 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Crowd Anomaly Detection: State-of-the-Art, Challenges, and Future Research Directions
Oct 25, 2022Crowd anomaly detection is one of the most popular topics in computer vision in the context of smart cities. A plethora of deep learning methods have been proposed that generally outperform other machine learning solutions. Our review primarily discusses algorithms that were published in mainstream conferences and journals between 2020 and 2022. We present datasets that are typically used for benchmarking, produce a taxonomy of the developed algorithms, and discuss and compare their performances. Our main findings are that the heterogeneities of pre-trained convolutional models have a negligible impact on crowd video anomaly detection performance. We conclude our discussion with fruitful directions for future research.
Symbolic Explanation of Affinity-Based Reinforcement Learning Agents with Markov Models
Aug 29, 2022
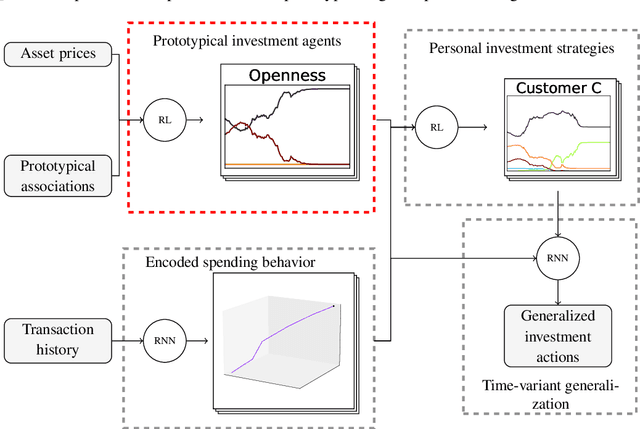


The proliferation of artificial intelligence is increasingly dependent on model understanding. Understanding demands both an interpretation - a human reasoning about a model's behavior - and an explanation - a symbolic representation of the functioning of the model. Notwithstanding the imperative of transparency for safety, trust, and acceptance, the opacity of state-of-the-art reinforcement learning algorithms conceals the rudiments of their learned strategies. We have developed a policy regularization method that asserts the global intrinsic affinities of learned strategies. These affinities provide a means of reasoning about a policy's behavior, thus making it inherently interpretable. We have demonstrated our method in personalized prosperity management where individuals' spending behavior in time dictate their investment strategies, i.e. distinct spending personalities may have dissimilar associations with different investment classes. We now explain our model by reproducing the underlying prototypical policies with discretized Markov models. These global surrogates are symbolic representations of the prototypical policies.
Towards Responsible AI for Financial Transactions
Jun 06, 2022
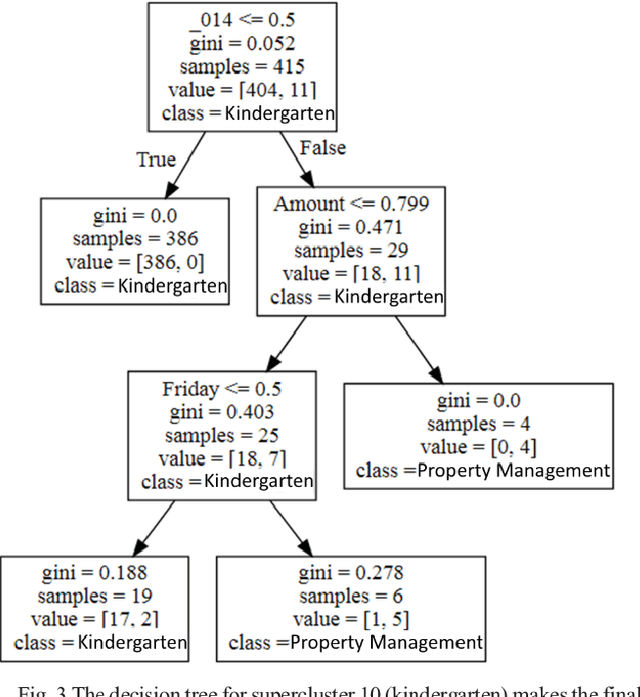
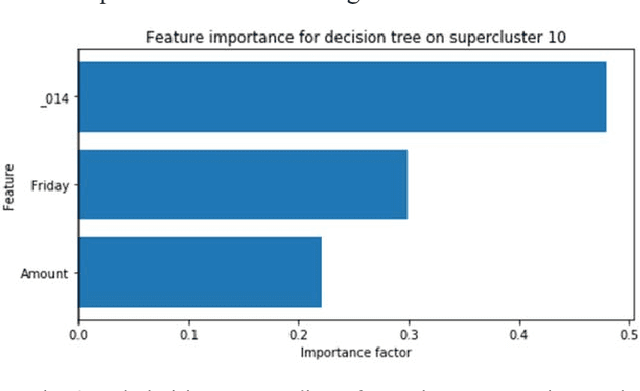
The application of AI in finance is increasingly dependent on the principles of responsible AI. These principles - explainability, fairness, privacy, accountability, transparency and soundness form the basis for trust in future AI systems. In this study, we address the first principle by providing an explanation for a deep neural network that is trained on a mixture of numerical, categorical and textual inputs for financial transaction classification. The explanation is achieved through (1) a feature importance analysis using Shapley additive explanations (SHAP) and (2) a hybrid approach of text clustering and decision tree classifiers. We then test the robustness of the model by exposing it to a targeted evasion attack, leveraging the knowledge we gained about the model through the extracted explanation.
Reinforcement Learning with Intrinsic Affinity for Personalized Asset Management
Apr 20, 2022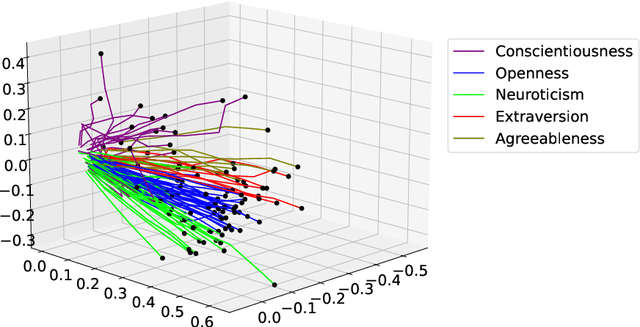
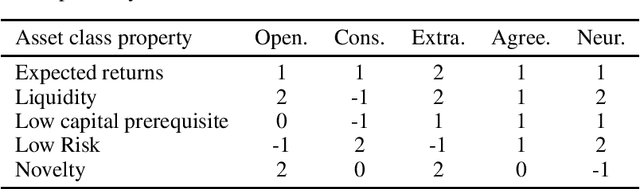
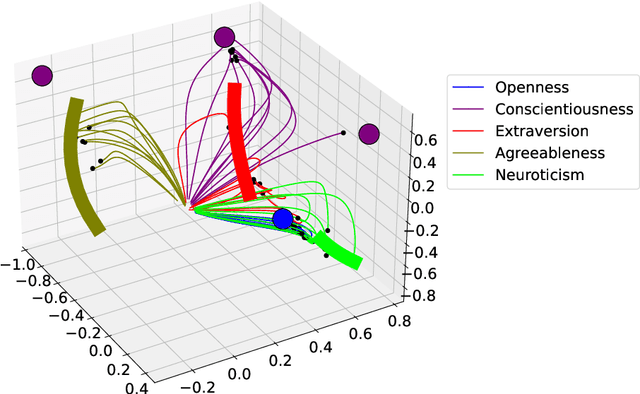
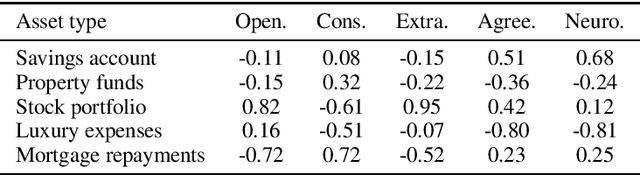
The common purpose of applying reinforcement learning (RL) to asset management is the maximization of profit. The extrinsic reward function used to learn an optimal strategy typically does not take into account any other preferences or constraints. We have developed a regularization method that ensures that strategies have global intrinsic affinities, i.e., different personalities may have preferences for certain assets which may change over time. We capitalize on these intrinsic policy affinities to make our RL model inherently interpretable. We demonstrate how RL agents can be trained to orchestrate such individual policies for particular personality profiles and still achieve high returns.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Oct 13, 2021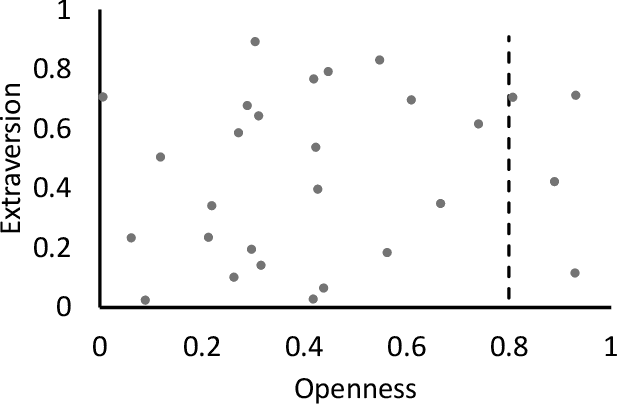
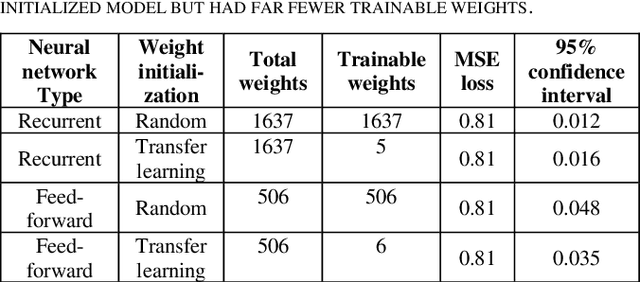
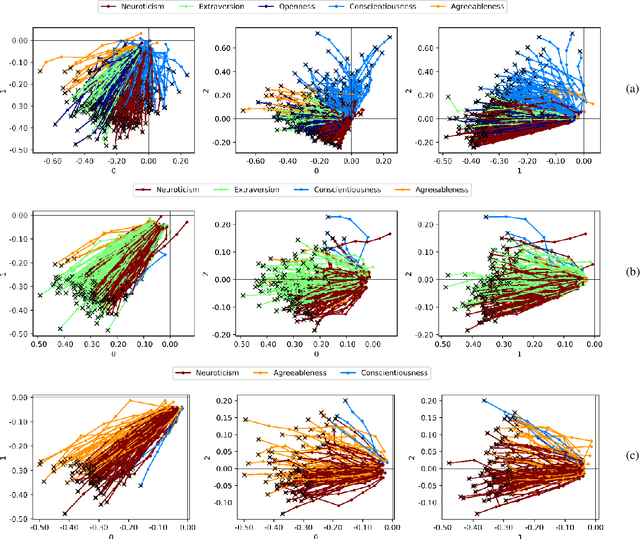
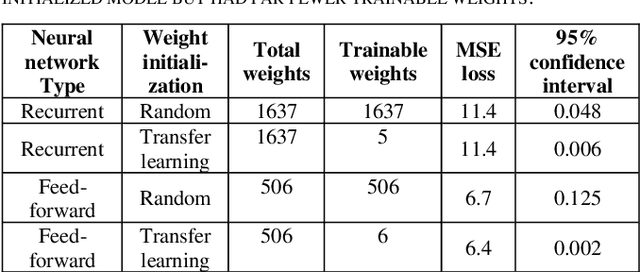
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In a novel approach, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only coarse segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
Discovering Novel Customer Features with Recurrent Neural Networks for Personality Based Financial Services
Sep 24, 2021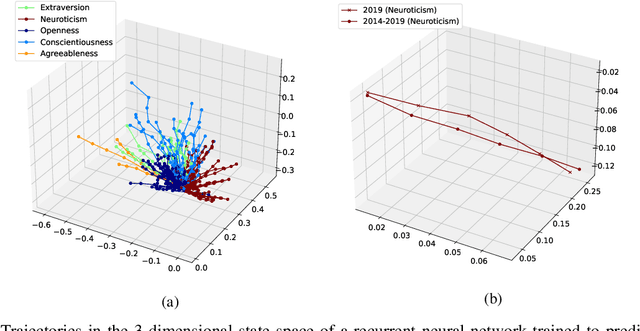
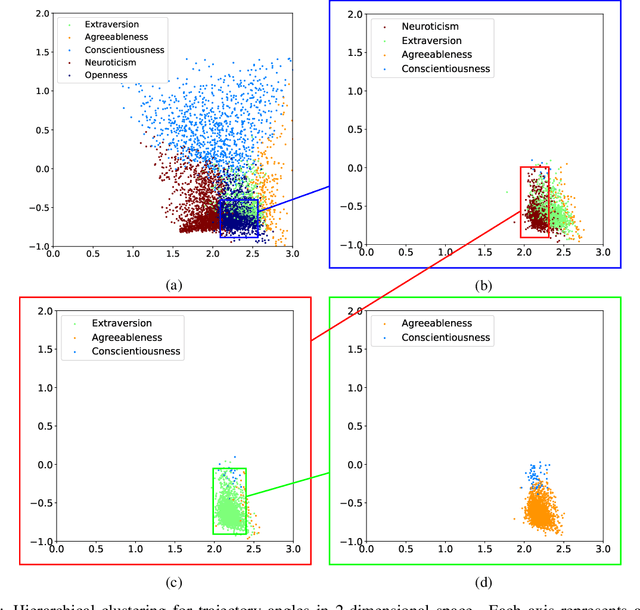

The micro-segmentation of customers in the finance sector is a non-trivial task and has been an atypical omission from recent scientific literature. Where traditional segmentation classifies customers based on coarse features such as demographics, micro-segmentation depicts more nuanced differences between individuals, bringing forth several advantages including the potential for improved personalization in financial services. AI and representation learning offer a unique opportunity to solve the problem of micro-segmentation. Although ubiquitous in many industries, the proliferation of AI in sensitive industries such as finance has become contingent on the imperatives of responsible AI. We had previously solved the micro-segmentation problem by extracting temporal features from the state space of a recurrent neural network (RNN). However, due to the inherent opacity of RNNs our solution lacked an explanation - one of the imperatives of responsible AI. In this study, we address this issue by extracting an explanation for and providing an interpretation of our temporal features. We investigate the state space of our RNN and through a linear regression model reconstruct the trajectories in the state space with high fidelity. We show that our linear regression coefficients have not only learned the rules used to create the RNN's output data but have also learned the relationships that were not directly evident in the raw data.
The Convolutional Tsetlin Machine
May 25, 2019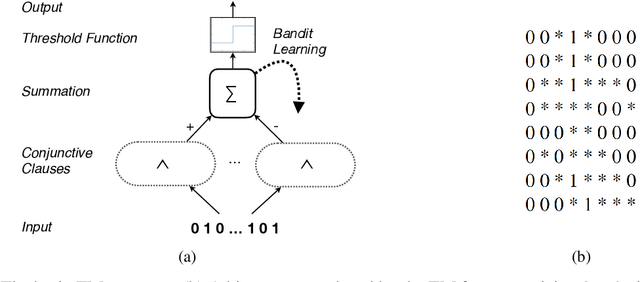
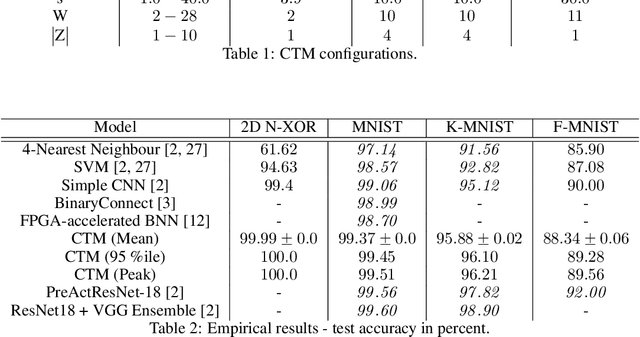
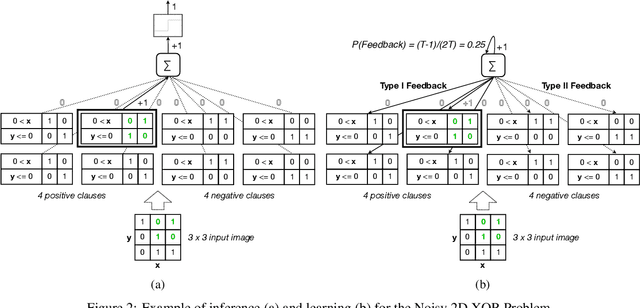
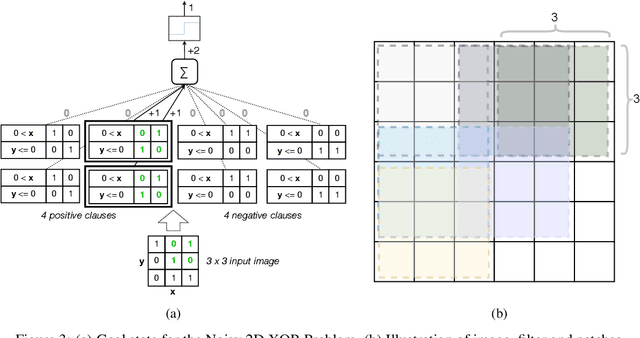
Deep neural networks have obtained astounding successes for important pattern recognition tasks, but they suffer from high computational complexity and the lack of interpretability. The recent Tsetlin Machine (TM) attempts to address this lack by using easy-to-interpret conjunctive clauses in propositional logic to solve complex pattern recognition problems. The TM provides competitive accuracy in several benchmarks, while keeping the important property of interpretability. It further facilitates hardware-near implementation since inputs, patterns, and outputs are expressed as bits, while recognition and learning rely on straightforward bit manipulation. In this paper, we exploit the TM paradigm by introducing the Convolutional Tsetlin Machine (CTM), as an interpretable alternative to convolutional neural networks (CNNs). Whereas the TM categorizes an image by employing each clause once to the whole image, the CTM uses each clause as a convolution filter. That is, a clause is evaluated multiple times, once per image patch taking part in the convolution. To make the clauses location-aware, each patch is further augmented with its coordinates within the image. The output of a convolution clause is obtained simply by ORing the outcome of evaluating the clause on each patch. In the learning phase of the TM, clauses that evaluate to 1 are contrasted against the input. For the CTM, we instead contrast against one of the patches, randomly selected among the patches that made the clause evaluate to 1. Accordingly, the standard Type I and Type II feedback of the classic TM can be employed directly, without further modification. The CTM obtains a peak test accuracy of 99.51% on MNIST, 96.21% on Kuzushiji-MNIST, 89.56% on Fashion-MNIST, and 100.0% on the 2D Noisy XOR Problem, which is competitive with results reported for simple 4-layer CNNs, BinaryConnect, and a recent FPGA-accelerated Binary CNN.