 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Bayesian Meta-Learning for Cognitive Tracking Radar
Jul 07, 2022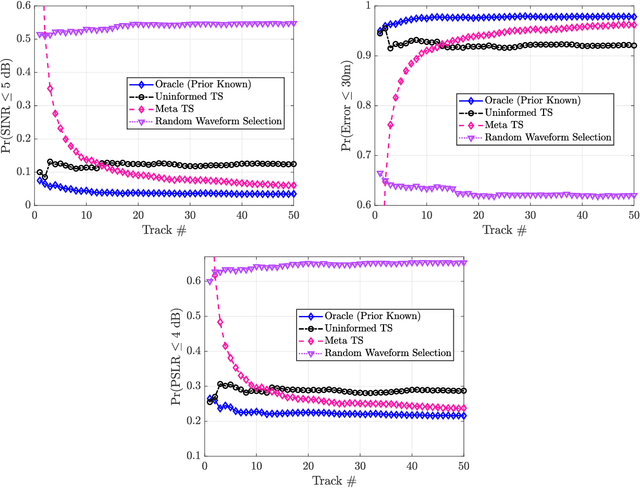
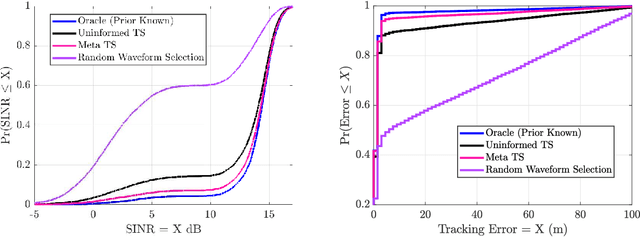
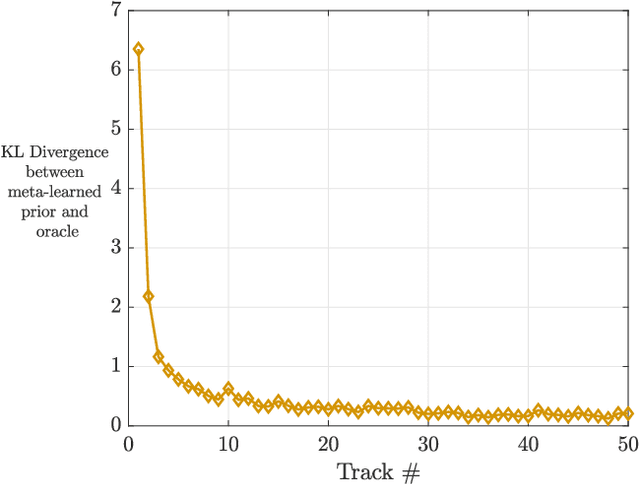
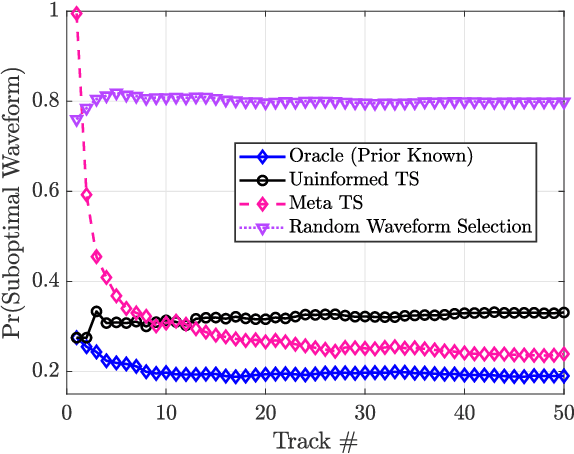
A key component of cognitive radar is the ability to generalize, or achieve consistent performance across a broad class of sensing environments, since aspects of the physical scene may vary over time. This presents a challenge for learning-based waveform selection approaches, since transmission policies which are effective in one scene may be highly suboptimal in another. One way to address this problem is to bias a learning algorithm strategically by exploiting high-level structure across tracking instances, referred to as meta-learning. In this work, we develop an online meta-learning approach for waveform-agile tracking. This approach uses information gained from previous target tracks to speed up and enhance learning in new tracking instances. This results in sample-efficient learning across a class of finite state target channels by exploiting inherent similarity across tracking scenes, attributed to common physical elements such as target type or clutter. We formulate the online waveform selection problem in the framework of Bayesian learning, and provide prior-dependent performance bounds for the meta-learning problem using PAC-Bayes theory. We present a computationally feasible posterior sampling algorithm and study the performance in a simulation study consisting of diverse scenes. Finally, we examine the potential performance benefits and practical challenges associated with online meta-learning for waveform-agile tracking.
Universal Learning Waveform Selection Strategies for Adaptive Target Tracking
Feb 10, 2022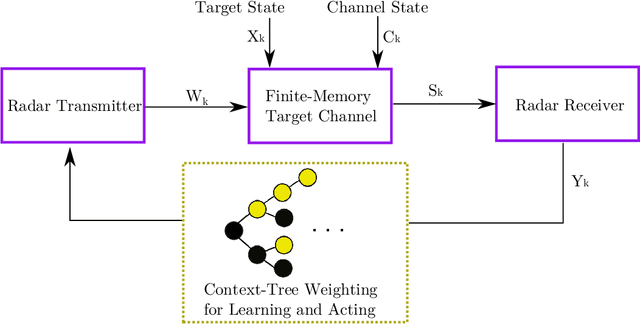
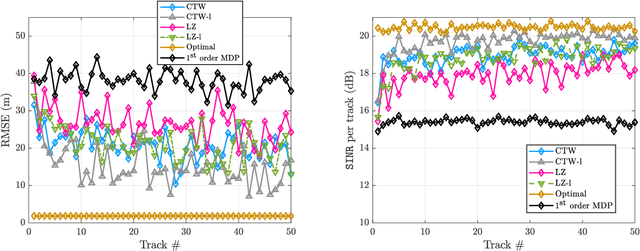
Online selection of optimal waveforms for target tracking with active sensors has long been a problem of interest. Many conventional solutions utilize an estimation-theoretic interpretation, in which a waveform-specific Cram\'{e}r-Rao lower bound on measurement error is used to select the optimal waveform for each tracking step. However, this approach is only valid in the high SNR regime, and requires a rather restrictive set of assumptions regarding the target motion and measurement models. Further, due to computational concerns, many traditional approaches are limited to near-term, or myopic, optimization, even though radar scenes exhibit strong temporal correlation. More recently, reinforcement learning has been proposed for waveform selection, in which the problem is framed as a Markov decision process (MDP), allowing for long-term planning. However, a major limitation of reinforcement learning is that the memory length of the underlying Markov process is often unknown for realistic target and channel dynamics, and a more general framework is desirable. This work develops a universal sequential waveform selection scheme which asymptotically achieves Bellman optimality in any radar scene which can be modeled as a $U^{\text{th}}$ order Markov process for a finite, but unknown, integer $U$. Our approach is based on well-established tools from the field of universal source coding, where a stationary source is parsed into variable length phrases in order to build a context-tree, which is used as a probabalistic model for the scene's behavior. We show that an algorithm based on a multi-alphabet version of the Context-Tree Weighting (CTW) method can be used to optimally solve a broad class of waveform-agile tracking problems while making minimal assumptions about the environment's behavior.
Online Meta-Learning for Scene-Diverse Waveform-Agile Radar Target Tracking
Oct 21, 2021
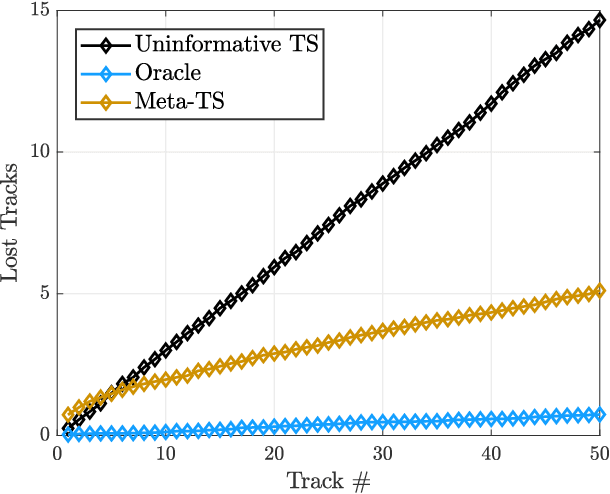
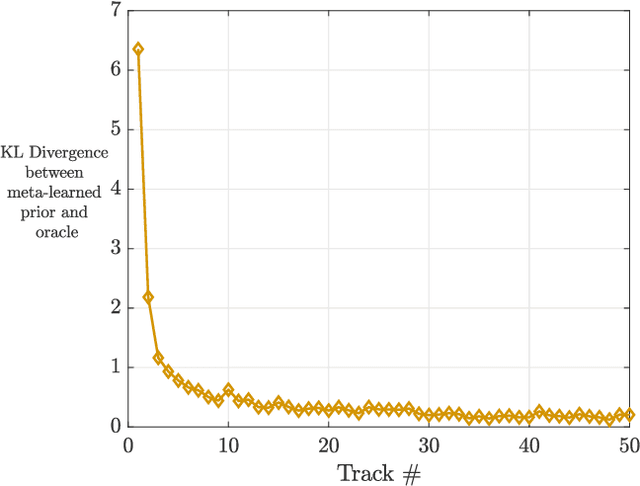
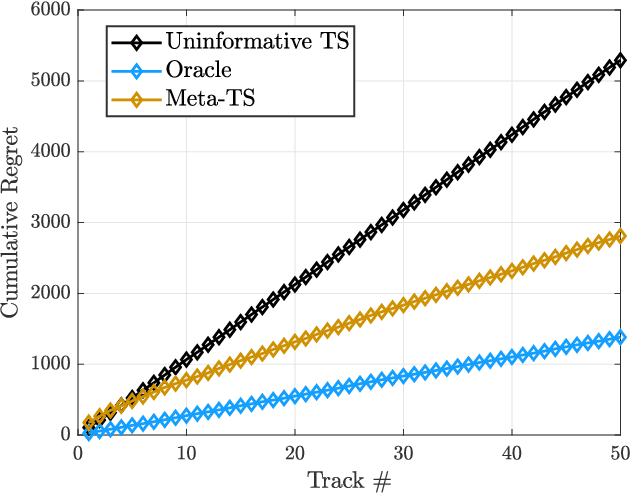
A fundamental problem for waveform-agile radar systems is that the true environment is unknown, and transmission policies which perform well for a particular tracking instance may be sub-optimal for another. Additionally, there is a limited time window for each target track, and the radar must learn an effective strategy from a sequence of measurements in a timely manner. This paper studies a Bayesian meta-learning model for radar waveform selection which seeks to learn an inductive bias to quickly optimize tracking performance across a class of radar scenes. We cast the waveform selection problem in the framework of sequential Bayesian inference, and introduce a contextual bandit variant of the recently proposed meta-Thompson Sampling algorithm, which learns an inductive bias in the form of a prior distribution. Each track is treated as an instance of a contextual bandit learning problem, coming from a task distribution. We show that the meta-learning process results in an appreciably faster learning, resulting in significantly fewer lost tracks than a conventional learning approach equipped with an uninformative prior.
Open Set Wireless Standard Classification Using Convolutional Neural Networks
Aug 03, 2021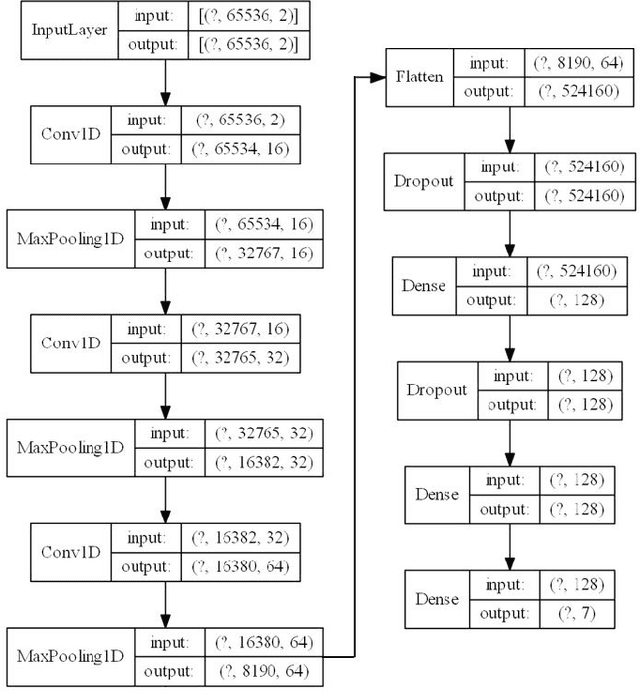
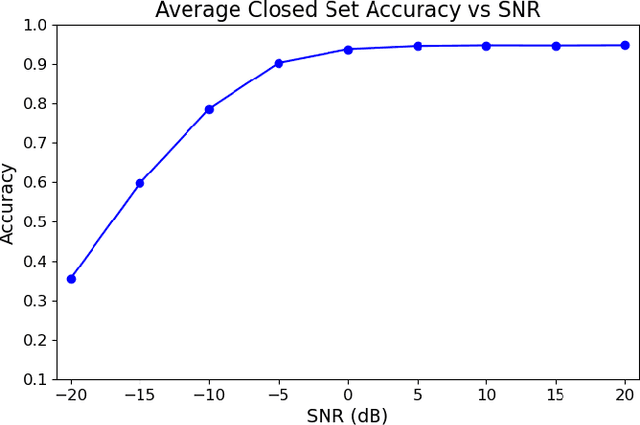
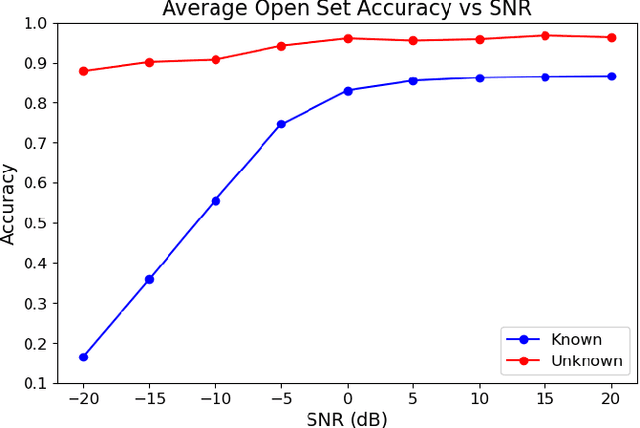
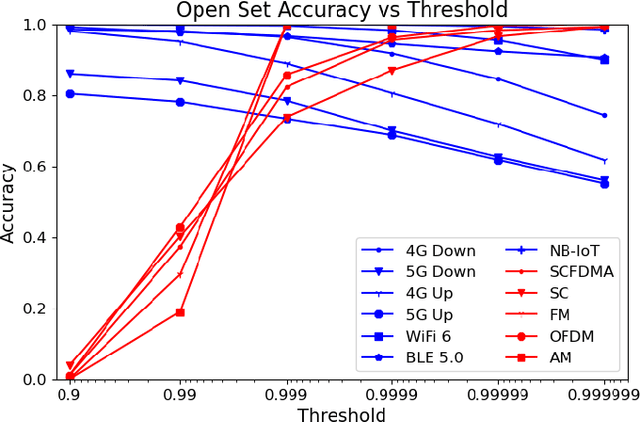
In congested electromagnetic environments, cognitive radios require knowledge about other emitters in order to optimize their dynamic spectrum access strategy. Deep learning classification algorithms have been used to recognize the wireless signal standards of emitters with high accuracy, but are limited to classifying signal classes that appear in their training set. This diminishes the performance of deep learning classifiers deployed in the field because they cannot accurately identify signals from classes outside of the training set. In this paper, a convolution neural network based open set classifier is proposed with the ability to detect if signals are not from known classes by thresholding the output sigmoid activation. The open set classifier was trained on 4G LTE, 5G NR, IEEE 802.11ax, Bluetooth Low Energy 5.0, and Narrowband Internet-of-Things signals impaired with Rayleigh or Rician fading, AWGN, frequency offsets, and in-phase/quadrature imbalances. Then, the classifier was tested on OFDM, SC-FDMA, SC, AM, and FM signals, which did not appear in the training set classes. The closed set classifier achieves an average accuracy of 94.5% for known signals with SNR's greater than 0 dB, but by design, has a 0% accuracy detecting signals from unknown classes. On the other hand, the open set classifier retains an 86% accuracy for known signal classes, but can detect 95.5% of signals from unknown classes with SNR's greater than 0 dB.
Waveform Selection for Radar Tracking in Target Channels With Memory via Universal Learning
Aug 02, 2021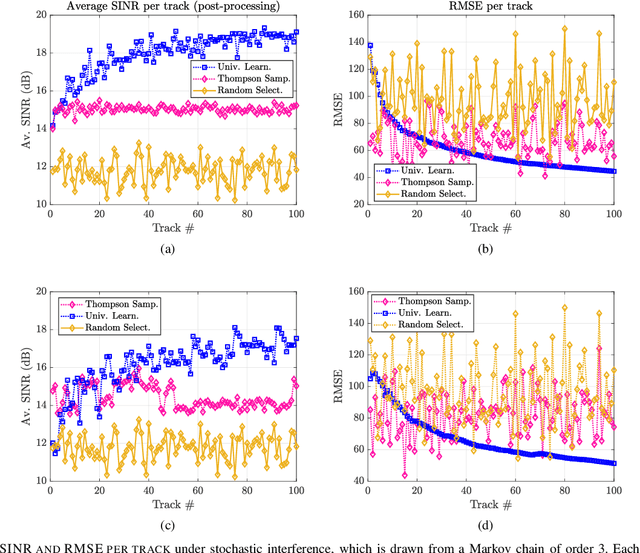
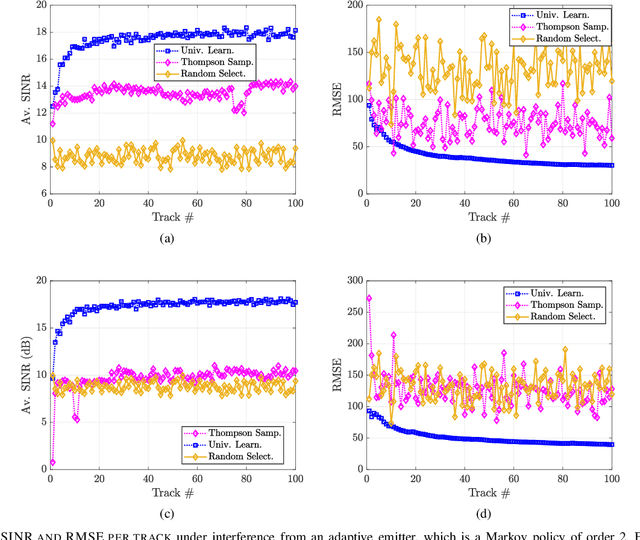
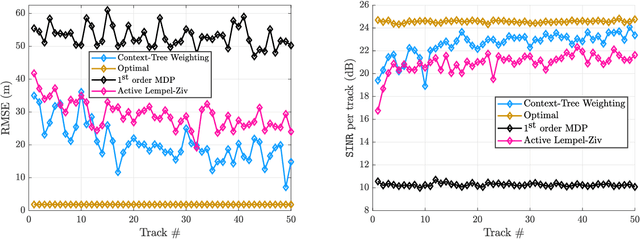
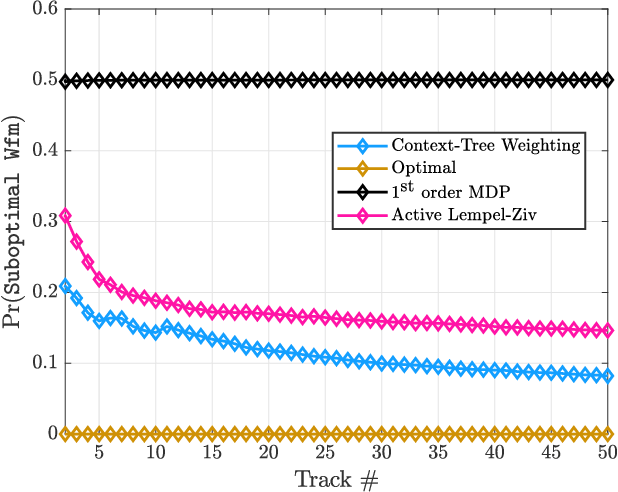
In tracking radar, the sensing environment often varies significantly over a track duration due to the target's trajectory and dynamic interference. Adapting the radar's waveform using partial information about the state of the scene has been shown to provide performance benefits in many practical scenarios. Moreover, radar measurements generally exhibit strong temporal correlation, allowing memory-based learning algorithms to effectively learn waveform selection strategies. This work examines a radar system which builds a compressed model of the radar-environment interface in the form of a context-tree. The radar uses this context tree-based model to select waveforms in a signal-dependent target channel, which may respond adversarially to the radar's strategy. This approach is guaranteed to asymptotically converge to the average-cost optimal policy for any stationary target channel that can be represented as a Markov process of order U < $\infty$, where the constant U is unknown to the radar. The proposed approach is tested in a simulation study, and is shown to provide tracking performance improvements over two state-of-the-art waveform selection schemes.
Constrained Contextual Bandit Learning for Adaptive Radar Waveform Selection
Mar 09, 2021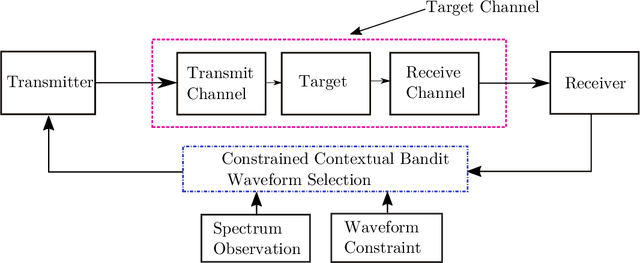
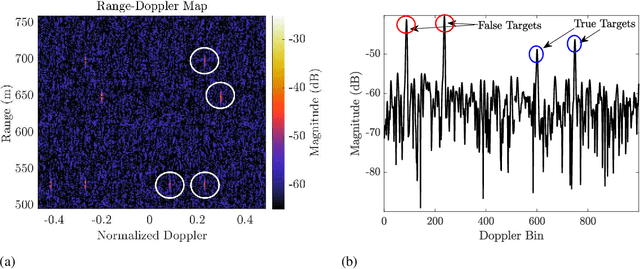
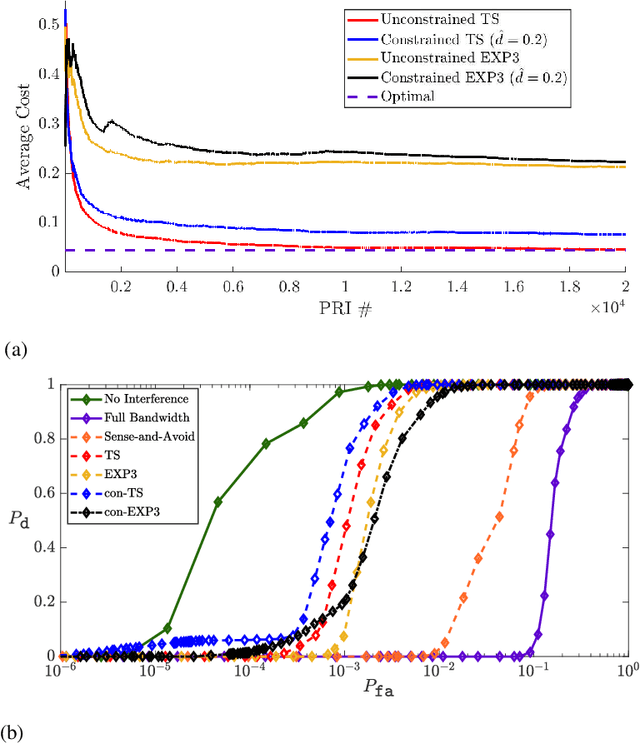

A sequential decision process in which an adaptive radar system repeatedly interacts with a finite-state target channel is studied. The radar is capable of passively sensing the spectrum at regular intervals, which provides side information for the waveform selection process. The radar transmitter uses the sequence of spectrum observations as well as feedback from a collocated receiver to select waveforms which accurately estimate target parameters. It is shown that the waveform selection problem can be effectively addressed using a linear contextual bandit formulation in a manner that is both computationally feasible and sample efficient. Stochastic and adversarial linear contextual bandit models are introduced, allowing the radar to achieve effective performance in broad classes of physical environments. Simulations in a radar-communication coexistence scenario, as well as in an adversarial radar-jammer scenario, demonstrate that the proposed formulation provides a substantial improvement in target detection performance when Thompson Sampling and EXP3 algorithms are used to drive the waveform selection process. Further, it is shown that the harmful impacts of pulse-agile behavior on coherently processed radar data can be mitigated by adopting a time-varying constraint on the radar's waveform catalog.
Efficient Online Learning for Cognitive Radar-Cellular Coexistence via Contextual Thompson Sampling
Aug 24, 2020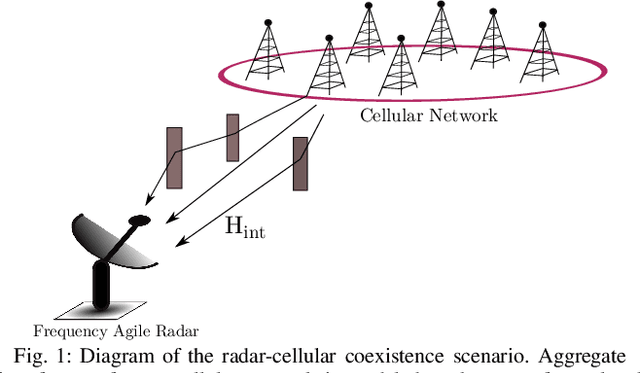


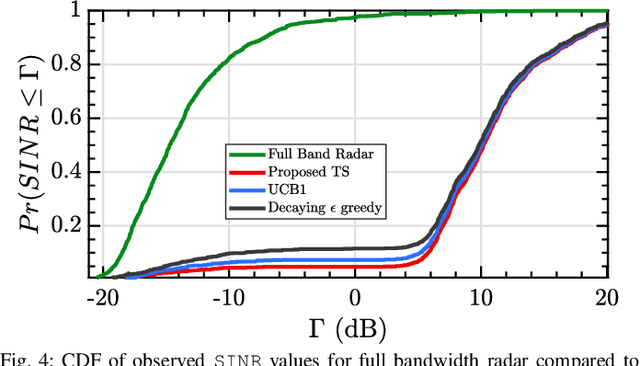
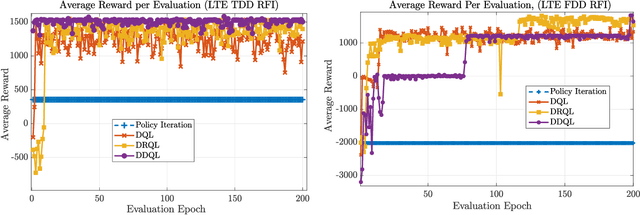
This paper describes a sequential, or online, learning scheme for adaptive radar transmissions that facilitate spectrum sharing with a non-cooperative cellular network. First, the interference channel between the radar and a spatially distant cellular network is modeled. Then, a linear Contextual Bandit (CB) learning framework is applied to drive the radar's behavior. The fundamental trade-off between exploration and exploitation is balanced by a proposed Thompson Sampling (TS) algorithm, a pseudo-Bayesian approach which selects waveform parameters based on the posterior probability that a specific waveform is optimal, given discounted channel information as context. It is shown that the contextual TS approach converges more rapidly to behavior that minimizes mutual interference and maximizes spectrum utilization than comparable contextual bandit algorithms. Additionally, we show that the TS learning scheme results in a favorable SINR distribution compared to other online learning algorithms. Finally, the proposed TS algorithm is compared to a deep reinforcement learning model. We show that the TS algorithm maintains competitive performance with a more complex Deep Q-Network (DQN).
Deep Reinforcement Learning Control for Radar Detection and Tracking in Congested Spectral Environments
Jun 23, 2020
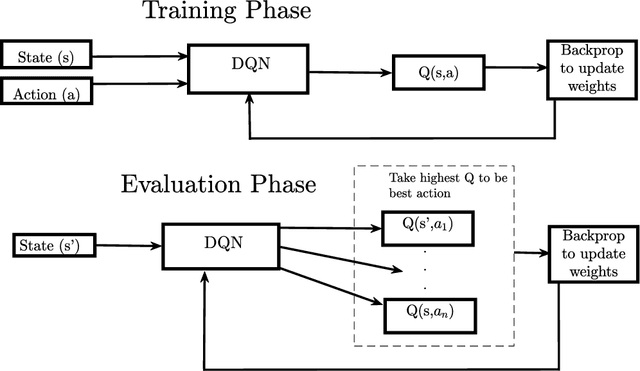
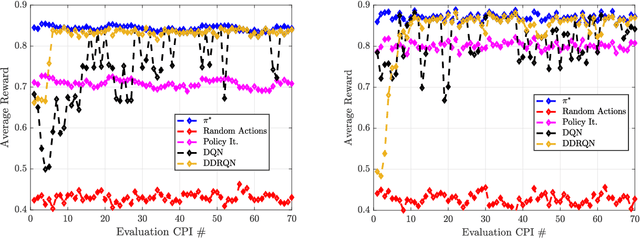
In this paper, dynamic non-cooperative coexistence between a cognitive pulsed radar and a nearby communications system is addressed by applying nonlinear value function approximation via deep reinforcement learning (Deep RL) to develop a policy for optimal radar performance. The radar learns to vary the bandwidth and center frequency of its linear frequency modulated (LFM) waveforms to mitigate mutual interference with other systems and improve target detection performance while also maintaining sufficient utilization of the available frequency bands required for a fine range resolution. We demonstrate that our approach, based on the Deep Q-Learning (DQL) algorithm, enhances important radar metrics, including SINR and bandwidth utilization, more effectively than policy iteration or sense-and-avoid (SAA) approaches in a variety of realistic coexistence environments. We also extend the DQL-based approach to incorporate Double Q-learning and a recurrent neural network to form a Double Deep Recurrent Q-Network (DDRQN). We demonstrate the DDRQN results in favorable performance and stability compared to DQL and policy iteration. Finally, we demonstrate the practicality of our proposed approach through a discussion of experiments performed on a software defined radar (SDRadar) prototype system. Our experimental results indicate that the proposed Deep RL approach significantly improves radar detection performance in congested spectral environments when compared to policy iteration and SAA.
Experimental Analysis of Reinforcement Learning Techniques for Spectrum Sharing Radar
Jan 06, 2020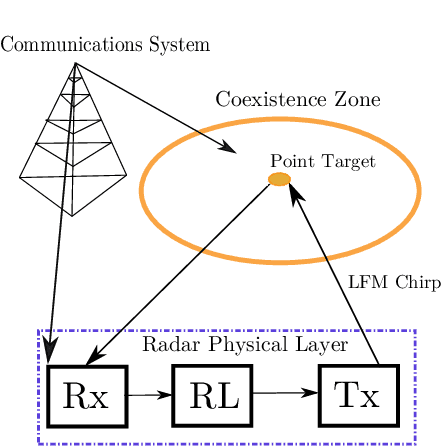
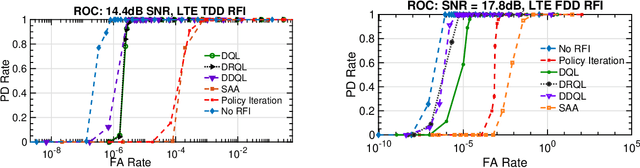
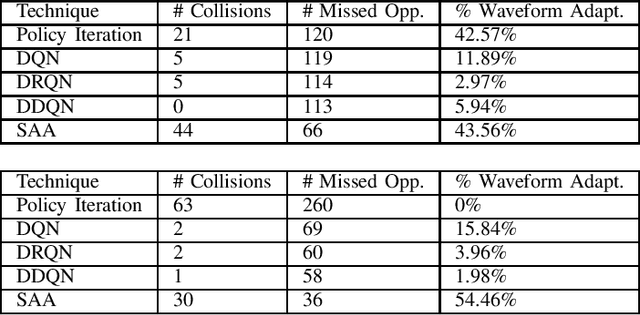
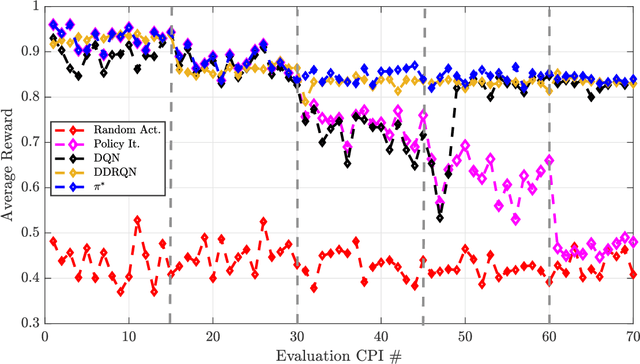
In this work, we first describe a framework for the application of Reinforcement Learning (RL) control to a radar system that operates in a congested spectral setting. We then compare the utility of several RL algorithms through a discussion of experiments performed on Commercial off-the-shelf (COTS) hardware. Each RL technique is evaluated in terms of convergence, radar detection performance achieved in a congested spectral environment, and the ability to share 100MHz spectrum with an uncooperative communications system. We examine policy iteration, which solves an environment posed as a Markov Decision Process (MDP) by directly solving for a stochastic mapping between environmental states and radar waveforms, as well as Deep RL techniques, which utilize a form of Q-Learning to approximate a parameterized function that is used by the radar to select optimal actions. We show that RL techniques are beneficial over a Sense-and-Avoid (SAA) scheme and discuss the conditions under which each approach is most effective.