 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Vision-Language Models Handle Long-Context Code? An Empirical Study on Visual Compression
Jan 31, 2026Large Language Models (LLMs) struggle with long-context code due to window limitations. Existing textual code compression methods mitigate this via selective filtering but often disrupt dependency closure, causing semantic fragmentation. To address this, we introduce LongCodeOCR, a visual compression framework that renders code into compressed two-dimensional image sequences for Vision-Language Models (VLMs). By preserving a global view, this approach avoids the dependency breakage inherent in filtering. We systematically evaluate LongCodeOCR against the state-of-the-art LongCodeZip across four benchmarks spanning code summarization, code question answering, and code completion. Our results demonstrate that visual code compression serves as a viable alternative for tasks requiring global understanding. At comparable compression ratios ($\sim$1.7$\times$), LongCodeOCR improves CompScore on Long Module Summarization by 36.85 points over LongCodeZip. At a 1M-token context length with Glyph (a specialized 9B VLM), LongCodeOCR maintains higher accuracy than LongCodeZip while operating at about 4$\times$ higher compression. Moreover, compared with LongCodeZip, LongCodeOCR drastically reduces compression-stage overhead (reducing latency from $\sim$4.3 hours to $\sim$1 minute at 1M tokens). Finally, our results characterize a fundamental coverage--fidelity trade-off: visual code compression retains broader context coverage to support global dependencies, yet faces fidelity bottlenecks on exactness-critical tasks; by contrast, textual code compression preserves symbol-level precision while sacrificing structural coverage.
Resisting Backdoor Attacks in Federated Learning via Bidirectional Elections and Individual Perspective
Sep 28, 2023
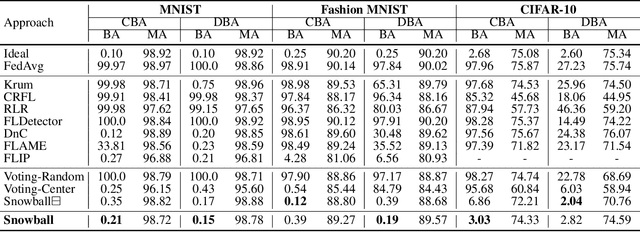
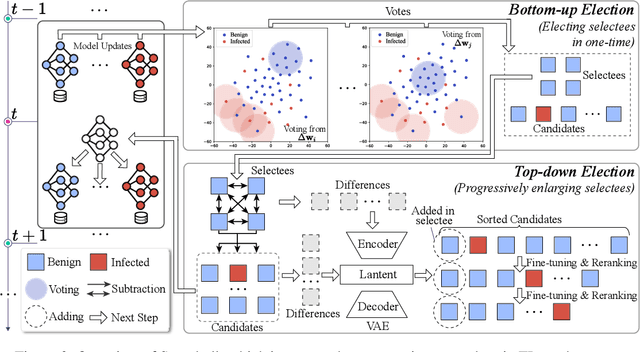
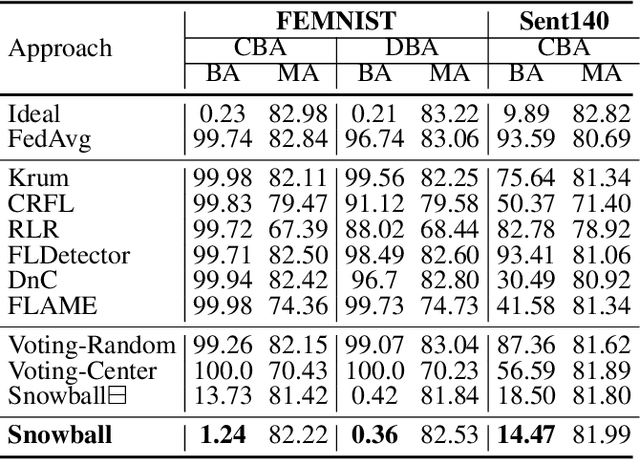
Existing approaches defend against backdoor attacks in federated learning (FL) mainly through a) mitigating the impact of infected models, or b) excluding infected models. The former negatively impacts model accuracy, while the latter usually relies on globally clear boundaries between benign and infected model updates. However, model updates are easy to be mixed and scattered throughout in reality due to the diverse distributions of local data. This work focuses on excluding infected models in FL. Unlike previous perspectives from a global view, we propose Snowball, a novel anti-backdoor FL framework through bidirectional elections from an individual perspective inspired by one principle deduced by us and two principles in FL and deep learning. It is characterized by a) bottom-up election, where each candidate model update votes to several peer ones such that a few model updates are elected as selectees for aggregation; and b) top-down election, where selectees progressively enlarge themselves through picking up from the candidates. We compare Snowball with state-of-the-art defenses to backdoor attacks in FL on five real-world datasets, demonstrating its superior resistance to backdoor attacks and slight impact on the accuracy of the global model.