 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePiNet: Deep Structure Learning using Feature Extraction in Trained Projection Space
Paper and Code

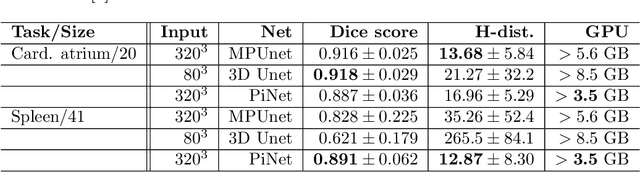
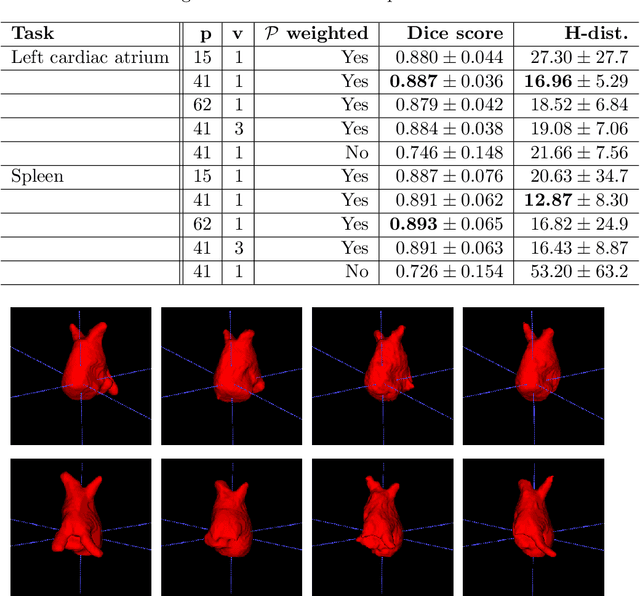
Over the last decade of machine learning, convolutional neural networks have been the most striking successes for feature extraction of rich sensory and high-dimensional data. While learning data representations via convolutions is already well studied and efficiently implemented in various deep learning libraries, one often faces limited memory capacity and an insufficient number of training data, especially for high-dimensional and large-scale tasks. To overcome these issues, we introduce a network architecture using a self-adjusting and data dependent version of the Radon-transform (projection data) to enable feature extraction via convolutions in lower-dimensional space. The resulting framework named PiNet can be trained end-to-end and shows promising performance on volumetric segmentation tasks. We also test our PiNet framework on public challenge datasets to show that our approach achieves comparable results only using a fractional amount of parameters and storage.