 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Entity Tagging with Multimodal Knowledge Base
Paper and Code

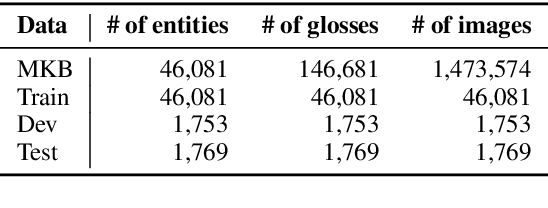
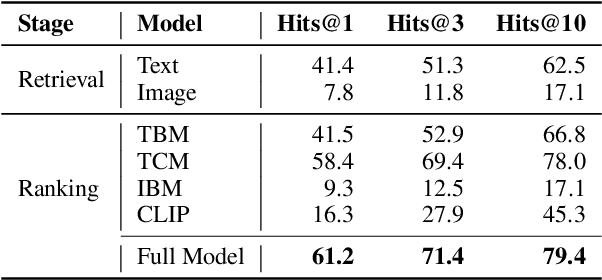
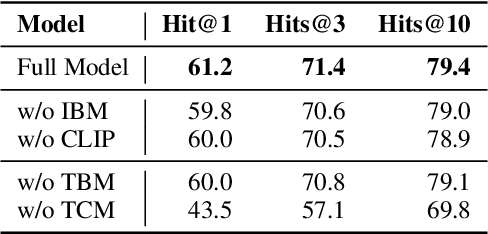
To enhance research on multimodal knowledge base and multimodal information processing, we propose a new task called multimodal entity tagging (MET) with a multimodal knowledge base (MKB). We also develop a dataset for the problem using an existing MKB. In an MKB, there are entities and their associated texts and images. In MET, given a text-image pair, one uses the information in the MKB to automatically identify the related entity in the text-image pair. We solve the task by using the information retrieval paradigm and implement several baselines using state-of-the-art methods in NLP and CV. We conduct extensive experiments and make analyses on the experimental results. The results show that the task is challenging, but current technologies can achieve relatively high performance. We will release the dataset, code, and models for future research.