 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFirst Place Solution of KDD Cup 2021 & OGB Large-Scale Challenge Graph Prediction Track
Jun 20, 2021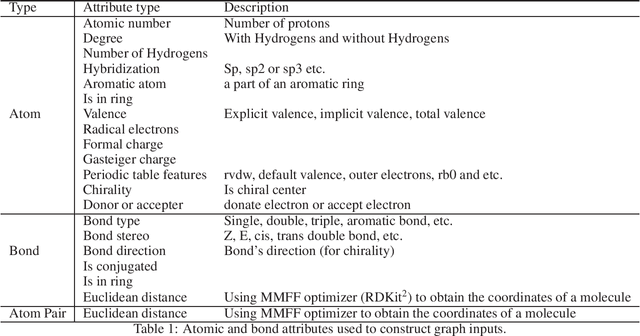

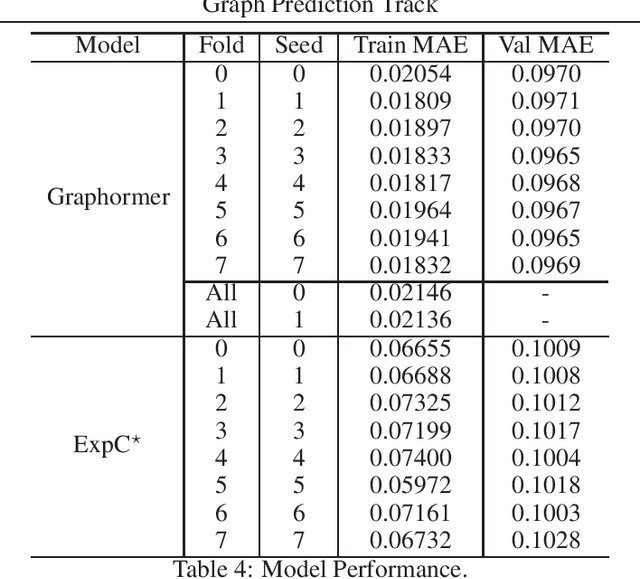
In this technical report, we present our solution of KDD Cup 2021 OGB Large-Scale Challenge - PCQM4M-LSC Track. We adopt Graphormer and ExpC as our basic models. We train each model by 8-fold cross-validation, and additionally train two Graphormer models on the union of training and validation sets with different random seeds. For final submission, we use a naive ensemble for these 18 models by taking average of their outputs. Using our method, our team MachineLearning achieved 0.1200 MAE on test set, which won the first place in KDD Cup graph prediction track.
Do Transformers Really Perform Bad for Graph Representation?
Jun 17, 2021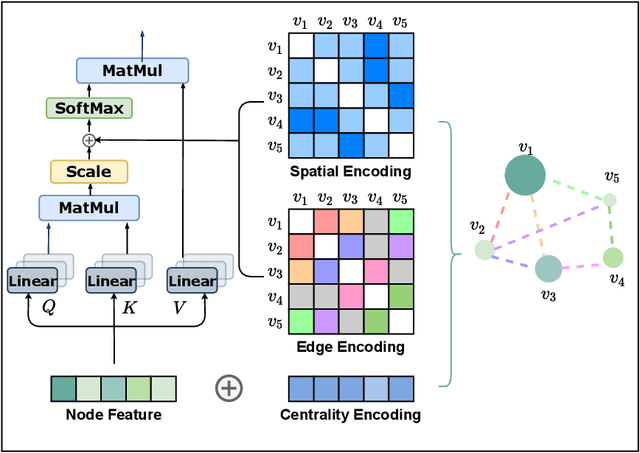
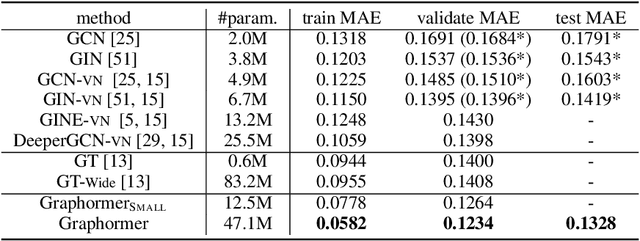

The Transformer architecture has become a dominant choice in many domains, such as natural language processing and computer vision. Yet, it has not achieved competitive performance on popular leaderboards of graph-level prediction compared to mainstream GNN variants. Therefore, it remains a mystery how Transformers could perform well for graph representation learning. In this paper, we solve this mystery by presenting Graphormer, which is built upon the standard Transformer architecture, and could attain excellent results on a broad range of graph representation learning tasks, especially on the recent OGB Large-Scale Challenge. Our key insight to utilizing Transformer in the graph is the necessity of effectively encoding the structural information of a graph into the model. To this end, we propose several simple yet effective structural encoding methods to help Graphormer better model graph-structured data. Besides, we mathematically characterize the expressive power of Graphormer and exhibit that with our ways of encoding the structural information of graphs, many popular GNN variants could be covered as the special cases of Graphormer.
LazyFormer: Self Attention with Lazy Update
Feb 25, 2021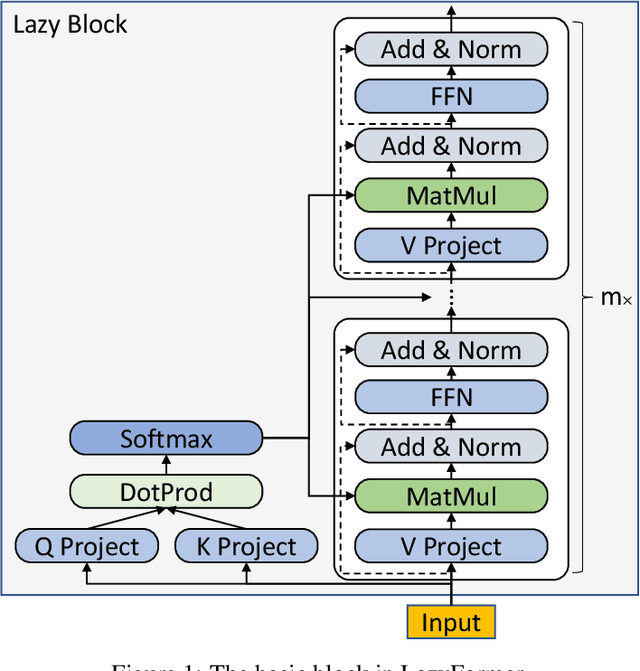


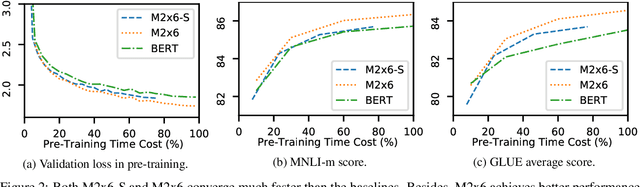
Improving the efficiency of Transformer-based language pre-training is an important task in NLP, especially for the self-attention module, which is computationally expensive. In this paper, we propose a simple but effective solution, called \emph{LazyFormer}, which computes the self-attention distribution infrequently. LazyFormer composes of multiple lazy blocks, each of which contains multiple Transformer layers. In each lazy block, the self-attention distribution is only computed once in the first layer and then is reused in all upper layers. In this way, the cost of computation could be largely saved. We also provide several training tricks for LazyFormer. Extensive experiments demonstrate the effectiveness of the proposed method.