 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Embedding based Edit Distance
Paper and Code
Oct 25, 2018
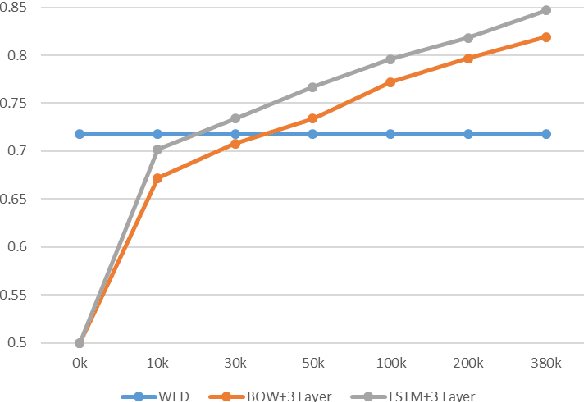

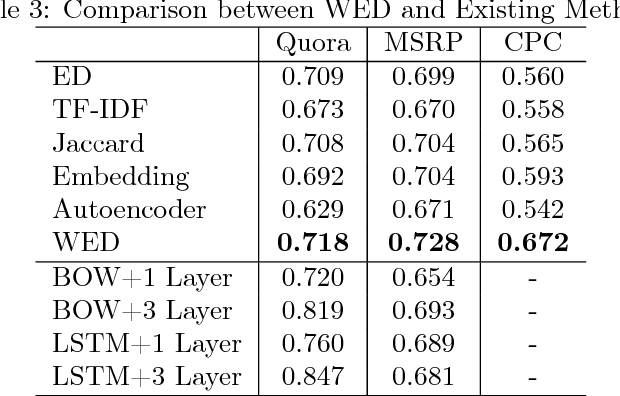
Text similarity calculation is a fundamental problem in natural language processing and related fields. In recent years, deep neural networks have been developed to perform the task and high performances have been achieved. The neural networks are usually trained with labeled data in supervised learning, and creation of labeled data is usually very costly. In this short paper, we address unsupervised learning for text similarity calculation. We propose a new method called Word Embedding based Edit Distance (WED), which incorporates word embedding into edit distance. Experiments on three benchmark datasets show WED outperforms state-of-the-art unsupervised methods including edit distance, TF-IDF based cosine, word embedding based cosine, Jaccard index, etc.