 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Artificial Virtuous Agents: Games, Dilemmas and Machine Learning
Aug 30, 2022
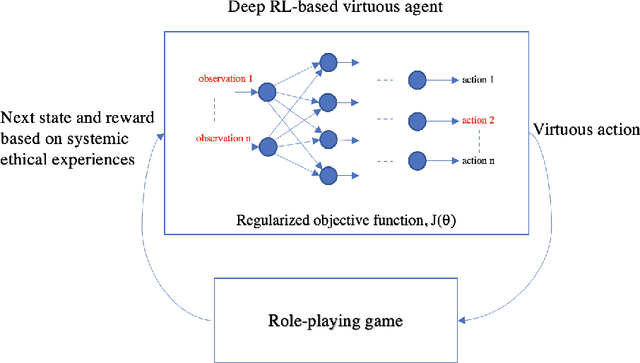
Machine ethics has received increasing attention over the past few years because of the need to ensure safe and reliable artificial intelligence (AI). The two dominantly used theories in machine ethics are deontological and utilitarian ethics. Virtue ethics, on the other hand, has often been mentioned as an alternative ethical theory. While this interesting approach has certain advantages over popular ethical theories, little effort has been put into engineering artificial virtuous agents due to challenges in their formalization, codifiability, and the resolution of ethical dilemmas to train virtuous agents. We propose to bridge this gap by using role-playing games riddled with moral dilemmas. There are several such games in existence, such as Papers, Please and Life is Strange, where the main character encounters situations where they must choose the right course of action by giving up something else dear to them. We draw inspiration from such games to show how a systemic role-playing game can be designed to develop virtues within an artificial agent. Using modern day AI techniques, such as affinity-based reinforcement learning and explainable AI, we motivate the implementation of virtuous agents that play such role-playing games, and the examination of their decisions through a virtue ethical lens. The development of such agents and environments is a first step towards practically formalizing and demonstrating the value of virtue ethics in the development of ethical agents.
Symbolic Explanation of Affinity-Based Reinforcement Learning Agents with Markov Models
Aug 29, 2022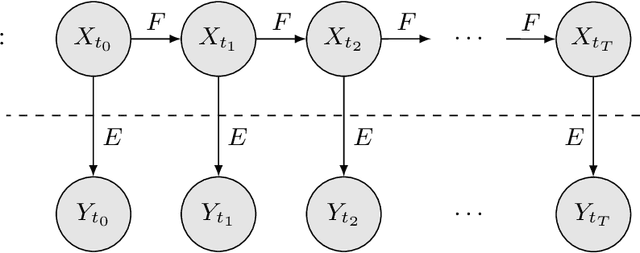
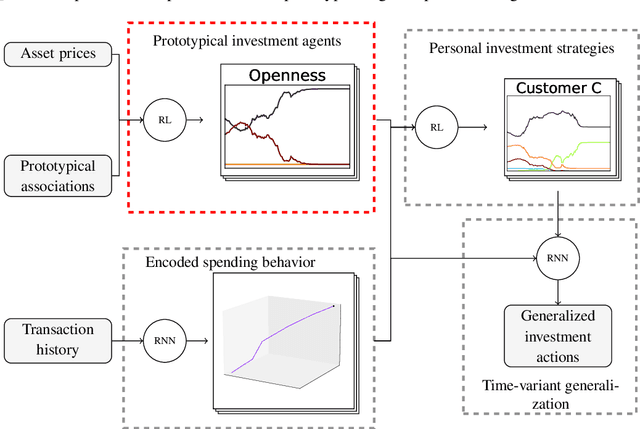


The proliferation of artificial intelligence is increasingly dependent on model understanding. Understanding demands both an interpretation - a human reasoning about a model's behavior - and an explanation - a symbolic representation of the functioning of the model. Notwithstanding the imperative of transparency for safety, trust, and acceptance, the opacity of state-of-the-art reinforcement learning algorithms conceals the rudiments of their learned strategies. We have developed a policy regularization method that asserts the global intrinsic affinities of learned strategies. These affinities provide a means of reasoning about a policy's behavior, thus making it inherently interpretable. We have demonstrated our method in personalized prosperity management where individuals' spending behavior in time dictate their investment strategies, i.e. distinct spending personalities may have dissimilar associations with different investment classes. We now explain our model by reproducing the underlying prototypical policies with discretized Markov models. These global surrogates are symbolic representations of the prototypical policies.
Towards Responsible AI for Financial Transactions
Jun 06, 2022
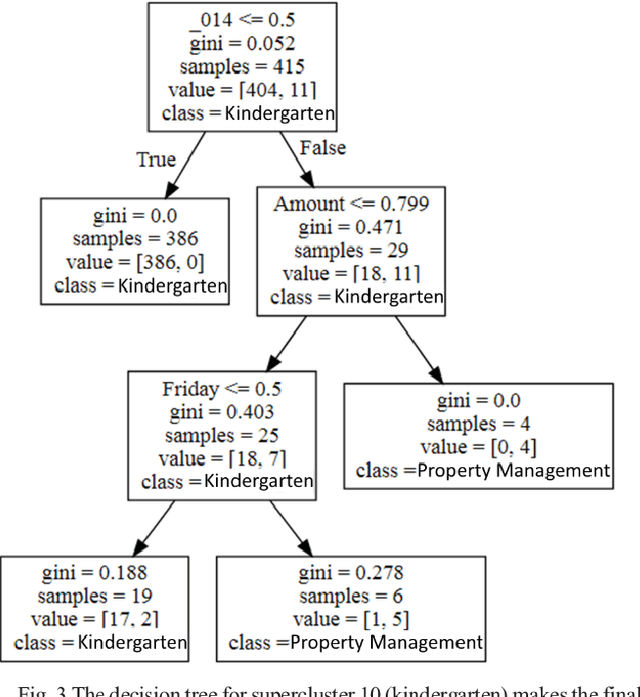
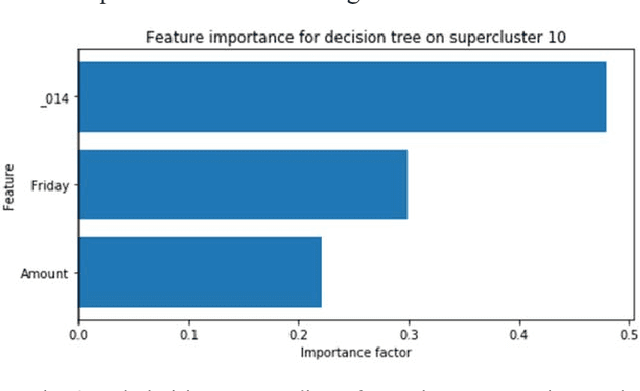
The application of AI in finance is increasingly dependent on the principles of responsible AI. These principles - explainability, fairness, privacy, accountability, transparency and soundness form the basis for trust in future AI systems. In this study, we address the first principle by providing an explanation for a deep neural network that is trained on a mixture of numerical, categorical and textual inputs for financial transaction classification. The explanation is achieved through (1) a feature importance analysis using Shapley additive explanations (SHAP) and (2) a hybrid approach of text clustering and decision tree classifiers. We then test the robustness of the model by exposing it to a targeted evasion attack, leveraging the knowledge we gained about the model through the extracted explanation.
Reinforcement Learning with Intrinsic Affinity for Personalized Asset Management
Apr 20, 2022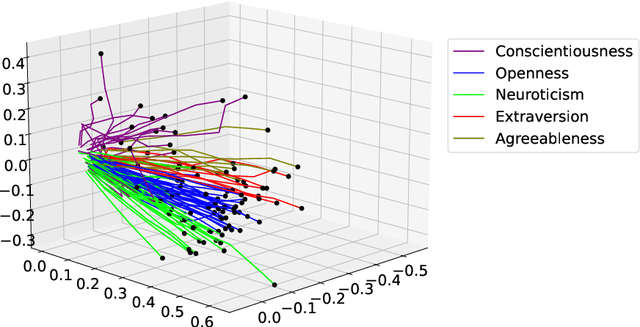
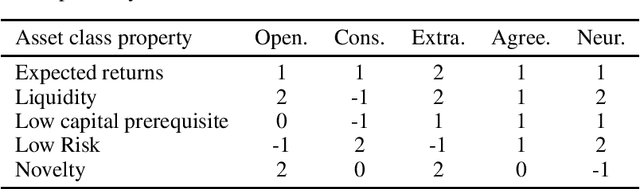
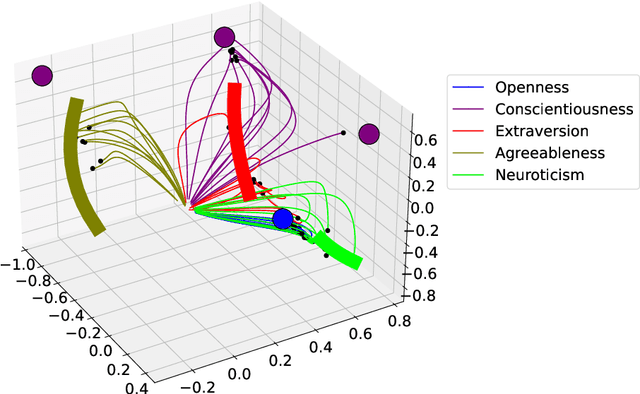
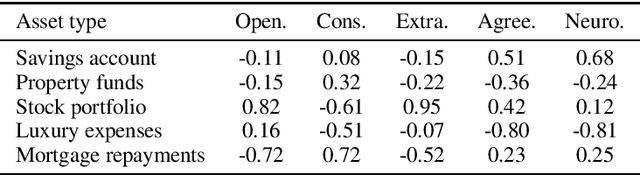
The common purpose of applying reinforcement learning (RL) to asset management is the maximization of profit. The extrinsic reward function used to learn an optimal strategy typically does not take into account any other preferences or constraints. We have developed a regularization method that ensures that strategies have global intrinsic affinities, i.e., different personalities may have preferences for certain assets which may change over time. We capitalize on these intrinsic policy affinities to make our RL model inherently interpretable. We demonstrate how RL agents can be trained to orchestrate such individual policies for particular personality profiles and still achieve high returns.
Can Interpretable Reinforcement Learning Manage Assets Your Way?
Feb 18, 2022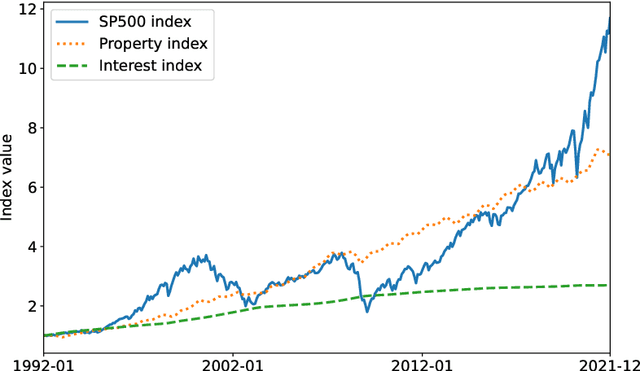

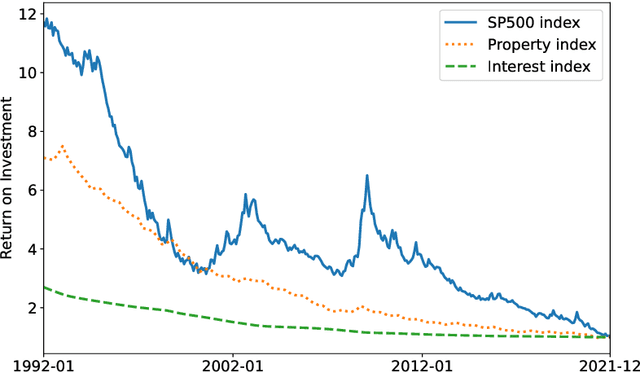
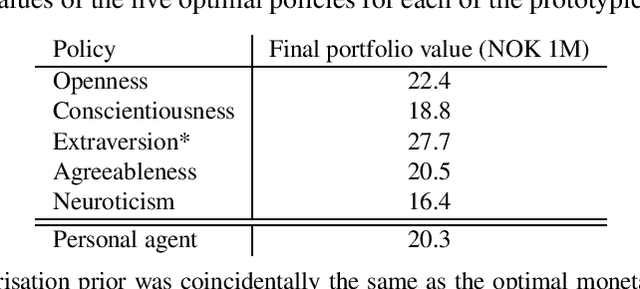
Personalisation of products and services is fast becoming the driver of success in banking and commerce. Machine learning holds the promise of gaining a deeper understanding of and tailoring to customers' needs and preferences. Whereas traditional solutions to financial decision problems frequently rely on model assumptions, reinforcement learning is able to exploit large amounts of data to improve customer modelling and decision-making in complex financial environments with fewer assumptions. Model explainability and interpretability present challenges from a regulatory perspective which demands transparency for acceptance; they also offer the opportunity for improved insight into and understanding of customers. Post-hoc approaches are typically used for explaining pretrained reinforcement learning models. Based on our previous modeling of customer spending behaviour, we adapt our recent reinforcement learning algorithm that intrinsically characterizes desirable behaviours and we transition to the problem of asset management. We train inherently interpretable reinforcement learning agents to give investment advice that is aligned with prototype financial personality traits which are combined to make a final recommendation. We observe that the trained agents' advice adheres to their intended characteristics, they learn the value of compound growth, and, without any explicit reference, the notion of risk as well as improved policy convergence.
Reinforcement Learning Your Way: Agent Characterization through Policy Regularization
Jan 21, 2022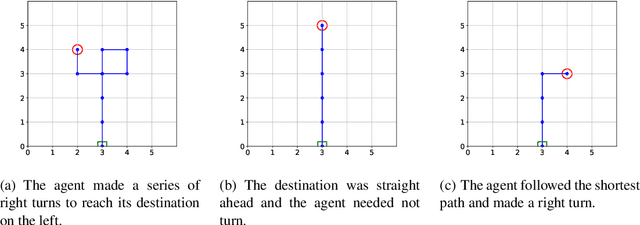
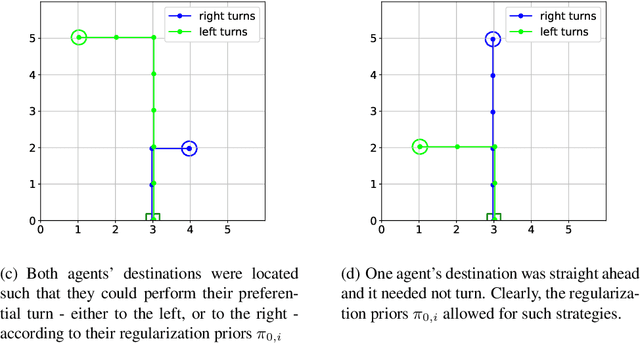
The increased complexity of state-of-the-art reinforcement learning (RL) algorithms have resulted in an opacity that inhibits explainability and understanding. This has led to the development of several post-hoc explainability methods that aim to extract information from learned policies thus aiding explainability. These methods rely on empirical observations of the policy and thus aim to generalize a characterization of agents' behaviour. In this study, we have instead developed a method to imbue a characteristic behaviour into agents' policies through regularization of their objective functions. Our method guides the agents' behaviour during learning which results in an intrinsic characterization; it connects the learning process with model explanation. We provide a formal argument and empirical evidence for the viability of our method. In future work, we intend to employ it to develop agents that optimize individual financial customers' investment portfolios based on their spending personalities.
Clustering in Recurrent Neural Networks for Micro-Segmentation using Spending Personality
Oct 13, 2021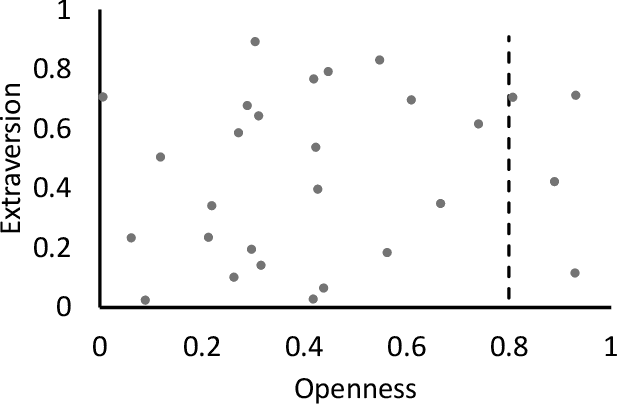
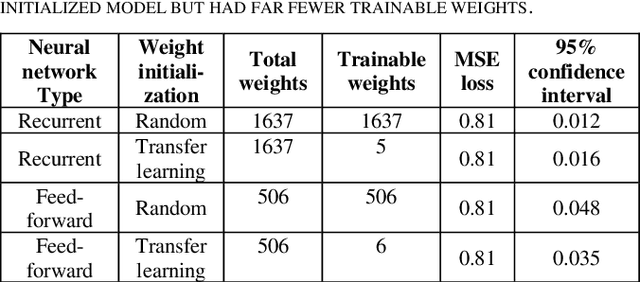
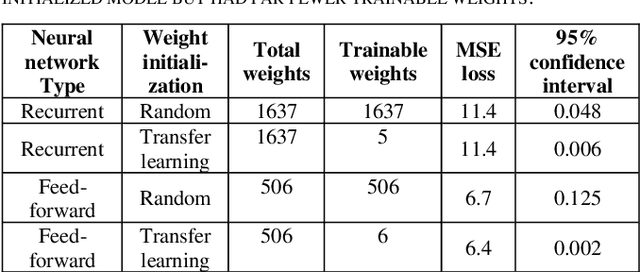
Customer segmentation has long been a productive field in banking. However, with new approaches to traditional problems come new opportunities. Fine-grained customer segments are notoriously elusive and one method of obtaining them is through feature extraction. It is possible to assign coefficients of standard personality traits to financial transaction classes aggregated over time. However, we have found that the clusters formed are not sufficiently discriminatory for micro-segmentation. In a novel approach, we extract temporal features with continuous values from the hidden states of neural networks predicting customers' spending personality from their financial transactions. We consider both temporal and non-sequential models, using long short-term memory (LSTM) and feed-forward neural networks, respectively. We found that recurrent neural networks produce micro-segments where feed-forward networks produce only coarse segments. Finally, we show that classification using these extracted features performs at least as well as bespoke models on two common metrics, namely loan default rate and customer liquidity index.
Discovering Novel Customer Features with Recurrent Neural Networks for Personality Based Financial Services
Sep 24, 2021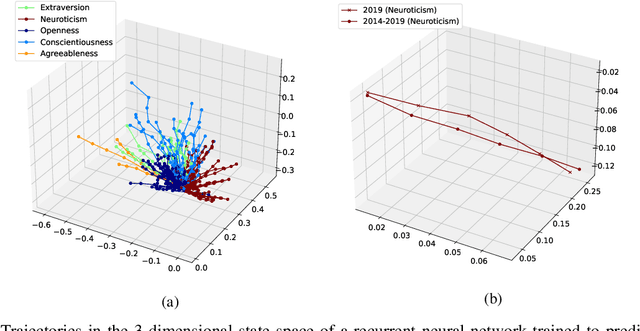
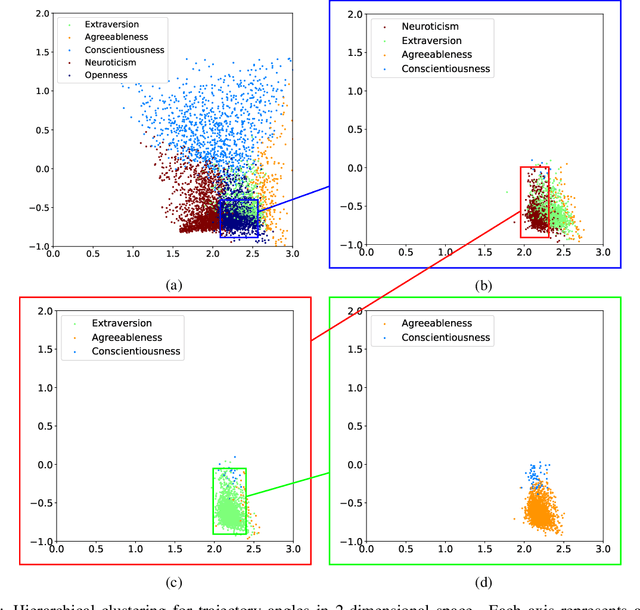

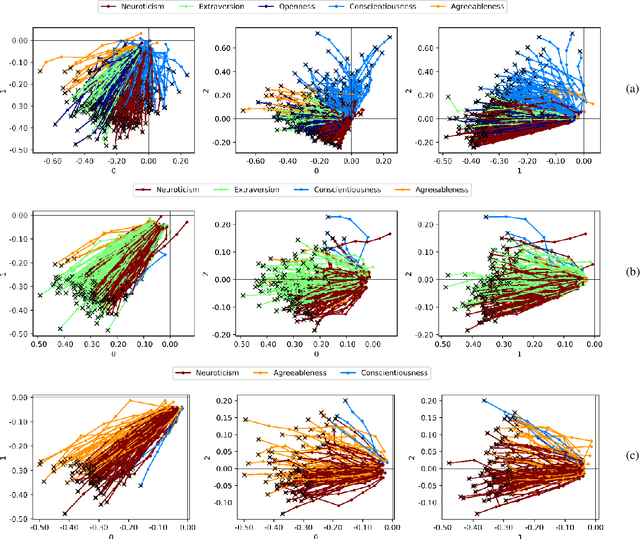
The micro-segmentation of customers in the finance sector is a non-trivial task and has been an atypical omission from recent scientific literature. Where traditional segmentation classifies customers based on coarse features such as demographics, micro-segmentation depicts more nuanced differences between individuals, bringing forth several advantages including the potential for improved personalization in financial services. AI and representation learning offer a unique opportunity to solve the problem of micro-segmentation. Although ubiquitous in many industries, the proliferation of AI in sensitive industries such as finance has become contingent on the imperatives of responsible AI. We had previously solved the micro-segmentation problem by extracting temporal features from the state space of a recurrent neural network (RNN). However, due to the inherent opacity of RNNs our solution lacked an explanation - one of the imperatives of responsible AI. In this study, we address this issue by extracting an explanation for and providing an interpretation of our temporal features. We investigate the state space of our RNN and through a linear regression model reconstruct the trajectories in the state space with high fidelity. We show that our linear regression coefficients have not only learned the rules used to create the RNN's output data but have also learned the relationships that were not directly evident in the raw data.