 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Reinforcement Learning Control for Radar Detection and Tracking in Congested Spectral Environments
Jun 23, 2020
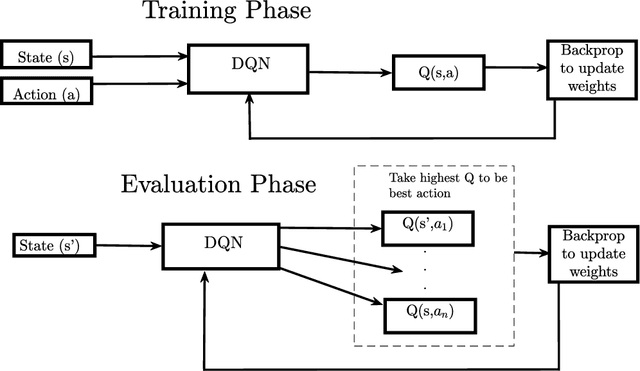
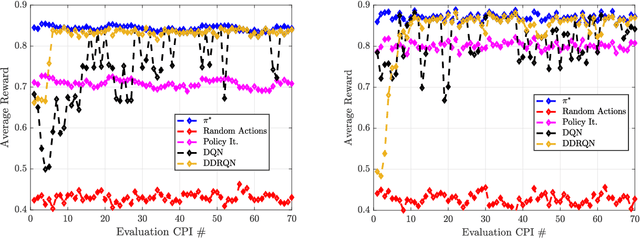
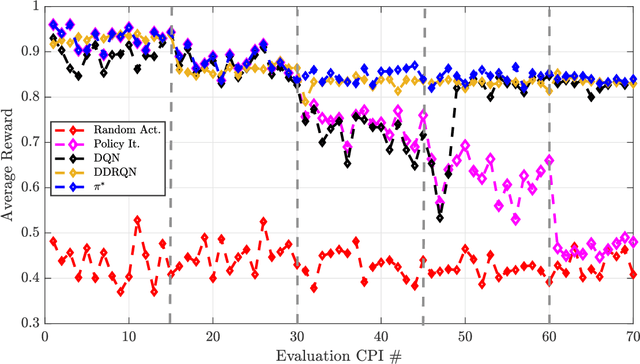
In this paper, dynamic non-cooperative coexistence between a cognitive pulsed radar and a nearby communications system is addressed by applying nonlinear value function approximation via deep reinforcement learning (Deep RL) to develop a policy for optimal radar performance. The radar learns to vary the bandwidth and center frequency of its linear frequency modulated (LFM) waveforms to mitigate mutual interference with other systems and improve target detection performance while also maintaining sufficient utilization of the available frequency bands required for a fine range resolution. We demonstrate that our approach, based on the Deep Q-Learning (DQL) algorithm, enhances important radar metrics, including SINR and bandwidth utilization, more effectively than policy iteration or sense-and-avoid (SAA) approaches in a variety of realistic coexistence environments. We also extend the DQL-based approach to incorporate Double Q-learning and a recurrent neural network to form a Double Deep Recurrent Q-Network (DDRQN). We demonstrate the DDRQN results in favorable performance and stability compared to DQL and policy iteration. Finally, we demonstrate the practicality of our proposed approach through a discussion of experiments performed on a software defined radar (SDRadar) prototype system. Our experimental results indicate that the proposed Deep RL approach significantly improves radar detection performance in congested spectral environments when compared to policy iteration and SAA.
Experimental Analysis of Reinforcement Learning Techniques for Spectrum Sharing Radar
Jan 06, 2020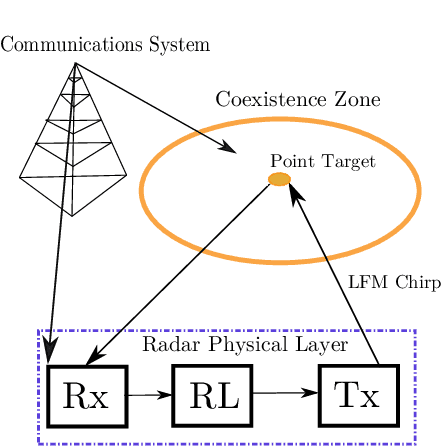
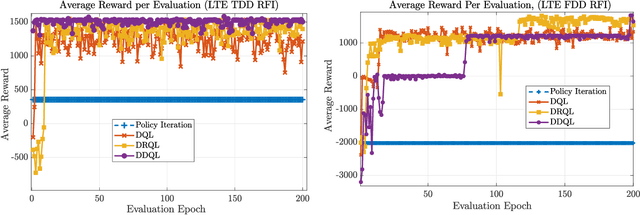
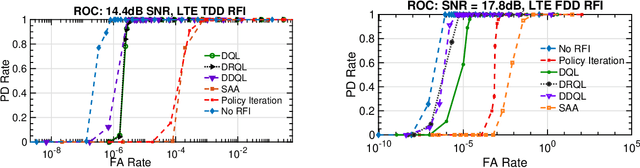
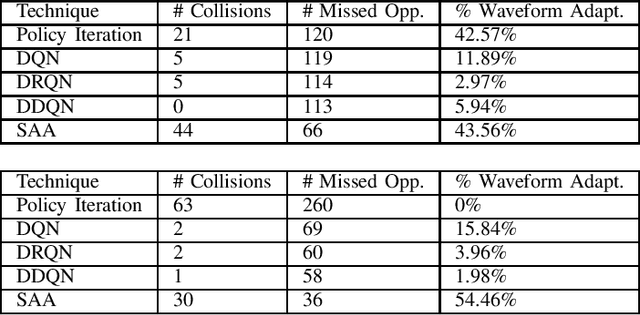
In this work, we first describe a framework for the application of Reinforcement Learning (RL) control to a radar system that operates in a congested spectral setting. We then compare the utility of several RL algorithms through a discussion of experiments performed on Commercial off-the-shelf (COTS) hardware. Each RL technique is evaluated in terms of convergence, radar detection performance achieved in a congested spectral environment, and the ability to share 100MHz spectrum with an uncooperative communications system. We examine policy iteration, which solves an environment posed as a Markov Decision Process (MDP) by directly solving for a stochastic mapping between environmental states and radar waveforms, as well as Deep RL techniques, which utilize a form of Q-Learning to approximate a parameterized function that is used by the radar to select optimal actions. We show that RL techniques are beneficial over a Sense-and-Avoid (SAA) scheme and discuss the conditions under which each approach is most effective.