 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrokking in Linear Models for Logistic Regression
Feb 09, 2026Grokking, the phenomenon of delayed generalization, is often attributed to the depth and compositional structure of deep neural networks. We study grokking in one of the simplest possible settings: the learning of a linear model with logistic loss for binary classification on data that are linearly (and max margin) separable about the origin. We investigate three testing regimes: (1) test data drawn from the same distribution as the training data, in which case grokking is not observed; (2) test data concentrated around the margin, in which case grokking is observed; and (3) adversarial test data generated via projected gradient descent (PGD) attacks, in which case grokking is also observed. We theoretically show that the implicit bias of gradient descent induces a three-phase learning process-population-dominated, support-vector-dominated unlearning, and support-vector-dominated generalization-during which delayed generalization can arise. Our analysis further relates the emergence of grokking to asymmetries in the data, both in the number of examples per class and in the distribution of support vectors across classes, and yields a characterization of the grokking time. We experimentally validate our theory by planting different distributions of population points and support vectors, and by analyzing accuracy curves and hyperplane dynamics. Overall, our results demonstrate that grokking does not require depth or representation learning, and can emerge even in linear models through the dynamics of the bias term.
Learning to Price: Interpretable Attribute-Level Models for Dynamic Markets
Jan 30, 2026Dynamic pricing in high-dimensional markets poses fundamental challenges of scalability, uncertainty, and interpretability. Existing low-rank bandit formulations learn efficiently but rely on latent features that obscure how individual product attributes influence price. We address this by introducing an interpretable \emph{Additive Feature Decomposition-based Low-Dimensional Demand (\textbf{AFDLD}) model}, where product prices are expressed as the sum of attribute-level contributions and substitution effects are explicitly modeled. Building on this structure, we propose \textbf{ADEPT} (Additive DEcomposition for Pricing with cross-elasticity and Time-adaptive learning)-a projection-free, gradient-free online learning algorithm that operates directly in attribute space and achieves a sublinear regret of $\tilde{\mathcal{O}}(\sqrt{d}T^{3/4})$. Through controlled synthetic studies and real-world datasets, we show that ADEPT (i) learns near-optimal prices under dynamic market conditions, (ii) adapts rapidly to shocks and drifts, and (iii) yields transparent, attribute-level price explanations. The results demonstrate that interpretability and efficiency in autonomous pricing agents can be achieved jointly through structured, attribute-driven representations.
Transformers with Sparse Attention for Granger Causality
Nov 20, 2024
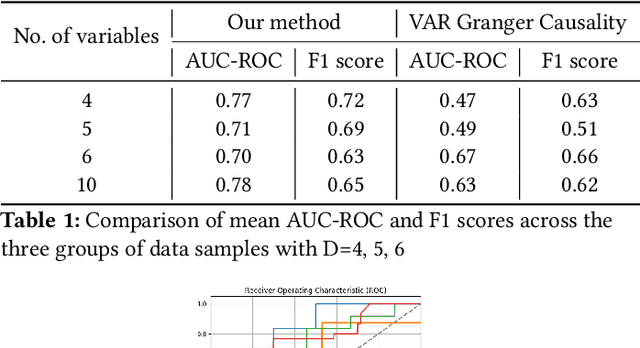
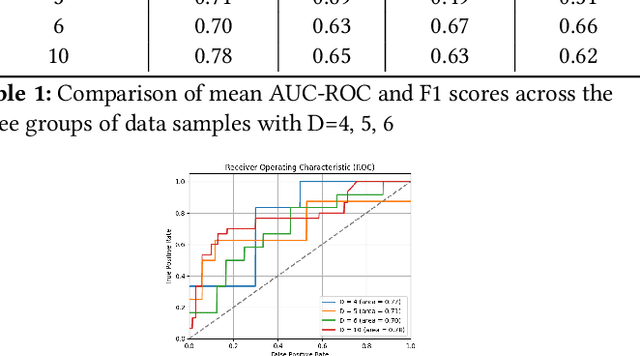
Temporal causal analysis means understanding the underlying causes behind observed variables over time. Deep learning based methods such as transformers are increasingly used to capture temporal dynamics and causal relationships beyond mere correlations. Recent works suggest self-attention weights of transformers as a useful indicator of causal links. We leverage this to propose a novel modification to the self-attention module to establish causal links between the variables of multivariate time-series data with varying lag dependencies. Our Sparse Attention Transformer captures causal relationships using a two-fold approach - performing temporal attention first followed by attention between the variables across the time steps masking them individually to compute Granger Causality indices. The key novelty in our approach is the ability of the model to assert importance and pick the most significant past time instances for its prediction task against manually feeding a fixed time lag value. We demonstrate the effectiveness of our approach via extensive experimentation on several synthetic benchmark datasets. Furthermore, we compare the performance of our model with the traditional Vector Autoregression based Granger Causality method that assumes fixed lag length.
Half-Space Feature Learning in Neural Networks
Apr 05, 2024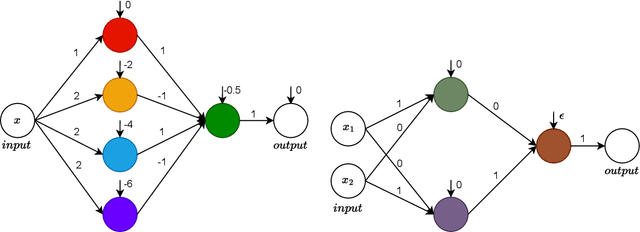



There currently exist two extreme viewpoints for neural network feature learning -- (i) Neural networks simply implement a kernel method (a la NTK) and hence no features are learned (ii) Neural networks can represent (and hence learn) intricate hierarchical features suitable for the data. We argue in this paper neither interpretation is likely to be correct based on a novel viewpoint. Neural networks can be viewed as a mixture of experts, where each expert corresponds to a (number of layers length) path through a sequence of hidden units. We use this alternate interpretation to motivate a model, called the Deep Linearly Gated Network (DLGN), which sits midway between deep linear networks and ReLU networks. Unlike deep linear networks, the DLGN is capable of learning non-linear features (which are then linearly combined), and unlike ReLU networks these features are ultimately simple -- each feature is effectively an indicator function for a region compactly described as an intersection of (number of layers) half-spaces in the input space. This viewpoint allows for a comprehensive global visualization of features, unlike the local visualizations for neurons based on saliency/activation/gradient maps. Feature learning in DLGNs is shown to happen and the mechanism with which this happens is through learning half-spaces in the input space that contain smooth regions of the target function. Due to the structure of DLGNs, the neurons in later layers are fundamentally the same as those in earlier layers -- they all represent a half-space -- however, the dynamics of gradient descent impart a distinct clustering to the later layer neurons. We hypothesize that ReLU networks also have similar feature learning behaviour.
Approximate Linear Programming and Decentralized Policy Improvement in Cooperative Multi-agent Markov Decision Processes
Nov 20, 2023



In this work, we consider a `cooperative' multi-agent Markov decision process (MDP) involving m greater than 1 agents, where all agents are aware of the system model. At each decision epoch, all the m agents cooperatively select actions in order to maximize a common long-term objective. Since the number of actions grows exponentially in the number of agents, policy improvement is computationally expensive. Recent works have proposed using decentralized policy improvement in which each agent assumes that the decisions of the other agents are fixed and it improves its decisions unilaterally. Yet, in these works, exact values are computed. In our work, for cooperative multi-agent finite and infinite horizon discounted MDPs, we propose suitable approximate policy iteration algorithms, wherein we use approximate linear programming to compute the approximate value function and use decentralized policy improvement. Thus our algorithms can handle both large number of states as well as multiple agents. We provide theoretical guarantees for our algorithms and also demonstrate the performance of our algorithms on some numerical examples.
Explicitising The Implicit Intrepretability of Deep Neural Networks Via Duality
Mar 01, 2022



Recent work by Lakshminarayanan and Singh [2020] provided a dual view for fully connected deep neural networks (DNNs) with rectified linear units (ReLU). It was shown that (i) the information in the gates is analytically characterised by a kernel called the neural path kernel (NPK) and (ii) most critical information is learnt in the gates, in that, given the learnt gates, the weights can be retrained from scratch without significant loss in performance. Using the dual view, in this paper, we rethink the conventional interpretations of DNNs thereby explicitsing the implicit interpretability of DNNs. Towards this, we first show new theoretical properties namely rotational invariance and ensemble structure of the NPK in the presence of convolutional layers and skip connections respectively. Our theory leads to two surprising empirical results that challenge conventional wisdom: (i) the weights can be trained even with a constant 1 input, (ii) the gating masks can be shuffled, without any significant loss in performance. These results motivate a novel class of networks which we call deep linearly gated networks (DLGNs). DLGNs using the phenomenon of dual lifting pave way to more direct and simpler interpretation of DNNs as opposed to conventional interpretations. We show via extensive experiments on CIFAR-10 and CIFAR-100 that these DLGNs lead to much better interpretability-accuracy tradeoff.
Disentangling deep neural networks with rectified linear units using duality
Oct 06, 2021

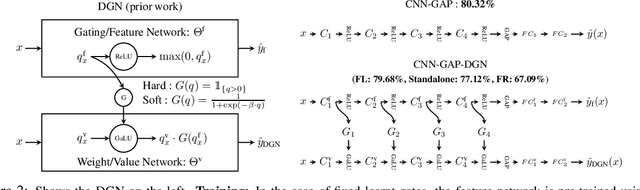
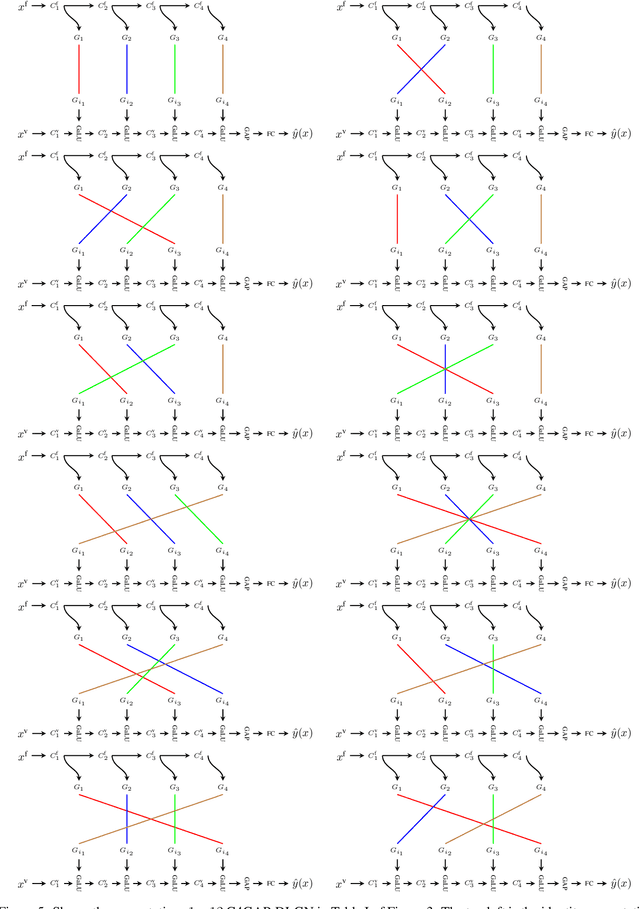
Despite their success deep neural networks (DNNs) are still largely considered as black boxes. The main issue is that the linear and non-linear operations are entangled in every layer, making it hard to interpret the hidden layer outputs. In this paper, we look at DNNs with rectified linear units (ReLUs), and focus on the gating property (`on/off' states) of the ReLUs. We extend the recently developed dual view in which the computation is broken path-wise to show that learning in the gates is more crucial, and learning the weights given the gates is characterised analytically via the so called neural path kernel (NPK) which depends on inputs and gates. In this paper, we present novel results to show that convolution with global pooling and skip connection provide respectively rotational invariance and ensemble structure to the NPK. To address `black box'-ness, we propose a novel interpretable counterpart of DNNs with ReLUs namely deep linearly gated networks (DLGN): the pre-activations to the gates are generated by a deep linear network, and the gates are then applied as external masks to learn the weights in a different network. The DLGN is not an alternative architecture per se, but a disentanglement and an interpretable re-arrangement of the computations in a DNN with ReLUs. The DLGN disentangles the computations into two `mathematically' interpretable linearities (i) the `primal' linearity between the input and the pre-activations in the gating network and (ii) the `dual' linearity in the path space in the weights network characterised by the NPK. We compare the performance of DNN, DGN and DLGN on CIFAR-10 and CIFAR-100 to show that, the DLGN recovers more than $83.5\%$ of the performance of state-of-the-art DNNs. This brings us to an interesting question: `Is DLGN a universal spectral approximator?'
Neural Path Features and Neural Path Kernel : Understanding the role of gates in deep learning
Jun 11, 2020
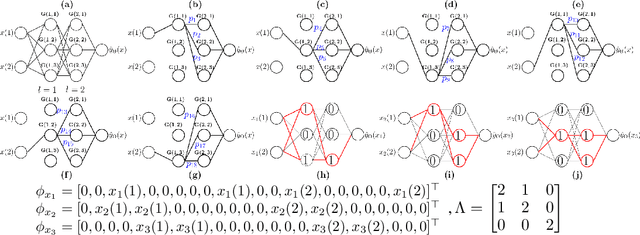

Rectified linear unit (ReLU) activations can also be thought of as \emph{gates}, which, either pass or stop their pre-activation input when they are \emph{on} (when the pre-activation input is positive) or \emph{off} (when the pre-activation input is negative) respectively. A deep neural network (DNN) with ReLU activations has many gates, and the {on/off} status of each gate changes across input examples as well as network weights. For a given input example, only a subset of gates are \emph{active}, i.e., on, and the sub-network of weights connected to these active gates is responsible for producing the output. At randomised initialisation, the active sub-network corresponding to a given input example is random. During training, as the weights are learnt, the active sub-networks are also learnt, and potentially hold very valuable information. In this paper, we analytically characterise the role of active sub-networks in deep learning. To this end, we encode the {on/off} state of the gates of a given input in a novel \emph{neural path feature} (NPF), and the weights of the DNN are encoded in a novel \emph{neural path value} (NPV). Further, we show that the output of network is indeed the inner product of NPF and NPV. The main result of the paper shows that the \emph{neural path kernel} associated with the NPF is a fundamental quantity that characterises the information stored in the gates of a DNN. We show via experiments (on MNIST and CIFAR-10) that in standard DNNs with ReLU activations NPFs are learnt during training and such learning is key for generalisation. Furthermore, NPFs and NPVs can be learnt in two separate networks and such learning also generalises well in experiments.
Deep Gated Networks: A framework to understand training and generalisation in deep learning
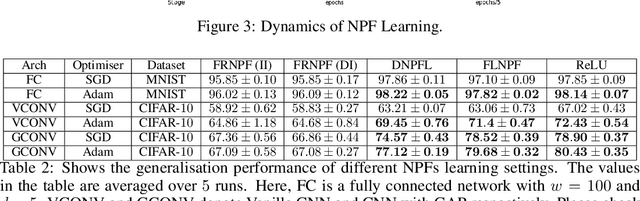
Mar 02, 2020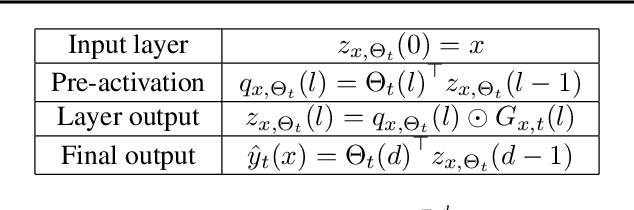
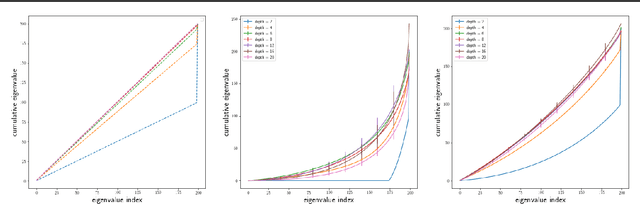
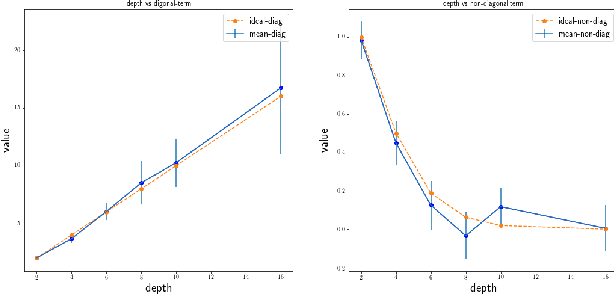

Understanding the role of (stochastic) gradient descent (SGD) in the training and generalisation of deep neural networks (DNNs) with ReLU activation has been the object study in the recent past. In this paper, we make use of deep gated networks (DGNs) as a framework to obtain insights about DNNs with ReLU activation. In DGNs, a single neuronal unit has two components namely the pre-activation input (equal to the inner product the weights of the layer and the previous layer outputs), and a gating value which belongs to $[0,1]$ and the output of the neuronal unit is equal to the multiplication of pre-activation input and the gating value. The standard DNN with ReLU activation, is a special case of the DGNs, wherein the gating value is $1/0$ based on whether or not the pre-activation input is positive or negative. We theoretically analyse and experiment with several variants of DGNs, each variant suited to understand a particular aspect of either training or generalisation in DNNs with ReLU activation. Our theory throws light on two questions namely i) why increasing depth till a point helps in training and ii) why increasing depth beyond a point hurts training? We also present experimental evidence to show that gate adaptation, i.e., the change of gating value through the course of training is key for generalisation.
Linear Stochastic Approximation: Constant Step-Size and Iterate Averaging
Sep 12, 2017
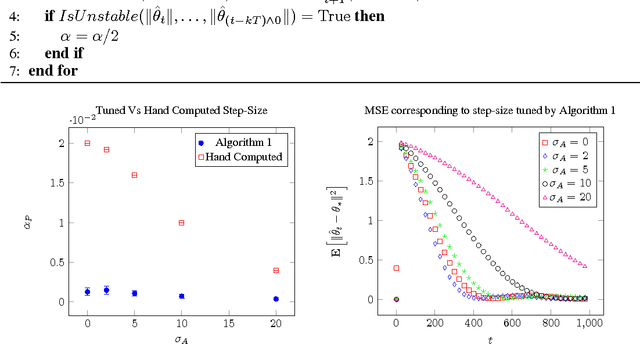
We consider $d$-dimensional linear stochastic approximation algorithms (LSAs) with a constant step-size and the so called Polyak-Ruppert (PR) averaging of iterates. LSAs are widely applied in machine learning and reinforcement learning (RL), where the aim is to compute an appropriate $\theta_{*} \in \mathbb{R}^d$ (that is an optimum or a fixed point) using noisy data and $O(d)$ updates per iteration. In this paper, we are motivated by the problem (in RL) of policy evaluation from experience replay using the \emph{temporal difference} (TD) class of learning algorithms that are also LSAs. For LSAs with a constant step-size, and PR averaging, we provide bounds for the mean squared error (MSE) after $t$ iterations. We assume that data is \iid with finite variance (underlying distribution being $P$) and that the expected dynamics is Hurwitz. For a given LSA with PR averaging, and data distribution $P$ satisfying the said assumptions, we show that there exists a range of constant step-sizes such that its MSE decays as $O(\frac{1}{t})$. We examine the conditions under which a constant step-size can be chosen uniformly for a class of data distributions $\mathcal{P}$, and show that not all data distributions `admit' such a uniform constant step-size. We also suggest a heuristic step-size tuning algorithm to choose a constant step-size of a given LSA for a given data distribution $P$. We compare our results with related work and also discuss the implication of our results in the context of TD algorithms that are LSAs.