 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Entity Tagging with Multimodal Knowledge Base
Dec 21, 2021
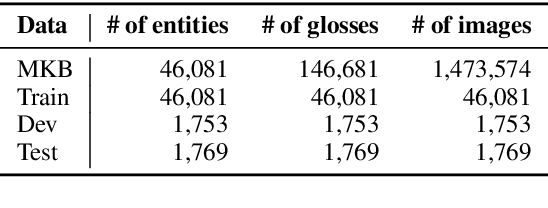
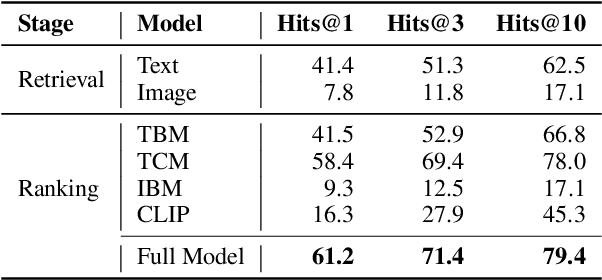
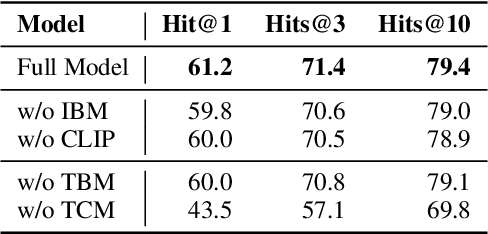
To enhance research on multimodal knowledge base and multimodal information processing, we propose a new task called multimodal entity tagging (MET) with a multimodal knowledge base (MKB). We also develop a dataset for the problem using an existing MKB. In an MKB, there are entities and their associated texts and images. In MET, given a text-image pair, one uses the information in the MKB to automatically identify the related entity in the text-image pair. We solve the task by using the information retrieval paradigm and implement several baselines using state-of-the-art methods in NLP and CV. We conduct extensive experiments and make analyses on the experimental results. The results show that the task is challenging, but current technologies can achieve relatively high performance. We will release the dataset, code, and models for future research.
Fact-based Text Editing
Jul 02, 2020
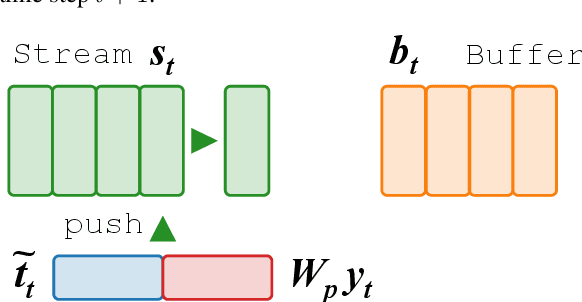

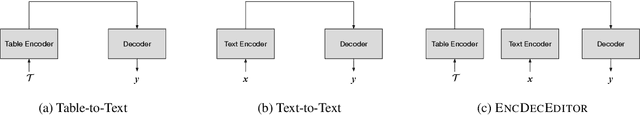
We propose a novel text editing task, referred to as \textit{fact-based text editing}, in which the goal is to revise a given document to better describe the facts in a knowledge base (e.g., several triples). The task is important in practice because reflecting the truth is a common requirement in text editing. First, we propose a method for automatically generating a dataset for research on fact-based text editing, where each instance consists of a draft text, a revised text, and several facts represented in triples. We apply the method into two public table-to-text datasets, obtaining two new datasets consisting of 233k and 37k instances, respectively. Next, we propose a new neural network architecture for fact-based text editing, called \textsc{FactEditor}, which edits a draft text by referring to given facts using a buffer, a stream, and a memory. A straightforward approach to address the problem would be to employ an encoder-decoder model. Our experimental results on the two datasets show that \textsc{FactEditor} outperforms the encoder-decoder approach in terms of fidelity and fluency. The results also show that \textsc{FactEditor} conducts inference faster than the encoder-decoder approach.
Word Embedding based Edit Distance
Oct 25, 2018
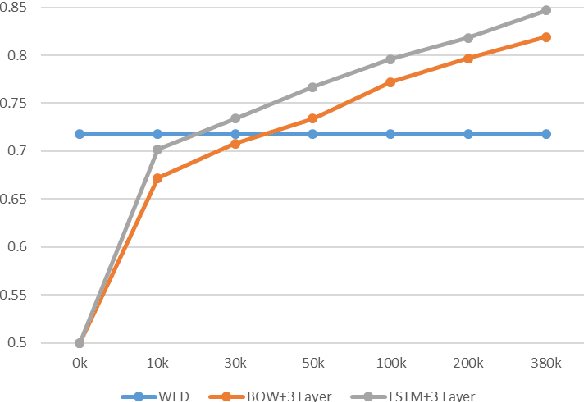

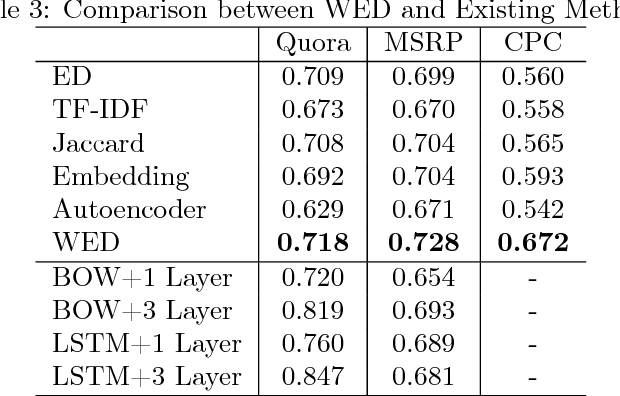
Text similarity calculation is a fundamental problem in natural language processing and related fields. In recent years, deep neural networks have been developed to perform the task and high performances have been achieved. The neural networks are usually trained with labeled data in supervised learning, and creation of labeled data is usually very costly. In this short paper, we address unsupervised learning for text similarity calculation. We propose a new method called Word Embedding based Edit Distance (WED), which incorporates word embedding into edit distance. Experiments on three benchmark datasets show WED outperforms state-of-the-art unsupervised methods including edit distance, TF-IDF based cosine, word embedding based cosine, Jaccard index, etc.