 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Representation Learning for Hand Shape Estimation
Jun 08, 2021



This work presents improvements in monocular hand shape estimation by building on top of recent advances in unsupervised learning. We extend momentum contrastive learning and contribute a structured collection of hand images, well suited for visual representation learning, which we call HanCo. We find that the representation learned by established contrastive learning methods can be improved significantly by exploiting advanced background removal techniques and multi-view information. These allow us to generate more diverse instance pairs than those obtained by augmentations commonly used in exemplar based approaches. Our method leads to a more suitable representation for the hand shape estimation task and shows a 4.7% reduction in mesh error and a 3.6% improvement in F-score compared to an ImageNet pretrained baseline. We make our benchmark dataset publicly available, to encourage further research into this direction.
FreiHAND: A Dataset for Markerless Capture of Hand Pose and Shape from Single RGB Images
Sep 13, 2019


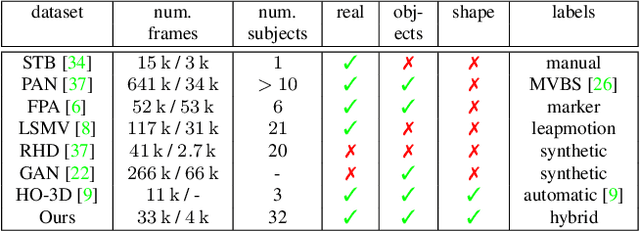
Estimating 3D hand pose from single RGB images is a highly ambiguous problem that relies on an unbiased training dataset. In this paper, we analyze cross-dataset generalization when training on existing datasets. We find that approaches perform well on the datasets they are trained on, but do not generalize to other datasets or in-the-wild scenarios. As a consequence, we introduce the first large-scale, multi-view hand dataset that is accompanied by both 3D hand pose and shape annotations. For annotating this real-world dataset, we propose an iterative, semi-automated `human-in-the-loop' approach, which includes hand fitting optimization to infer both the 3D pose and shape for each sample. We show that methods trained on our dataset consistently perform well when tested on other datasets. Moreover, the dataset allows us to train a network that predicts the full articulated hand shape from a single RGB image. The evaluation set can serve as a benchmark for articulated hand shape estimation.
3D Human Pose Estimation in RGBD Images for Robotic Task Learning
Mar 13, 2018



We propose an approach to estimate 3D human pose in real world units from a single RGBD image and show that it exceeds performance of monocular 3D pose estimation approaches from color as well as pose estimation exclusively from depth. Our approach builds on robust human keypoint detectors for color images and incorporates depth for lifting into 3D. We combine the system with our learning from demonstration framework to instruct a service robot without the need of markers. Experiments in real world settings demonstrate that our approach enables a PR2 robot to imitate manipulation actions observed from a human teacher.
Learning to Estimate 3D Hand Pose from Single RGB Images
Oct 15, 2017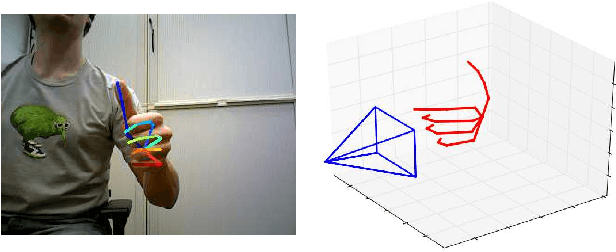

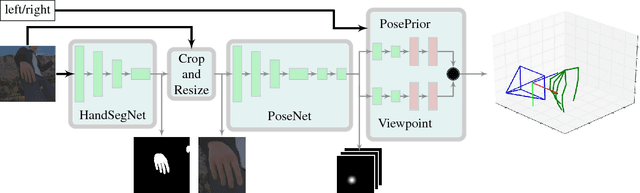

Low-cost consumer depth cameras and deep learning have enabled reasonable 3D hand pose estimation from single depth images. In this paper, we present an approach that estimates 3D hand pose from regular RGB images. This task has far more ambiguities due to the missing depth information. To this end, we propose a deep network that learns a network-implicit 3D articulation prior. Together with detected keypoints in the images, this network yields good estimates of the 3D pose. We introduce a large scale 3D hand pose dataset based on synthetic hand models for training the involved networks. Experiments on a variety of test sets, including one on sign language recognition, demonstrate the feasibility of 3D hand pose estimation on single color images.