Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazyFormer: Self Attention with Lazy Update
Paper and Code
Feb 25, 2021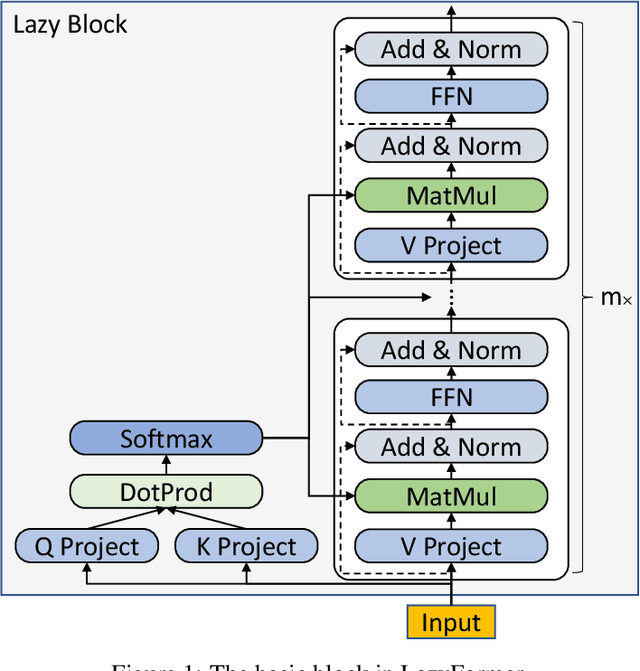


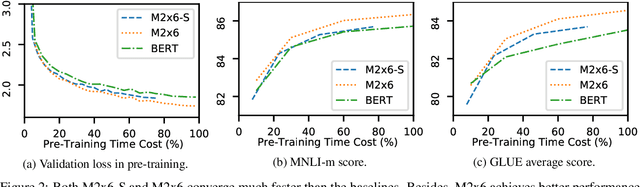
Improving the efficiency of Transformer-based language pre-training is an important task in NLP, especially for the self-attention module, which is computationally expensive. In this paper, we propose a simple but effective solution, called \emph{LazyFormer}, which computes the self-attention distribution infrequently. LazyFormer composes of multiple lazy blocks, each of which contains multiple Transformer layers. In each lazy block, the self-attention distribution is only computed once in the first layer and then is reused in all upper layers. In this way, the cost of computation could be largely saved. We also provide several training tricks for LazyFormer. Extensive experiments demonstrate the effectiveness of the proposed method.
View paper on