 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Federated Learning for Unsupervised Waveform Classification over Tactical MANETs
Jun 08, 2026Distributed radio frequency sensing in contested tactical environments demands collaborative learning across mobile nodes. In ad-hoc networks, learning must occur without persistent backhaul, ground truth labels, or reliable communication links. Traditional federated learning approaches assume either ideal link conditions or supervised training objectives, neither of which holds in practice for deployed MANET platforms. This paper presents a hierarchical federated learning framework for unsupervised waveform classification over tactical MANETs subject to Rayleigh fading, random waypoint mobility, and multi-hop routing loss. Each node trains a local denoising convolutional autoencoder on raw IQ observations without label exchange, learning compact representations through a self-supervised reconstruction objective. A two-stage aggregation protocol elects connectivity-based relay aggregators consistent with OLSR multipoint relay selection, compressing cluster-level model updates before forwarding to a mobile server proxy. Simulation results demonstrate that in-network aggregation reduces attempted transmission bits relative to relay-forward federated averaging by around 12% at equivalent classification performance. Notably, stochastic channel-driven subsampling under non-IID data acts as an implicit regularizer, with both MANET conditions matching or exceeding ideal federated averaging on unsupervised representation quality. This suggests that moderate link loss can partially compensate for client drift in heterogeneous networks. Performance is assessed on analysis of the learned latent embeddings using KMeans normalized mutual information and linear probe accuracy.
Temporal Convolutional Autoencoder for Interference Mitigation in FMCW Radar Altimeters
May 28, 2025



We investigate the end-to-end altitude estimation performance of a convolutional autoencoder-based interference mitigation approach for frequency-modulated continuous-wave (FMCW) radar altimeters. Specifically, we show that a Temporal Convolutional Network (TCN) autoencoder effectively exploits temporal correlations in the received signal, providing superior interference suppression compared to a Least Mean Squares (LMS) adaptive filter. Unlike existing approaches, the present method operates directly on the received FMCW signal. Additionally, we identify key challenges in applying deep learning to wideband FMCW interference mitigation and outline directions for future research to enhance real-time feasibility and generalization to arbitrary interference conditions.
Aircraft Radar Altimeter Interference Mitigation Through a CNN-Layer Only Denoising Autoencoder Architecture
Oct 04, 2024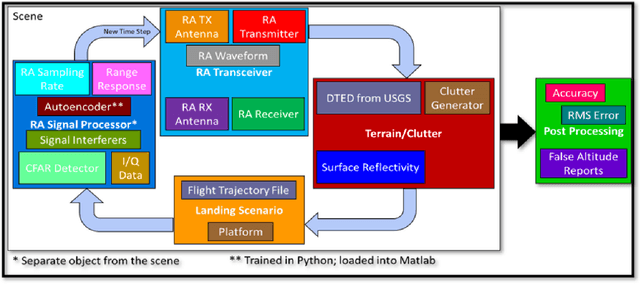
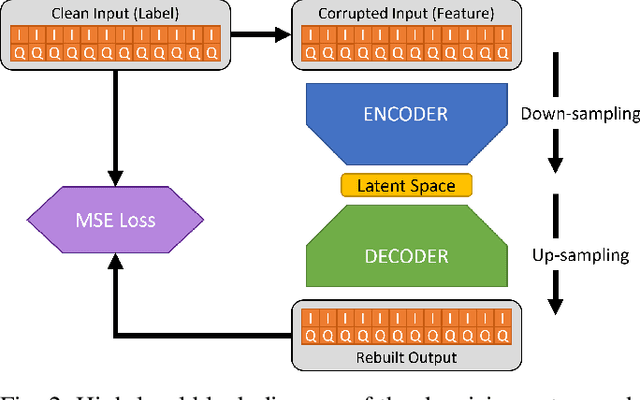

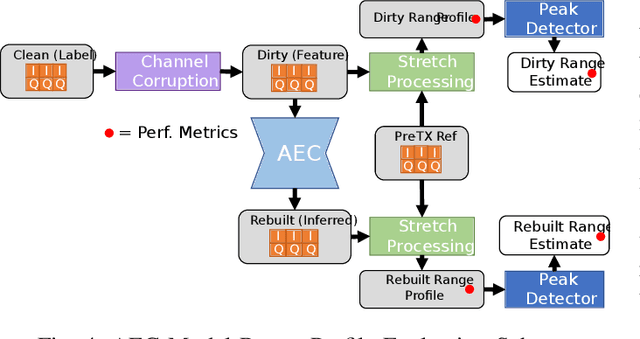
Denoising autoencoders for signal processing applications have been shown to experience significant difficulty in learning to reconstruct radio frequency communication signals, particularly in the large sample regime. In communication systems, this challenge is primarily due to the need to reconstruct the modulated data stream which is generally highly stochastic in nature. In this work, we take advantage of this limitation by using the denoising autoencoder to instead remove interfering radio frequency communication signals while reconstructing highly structured FMCW radar signals. More specifically, in this work we show that a CNN-layer only autoencoder architecture can be utilized to improve the accuracy of a radar altimeter's ranging estimate even in severe interference environments consisting of a multitude of interference signals. This is demonstrated through comprehensive performance analysis of an end-to-end FMCW radar altimeter simulation with and without the convolutional layer-only autoencoder. The proposed approach significantly improves interference mitigation in the presence of both narrow-band tone interference as well as wideband QPSK interference in terms of range RMS error, number of false altitude reports, and the peak-to-sidelobe ratio of the resulting range profile. FMCW radar signals of up to 40,000 IQ samples can be reliably reconstructed.
Linear Jamming Bandits: Learning to Jam 5G-based Coded Communications Systems
Sep 17, 2024



We study jamming of an OFDM-modulated signal which employs forward error correction coding. We extend this to leverage reinforcement learning with a contextual bandit to jam a 5G-based system implementing some aspects of the 5G protocol. This model introduces unreliable reward feedback in the form of ACK/NACK observations to the jammer to understand the effect of how imperfect observations of errors can affect the jammer's ability to learn. We gain insights into the convergence time of the jammer and its ability to jam a victim 5G waveform, as well as insights into the vulnerabilities of wireless communications for reinforcement learning-based jamming.
On the Role of 5G and Beyond Sidelink Communication in Multi-Hop Tactical Networks
Sep 28, 2023This work investigates the potential of 5G and beyond sidelink (SL) communication to support multi-hop tactical networks. We first provide a technical and historical overview of 3GPP SL standardization activities, and then consider applications to current problems of interest in tactical networking. We consider a number of multi-hop routing techniques which are expected to be of interest for SL-enabled multi-hop tactical networking and examine open-source tools useful for network emulation. Finally, we discuss relevant research directions which may be of interest for 5G SL-enabled tactical communications, namely the integration of RF sensing and positioning, as well as emerging machine learning tools such as federated and decentralized learning, which may be of great interest for resource allocation and routing problems that arise in tactical applications. We conclude by summarizing recent developments in the 5G SL literature and provide guidelines for future research.
On the Value of Online Learning for Radar Waveform Selection
Apr 21, 2023
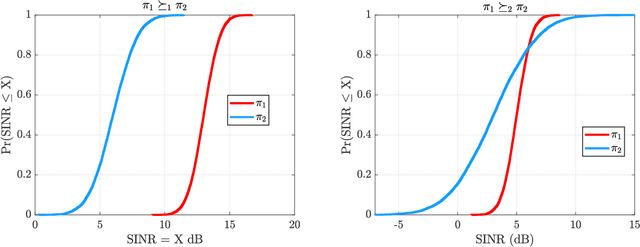
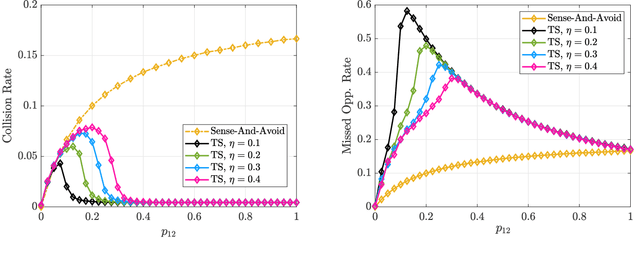

This paper attempts to characterize the kinds of physical scenarios in which an online learning-based cognitive radar is expected to reliably outperform a fixed rule-based waveform selection strategy, as well as the converse. We seek general insights through an examination of two decision-making scenarios, namely dynamic spectrum access and multiple-target tracking. The radar scene is characterized by inducing a state-space model and examining the structure of its underlying Markov state transition matrix, in terms of entropy rate and diagonality. It is found that entropy rate is a strong predictor of online learning-based waveform selection, while diagonality is a better predictor of fixed rule-based waveform selection. We show that these measures can be used to predict first and second-order stochastic dominance relationships, which can allow system designers to make use of simple decision rules instead of more cumbersome learning approaches under certain conditions. We validate our findings through numerical results for each application and provide guidelines for future implementations.
Online Learning-based Waveform Selection for Improved Vehicle Recognition in Automotive Radar
Dec 01, 2022This paper describes important considerations and challenges associated with online reinforcement-learning based waveform selection for target identification in frequency modulated continuous wave (FMCW) automotive radar systems. We present a novel learning approach based on satisficing Thompson sampling, which quickly identifies a waveform expected to yield satisfactory classification performance. We demonstrate through measurement-level simulations that effective waveform selection strategies can be quickly learned, even in cases where the radar must select from a large catalog of candidate waveforms. The radar learns to adaptively select a bandwidth for appropriate resolution and a slow-time unimodular code for interference mitigation in the scene of interest by optimizing an expected classification metric.
When is Cognitive Radar Beneficial?
Dec 01, 2022



When should an online reinforcement learning-based frequency agile cognitive radar be expected to outperform a rule-based adaptive waveform selection strategy? We seek insight regarding this question by examining a dynamic spectrum access scenario, in which the radar wishes to transmit in the widest unoccupied bandwidth during each pulse repetition interval. Online learning is compared to a fixed rule-based sense-and-avoid strategy. We show that given a simple Markov channel model, the problem can be examined analytically for simple cases via stochastic dominance. Additionally, we show that for more realistic channel assumptions, learning-based approaches demonstrate greater ability to generalize. However, for short time-horizon problems that are well-specified, we find that machine learning approaches may perform poorly due to the inherent limitation of convergence time. We draw conclusions as to when learning-based approaches are expected to be beneficial and provide guidelines for future study.
Online Bayesian Meta-Learning for Cognitive Tracking Radar
Jul 07, 2022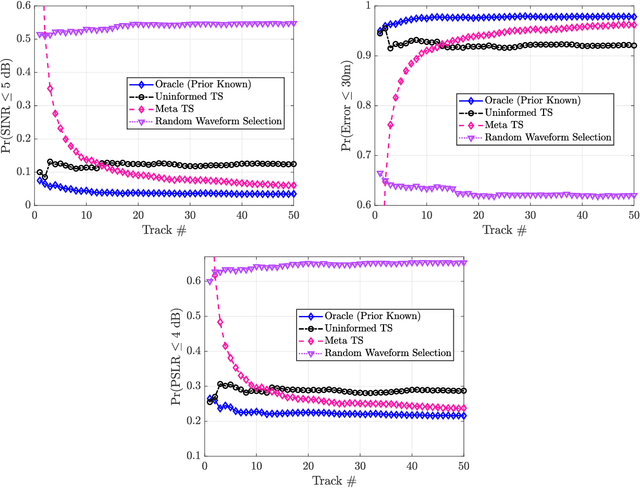
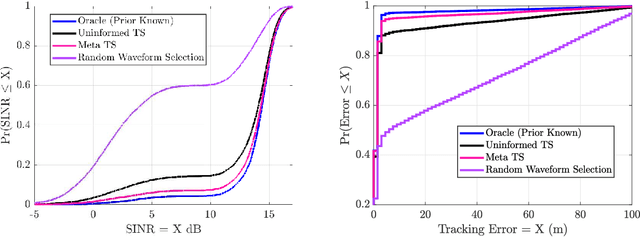
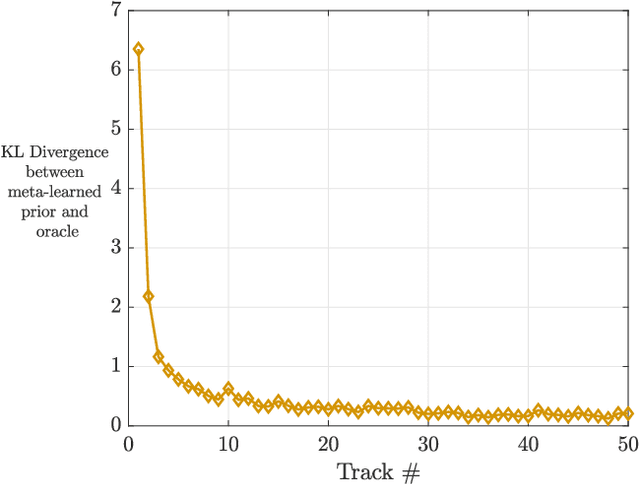
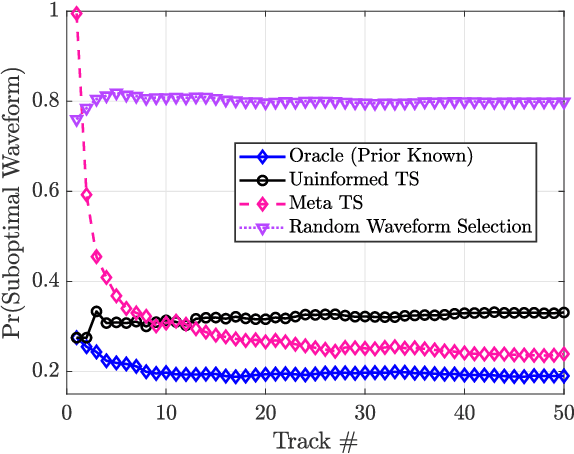
A key component of cognitive radar is the ability to generalize, or achieve consistent performance across a broad class of sensing environments, since aspects of the physical scene may vary over time. This presents a challenge for learning-based waveform selection approaches, since transmission policies which are effective in one scene may be highly suboptimal in another. One way to address this problem is to bias a learning algorithm strategically by exploiting high-level structure across tracking instances, referred to as meta-learning. In this work, we develop an online meta-learning approach for waveform-agile tracking. This approach uses information gained from previous target tracks to speed up and enhance learning in new tracking instances. This results in sample-efficient learning across a class of finite state target channels by exploiting inherent similarity across tracking scenes, attributed to common physical elements such as target type or clutter. We formulate the online waveform selection problem in the framework of Bayesian learning, and provide prior-dependent performance bounds for the meta-learning problem using PAC-Bayes theory. We present a computationally feasible posterior sampling algorithm and study the performance in a simulation study consisting of diverse scenes. Finally, we examine the potential performance benefits and practical challenges associated with online meta-learning for waveform-agile tracking.
Linear Jamming Bandits: Sample-Efficient Learning for Non-Coherent Digital Jamming
Jul 05, 2022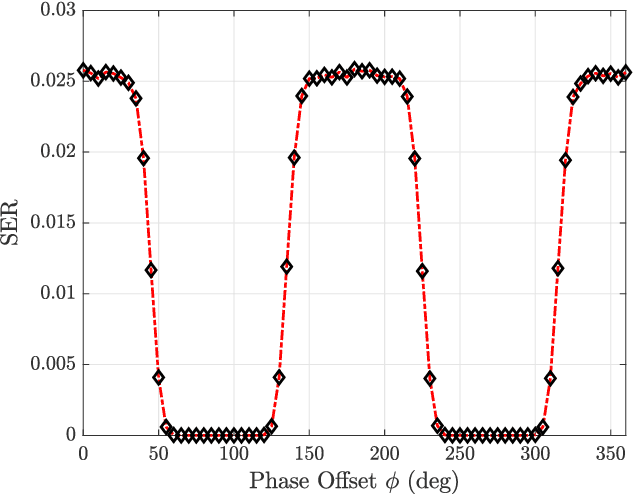
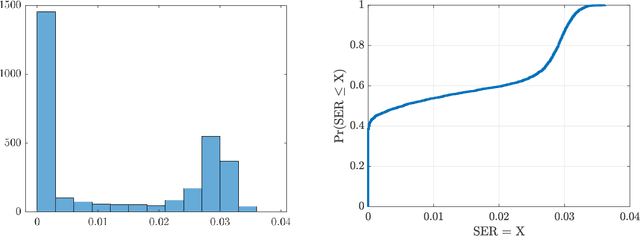
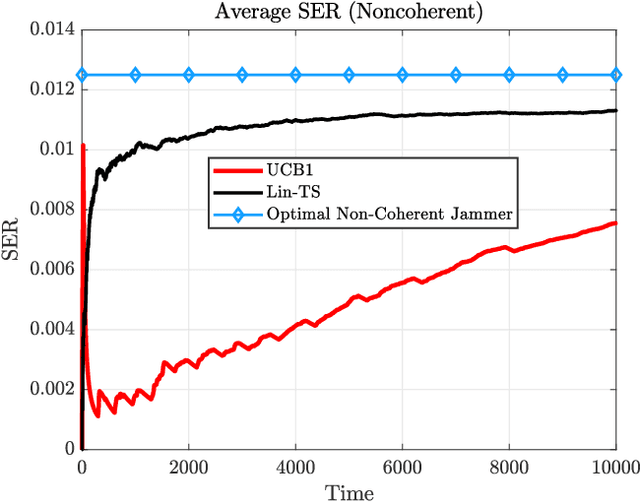
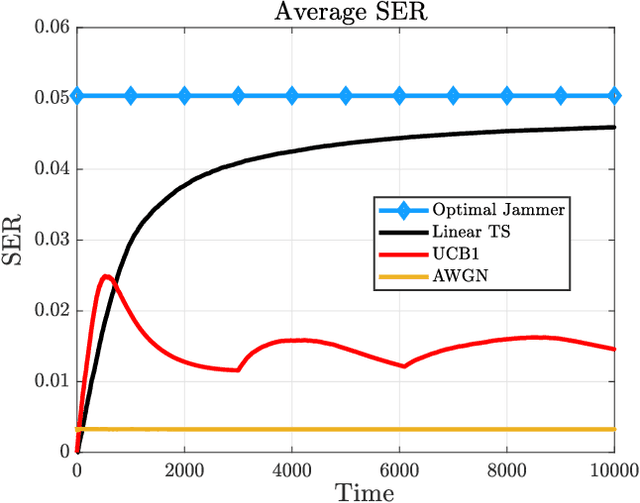
It has been shown (Amuru et al. 2015) that online learning algorithms can be effectively used to select optimal physical layer parameters for jamming against digital modulation schemes without a priori knowledge of the victim's transmission strategy. However, this learning problem involves solving a multi-armed bandit problem with a mixed action space that can grow very large. As a result, convergence to the optimal jamming strategy can be slow, especially when the victim and jammer's symbols are not perfectly synchronized. In this work, we remedy the sample efficiency issues by introducing a linear bandit algorithm that accounts for inherent similarities between actions. Further, we propose context features which are well-suited for the statistical features of the non-coherent jamming problem and demonstrate significantly improved convergence behavior compared to the prior art. Additionally, we show how prior knowledge about the victim's transmissions can be seamlessly integrated into the learning framework. We finally discuss limitations in the asymptotic regime.