 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom 2.5D U-net for Fully 3D Segmentation
Paper and Code
Oct 23, 2019

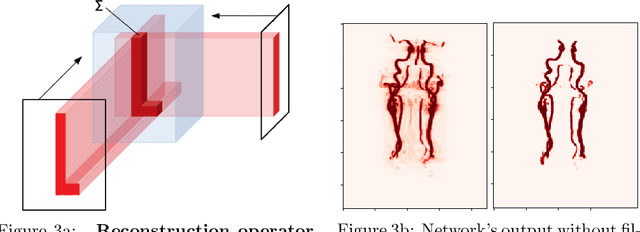
Convolutional neural networks are state-of-the-art for various segmentation tasks. While for 2D images these networks are also computationally efficient, 3D convolutions have huge storage requirements and therefore, end-to-end training is limited by GPU memory and data size. To overcome this issue, we introduce a network structure for volumetric data without 3D convolution layers. The main idea is to include projections from different directions to transform the volumetric data to a sequence of images, where each image contains information of the full data. We then apply 2D convolutions to these projection images and lift them again to volumetric data using a trainable reconstruction algorithm. The proposed architecture can be applied end-to-end to very large data volumes without cropping or sliding-window techniques. For a tested sparse binary segmentation task, it outperforms already known standard approaches and is more resistant to generation of artefacts.