 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Jamming Bandits: Sample-Efficient Learning for Non-Coherent Digital Jamming
Paper and Code
Jul 05, 2022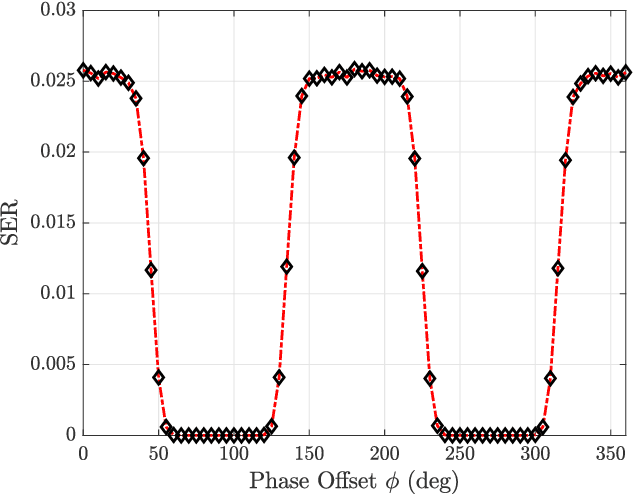
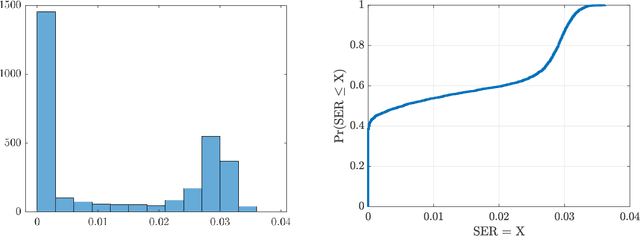
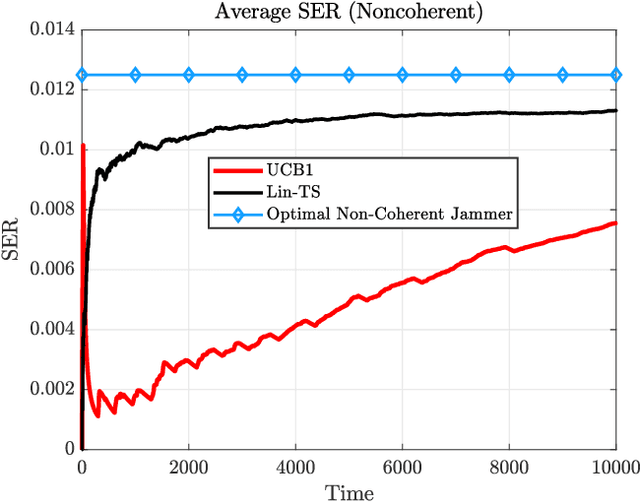
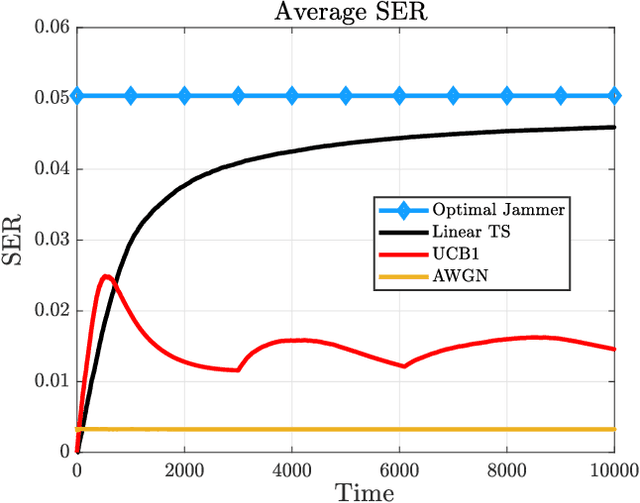
It has been shown (Amuru et al. 2015) that online learning algorithms can be effectively used to select optimal physical layer parameters for jamming against digital modulation schemes without a priori knowledge of the victim's transmission strategy. However, this learning problem involves solving a multi-armed bandit problem with a mixed action space that can grow very large. As a result, convergence to the optimal jamming strategy can be slow, especially when the victim and jammer's symbols are not perfectly synchronized. In this work, we remedy the sample efficiency issues by introducing a linear bandit algorithm that accounts for inherent similarities between actions. Further, we propose context features which are well-suited for the statistical features of the non-coherent jamming problem and demonstrate significantly improved convergence behavior compared to the prior art. Additionally, we show how prior knowledge about the victim's transmissions can be seamlessly integrated into the learning framework. We finally discuss limitations in the asymptotic regime.