 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Automated COVID-19 Grading with Convolutional Neural Networks in Computed Tomography Scans: An Ablation Study
Sep 21, 2020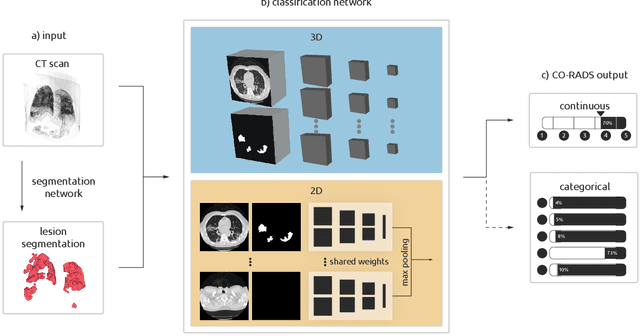
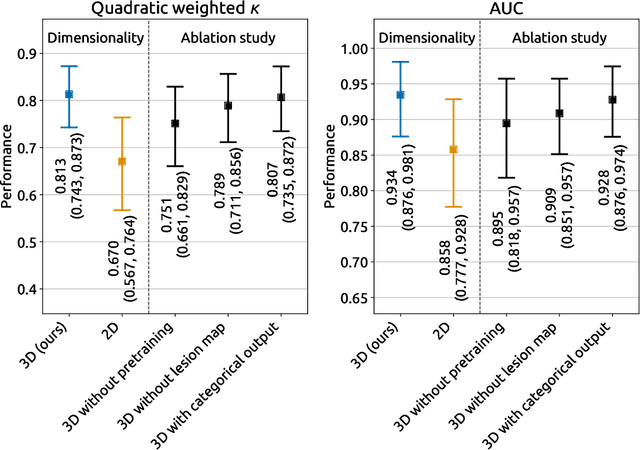
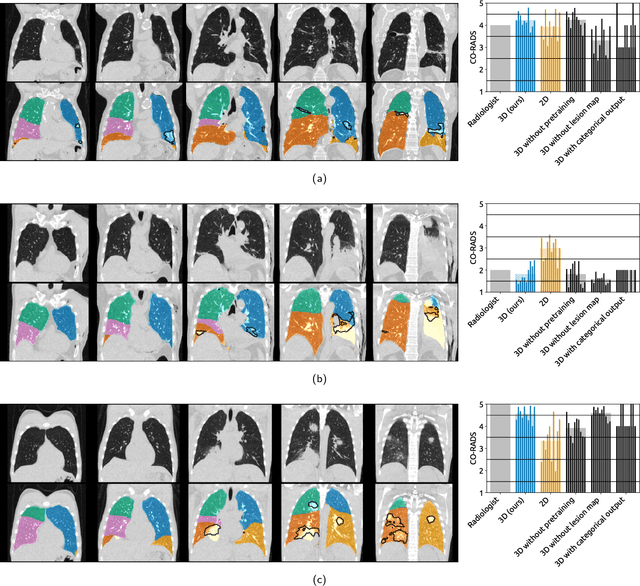
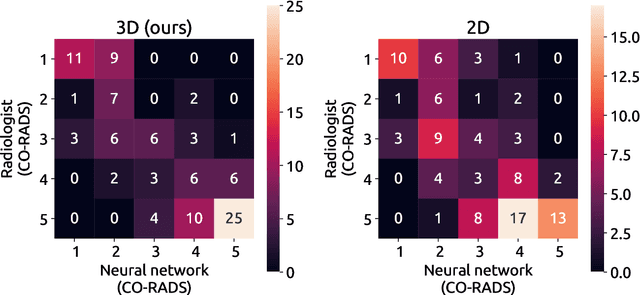
Amidst the ongoing pandemic, several studies have shown that COVID-19 classification and grading using computed tomography (CT) images can be automated with convolutional neural networks (CNNs). Many of these studies focused on reporting initial results of algorithms that were assembled from commonly used components. The choice of these components was often pragmatic rather than systematic. For instance, several studies used 2D CNNs even though these might not be optimal for handling 3D CT volumes. This paper identifies a variety of components that increase the performance of CNN-based algorithms for COVID-19 grading from CT images. We investigated the effectiveness of using a 3D CNN instead of a 2D CNN, of using transfer learning to initialize the network, of providing automatically computed lesion maps as additional network input, and of predicting a continuous instead of a categorical output. A 3D CNN with these components achieved an area under the ROC curve (AUC) of 0.934 on our test set of 105 CT scans and an AUC of 0.923 on a publicly available set of 742 CT scans, a substantial improvement in comparison with a previously published 2D CNN. An ablation study demonstrated that in addition to using a 3D CNN instead of a 2D CNN transfer learning contributed the most and continuous output contributed the least to improving the model performance.
3D medical image segmentation with labeled and unlabeled data using autoencoders at the example of liver segmentation in CT images
Mar 17, 2020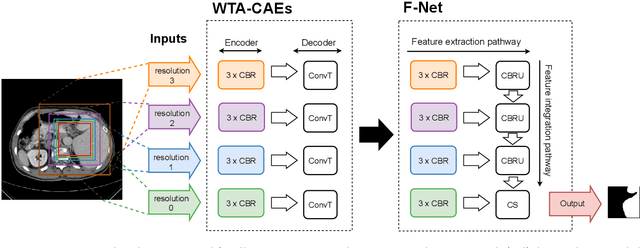
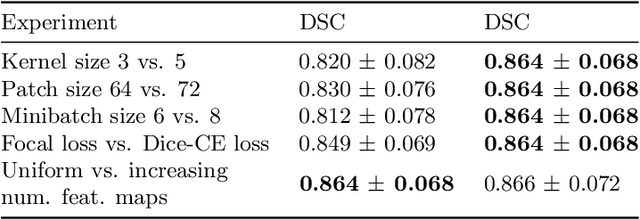

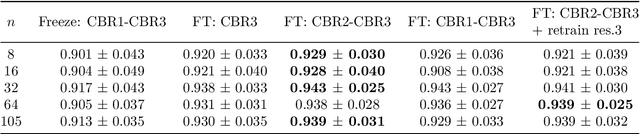
Automatic segmentation of anatomical structures with convolutional neural networks (CNNs) constitutes a large portion of research in medical image analysis. The majority of CNN-based methods rely on an abundance of labeled data for proper training. Labeled medical data is often scarce, but unlabeled data is more widely available. This necessitates approaches that go beyond traditional supervised learning and leverage unlabeled data for segmentation tasks. This work investigates the potential of autoencoder-extracted features to improve segmentation with a CNN. Two strategies were considered. First, transfer learning where pretrained autoencoder features were used as initialization for the convolutional layers in the segmentation network. Second, multi-task learning where the tasks of segmentation and feature extraction, by means of input reconstruction, were learned and optimized simultaneously. A convolutional autoencoder was used to extract features from unlabeled data and a multi-scale, fully convolutional CNN was used to perform the target task of 3D liver segmentation in CT images. For both strategies, experiments were conducted with varying amounts of labeled and unlabeled training data. The proposed learning strategies improved results in $75\%$ of the experiments compared to training from scratch and increased the dice score by up to $0.040$ and $0.024$ for a ratio of unlabeled to labeled training data of about $32 : 1$ and $12.5 : 1$, respectively. The results indicate that both training strategies are more effective with a large ratio of unlabeled to labeled training data.