 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning Your Way: Agent Characterization through Policy Regularization
Paper and Code
Jan 21, 2022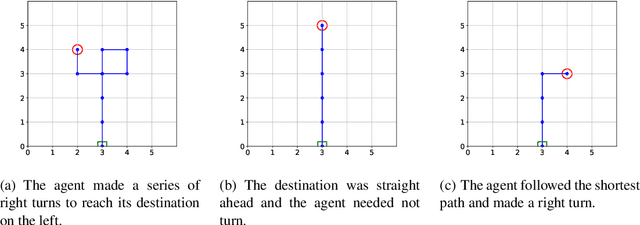
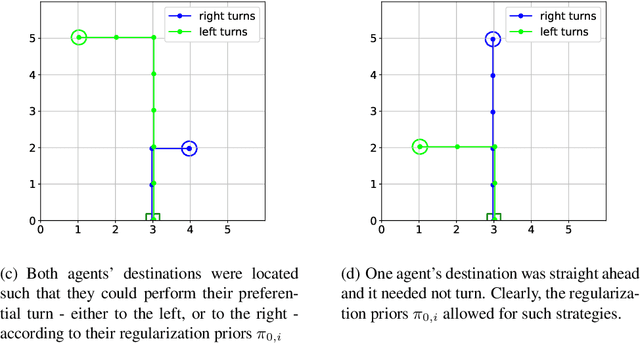
The increased complexity of state-of-the-art reinforcement learning (RL) algorithms have resulted in an opacity that inhibits explainability and understanding. This has led to the development of several post-hoc explainability methods that aim to extract information from learned policies thus aiding explainability. These methods rely on empirical observations of the policy and thus aim to generalize a characterization of agents' behaviour. In this study, we have instead developed a method to imbue a characteristic behaviour into agents' policies through regularization of their objective functions. Our method guides the agents' behaviour during learning which results in an intrinsic characterization; it connects the learning process with model explanation. We provide a formal argument and empirical evidence for the viability of our method. In future work, we intend to employ it to develop agents that optimize individual financial customers' investment portfolios based on their spending personalities.