 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe bitter lesson of misuse detection
Jul 08, 2025Prior work on jailbreak detection has established the importance of adversarial robustness for LLMs but has largely focused on the model ability to resist adversarial inputs and to output safe content, rather than the effectiveness of external supervision systems. The only public and independent benchmark of these guardrails to date evaluates a narrow set of supervisors on limited scenarios. Consequently, no comprehensive public benchmark yet verifies how well supervision systems from the market perform under realistic, diverse attacks. To address this, we introduce BELLS, a Benchmark for the Evaluation of LLM Supervision Systems. The framework is two dimensional: harm severity (benign, borderline, harmful) and adversarial sophistication (direct vs. jailbreak) and provides a rich dataset covering 3 jailbreak families and 11 harm categories. Our evaluations reveal drastic limitations of specialized supervision systems. While they recognize some known jailbreak patterns, their semantic understanding and generalization capabilities are very limited, sometimes with detection rates close to zero when asking a harmful question directly or with a new jailbreak technique such as base64 encoding. Simply asking generalist LLMs if the user question is "harmful or not" largely outperforms these supervisors from the market according to our BELLS score. But frontier LLMs still suffer from metacognitive incoherence, often responding to queries they correctly identify as harmful (up to 30 percent for Claude 3.7 and greater than 50 percent for Mistral Large). These results suggest that simple scaffolding could significantly improve misuse detection robustness, but more research is needed to assess the tradeoffs of such techniques. Our results support the "bitter lesson" of misuse detection: general capabilities of LLMs are necessary to detect a diverse array of misuses and jailbreaks.
Safety by Measurement: A Systematic Literature Review of AI Safety Evaluation Methods
May 08, 2025As frontier AI systems advance toward transformative capabilities, we need a parallel transformation in how we measure and evaluate these systems to ensure safety and inform governance. While benchmarks have been the primary method for estimating model capabilities, they often fail to establish true upper bounds or predict deployment behavior. This literature review consolidates the rapidly evolving field of AI safety evaluations, proposing a systematic taxonomy around three dimensions: what properties we measure, how we measure them, and how these measurements integrate into frameworks. We show how evaluations go beyond benchmarks by measuring what models can do when pushed to the limit (capabilities), the behavioral tendencies exhibited by default (propensities), and whether our safety measures remain effective even when faced with subversive adversarial AI (control). These properties are measured through behavioral techniques like scaffolding, red teaming and supervised fine-tuning, alongside internal techniques such as representation analysis and mechanistic interpretability. We provide deeper explanations of some safety-critical capabilities like cybersecurity exploitation, deception, autonomous replication, and situational awareness, alongside concerning propensities like power-seeking and scheming. The review explores how these evaluation methods integrate into governance frameworks to translate results into concrete development decisions. We also highlight challenges to safety evaluations - proving absence of capabilities, potential model sandbagging, and incentives for "safetywashing" - while identifying promising research directions. By synthesizing scattered resources, this literature review aims to provide a central reference point for understanding AI safety evaluations.
BELLS: A Framework Towards Future Proof Benchmarks for the Evaluation of LLM Safeguards
Jun 03, 2024Input-output safeguards are used to detect anomalies in the traces produced by Large Language Models (LLMs) systems. These detectors are at the core of diverse safety-critical applications such as real-time monitoring, offline evaluation of traces, and content moderation. However, there is no widely recognized methodology to evaluate them. To fill this gap, we introduce the Benchmarks for the Evaluation of LLM Safeguards (BELLS), a structured collection of tests, organized into three categories: (1) established failure tests, based on already-existing benchmarks for well-defined failure modes, aiming to compare the performance of current input-output safeguards; (2) emerging failure tests, to measure generalization to never-seen-before failure modes and encourage the development of more general safeguards; (3) next-gen architecture tests, for more complex scaffolding (such as LLM-agents and multi-agent systems), aiming to foster the development of safeguards that could adapt to future applications for which no safeguard currently exists. Furthermore, we implement and share the first next-gen architecture test, using the MACHIAVELLI environment, along with an interactive visualization of the dataset.
Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback
Jul 27, 2023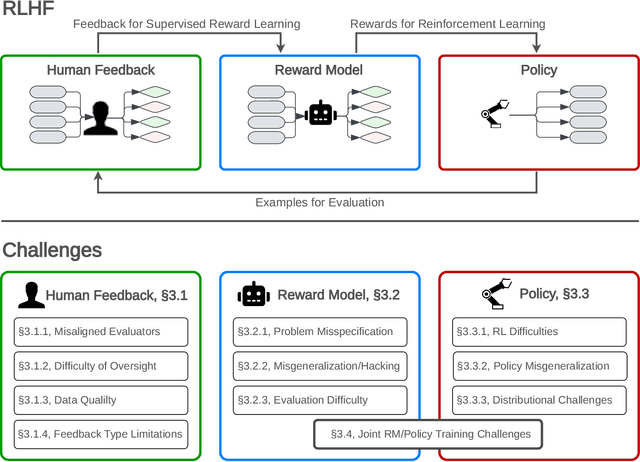
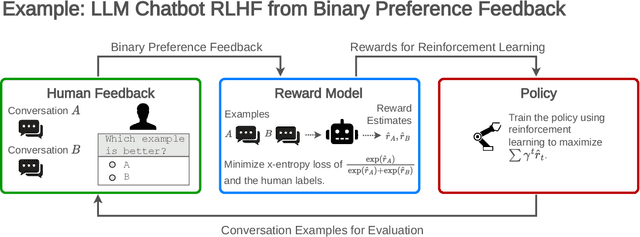
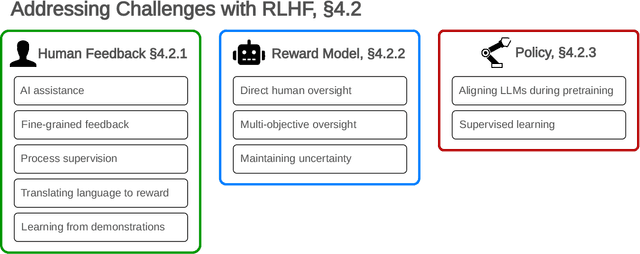

Reinforcement learning from human feedback (RLHF) is a technique for training AI systems to align with human goals. RLHF has emerged as the central method used to finetune state-of-the-art large language models (LLMs). Despite this popularity, there has been relatively little public work systematizing its flaws. In this paper, we (1) survey open problems and fundamental limitations of RLHF and related methods; (2) overview techniques to understand, improve, and complement RLHF in practice; and (3) propose auditing and disclosure standards to improve societal oversight of RLHF systems. Our work emphasizes the limitations of RLHF and highlights the importance of a multi-faceted approach to the development of safer AI systems.