 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFact-based Text Editing
Paper and Code

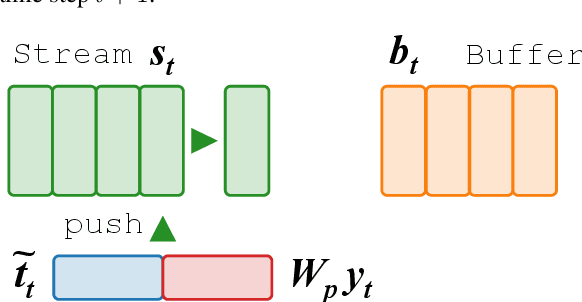

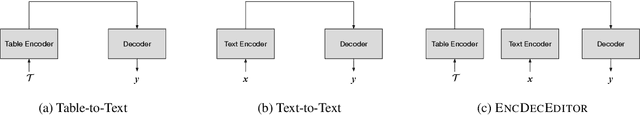
We propose a novel text editing task, referred to as \textit{fact-based text editing}, in which the goal is to revise a given document to better describe the facts in a knowledge base (e.g., several triples). The task is important in practice because reflecting the truth is a common requirement in text editing. First, we propose a method for automatically generating a dataset for research on fact-based text editing, where each instance consists of a draft text, a revised text, and several facts represented in triples. We apply the method into two public table-to-text datasets, obtaining two new datasets consisting of 233k and 37k instances, respectively. Next, we propose a new neural network architecture for fact-based text editing, called \textsc{FactEditor}, which edits a draft text by referring to given facts using a buffer, a stream, and a memory. A straightforward approach to address the problem would be to employ an encoder-decoder model. Our experimental results on the two datasets show that \textsc{FactEditor} outperforms the encoder-decoder approach in terms of fidelity and fluency. The results also show that \textsc{FactEditor} conducts inference faster than the encoder-decoder approach.