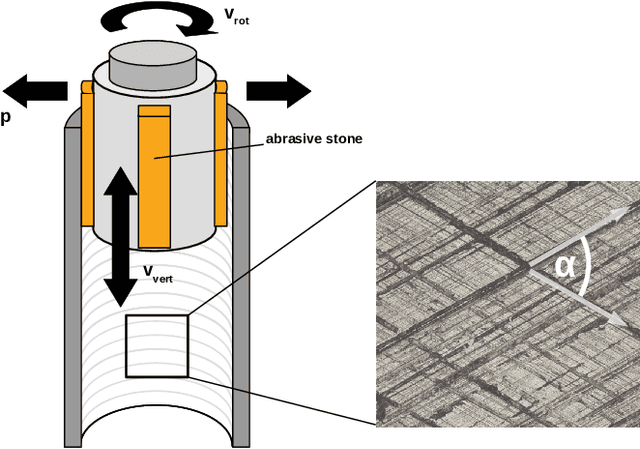
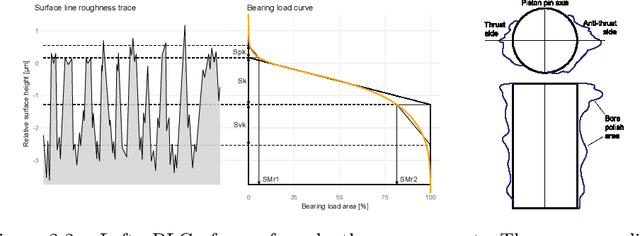

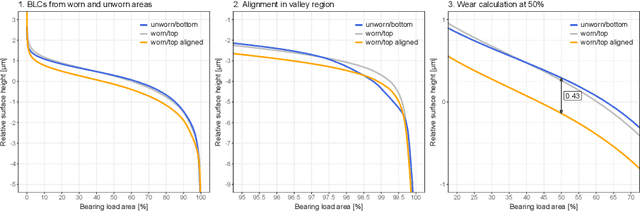
Digitalization offers a large number of promising tools for large internal combustion engines such as condition monitoring or condition-based maintenance. This includes the status evaluation of key engine components such as cylinder liners, whose inner surfaces are subject to constant wear due to their movement relative to the pistons. Existing state-of-the-art methods for quantifying wear require disassembly and cutting of the examined liner followed by a high-resolution microscopic surface depth measurement that quantitatively evaluates wear based on bearing load curves (also known as Abbott-Firestone curves). Such reference methods are destructive, time-consuming and costly. The goal of the research presented here is to develop simpler and nondestructive yet reliable and meaningful methods for evaluating wear condition. A deep-learning framework is proposed that allows computation of the surface-representing bearing load curves from reflection RGB images of the liner surface that can be collected with a simple handheld device, without the need to remove and destroy the investigated liner. For this purpose, a convolutional neural network is trained to estimate the bearing load curve of the corresponding depth profile, which in turn can be used for further wear evaluation. Training of the network is performed using a custom-built database containing depth profiles and reflection images of liner surfaces of large gas engines. The results of the proposed method are visually examined and quantified considering several probabilistic distance metrics and comparison of roughness indicators between ground truth and model predictions. The observed success of the proposed method suggests its great potential for quantitative wear assessment on engines and service directly on site.
PiNet: Deep Structure Learning using Feature Extraction in Trained Projection Space
Sep 01, 2020
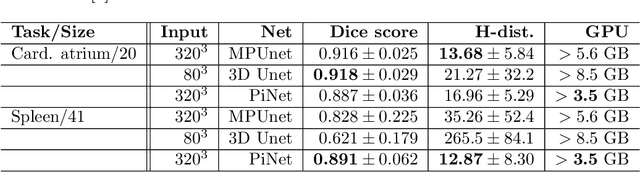
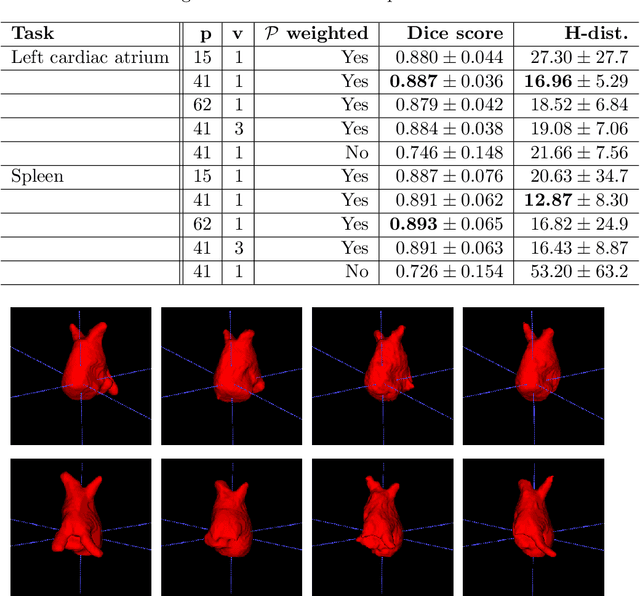
Over the last decade of machine learning, convolutional neural networks have been the most striking successes for feature extraction of rich sensory and high-dimensional data. While learning data representations via convolutions is already well studied and efficiently implemented in various deep learning libraries, one often faces limited memory capacity and an insufficient number of training data, especially for high-dimensional and large-scale tasks. To overcome these issues, we introduce a network architecture using a self-adjusting and data dependent version of the Radon-transform (projection data) to enable feature extraction via convolutions in lower-dimensional space. The resulting framework named PiNet can be trained end-to-end and shows promising performance on volumetric segmentation tasks. We also test our PiNet framework on public challenge datasets to show that our approach achieves comparable results only using a fractional amount of parameters and storage.
Random 2.5D U-net for Fully 3D Segmentation
Oct 23, 2019

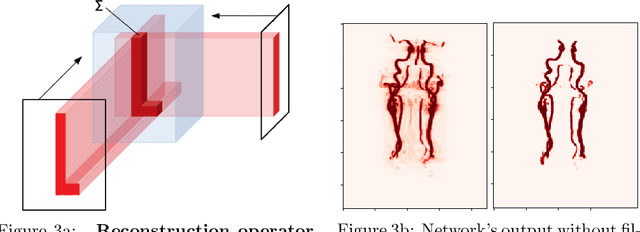
Convolutional neural networks are state-of-the-art for various segmentation tasks. While for 2D images these networks are also computationally efficient, 3D convolutions have huge storage requirements and therefore, end-to-end training is limited by GPU memory and data size. To overcome this issue, we introduce a network structure for volumetric data without 3D convolution layers. The main idea is to include projections from different directions to transform the volumetric data to a sequence of images, where each image contains information of the full data. We then apply 2D convolutions to these projection images and lift them again to volumetric data using a trainable reconstruction algorithm. The proposed architecture can be applied end-to-end to very large data volumes without cropping or sliding-window techniques. For a tested sparse binary segmentation task, it outperforms already known standard approaches and is more resistant to generation of artefacts.
Projection-Based 2.5D U-net Architecture for Fast Volumetric Segmentation
Feb 01, 2019
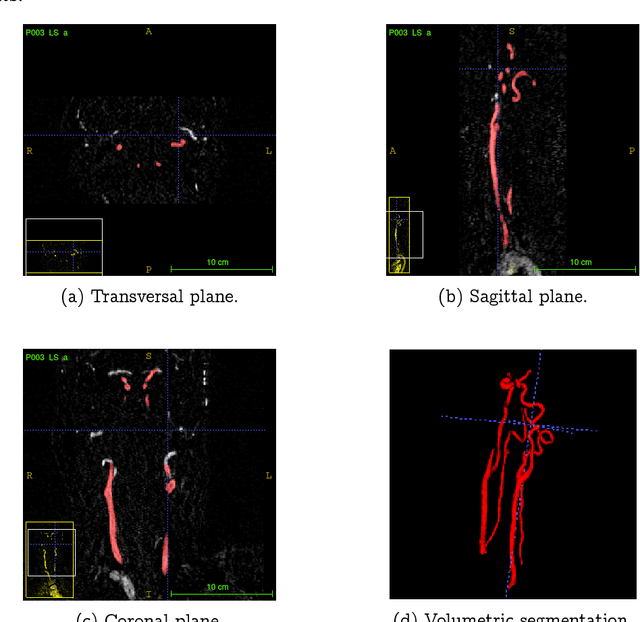
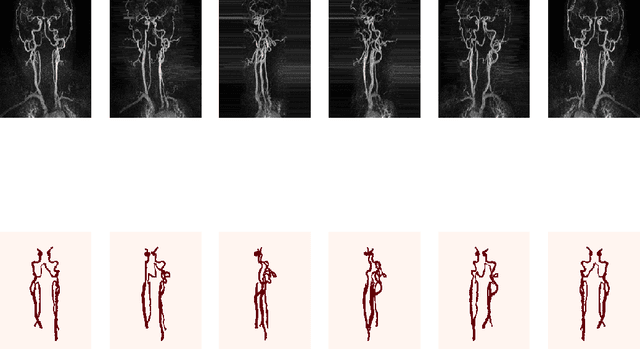
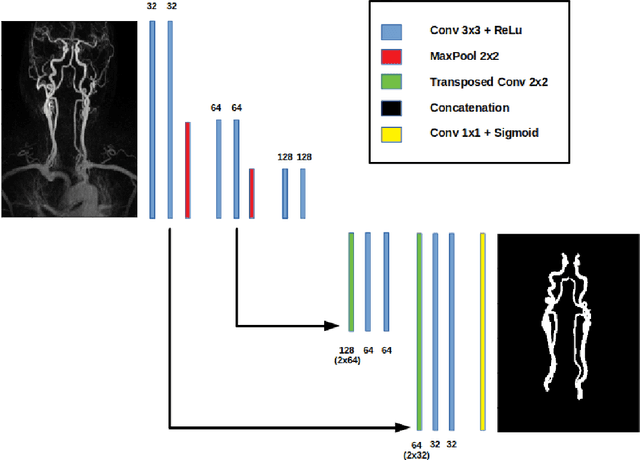
Convolutional neural networks are state-of-the-art for various segmentation tasks. While for 2D images these networks are also computationally efficient, 3D convolutions have huge storage requirements and require long training time. To overcome this issue, we introduce a network structure for volumetric data without 3D convolution layers. The main idea is to integrate projection layers to transform the volumetric data to a sequence of images, where each image contains information of the full data. We then apply 2D convolutions to the projection images followed by lifting to a volumetric data. The proposed network structure can be trained in much less time than any 3D-network and still shows accurate performance for a sparse binary segmentation task.