 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers with Sparse Attention for Granger Causality
Nov 20, 2024
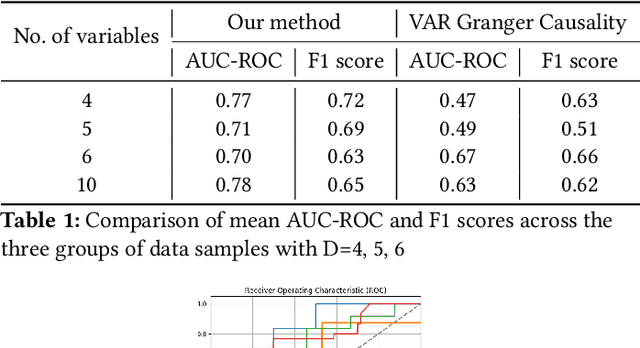
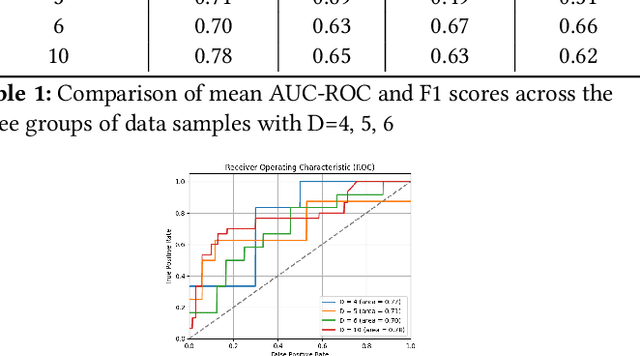
Temporal causal analysis means understanding the underlying causes behind observed variables over time. Deep learning based methods such as transformers are increasingly used to capture temporal dynamics and causal relationships beyond mere correlations. Recent works suggest self-attention weights of transformers as a useful indicator of causal links. We leverage this to propose a novel modification to the self-attention module to establish causal links between the variables of multivariate time-series data with varying lag dependencies. Our Sparse Attention Transformer captures causal relationships using a two-fold approach - performing temporal attention first followed by attention between the variables across the time steps masking them individually to compute Granger Causality indices. The key novelty in our approach is the ability of the model to assert importance and pick the most significant past time instances for its prediction task against manually feeding a fixed time lag value. We demonstrate the effectiveness of our approach via extensive experimentation on several synthetic benchmark datasets. Furthermore, we compare the performance of our model with the traditional Vector Autoregression based Granger Causality method that assumes fixed lag length.
Impact of Label Noise on Learning Complex Features
Nov 07, 2024



Neural networks trained with stochastic gradient descent exhibit an inductive bias towards simpler decision boundaries, typically converging to a narrow family of functions, and often fail to capture more complex features. This phenomenon raises concerns about the capacity of deep models to adequately learn and represent real-world datasets. Traditional approaches such as explicit regularization, data augmentation, architectural modifications, etc., have largely proven ineffective in encouraging the models to learn diverse features. In this work, we investigate the impact of pre-training models with noisy labels on the dynamics of SGD across various architectures and datasets. We show that pretraining promotes learning complex functions and diverse features in the presence of noise. Our experiments demonstrate that pre-training with noisy labels encourages gradient descent to find alternate minima that do not solely depend upon simple features, rather learns more complex and broader set of features, without hurting performance.
On the Learning Dynamics of Attention Networks
Jul 26, 2023Attention models are typically learned by optimizing one of three standard loss functions that are variously called -- soft attention, hard attention, and latent variable marginal likelihood (LVML) attention. All three paradigms are motivated by the same goal of finding two models -- a `focus' model that `selects' the right \textit{segment} of the input and a `classification' model that processes the selected segment into the target label. However, they differ significantly in the way the selected segments are aggregated, resulting in distinct dynamics and final results. We observe a unique signature of models learned using these paradigms and explain this as a consequence of the evolution of the classification model under gradient descent when the focus model is fixed. We also analyze these paradigms in a simple setting and derive closed-form expressions for the parameter trajectory under gradient flow. With the soft attention loss, the focus model improves quickly at initialization and splutters later on. On the other hand, hard attention loss behaves in the opposite fashion. Based on our observations, we propose a simple hybrid approach that combines the advantages of the different loss functions and demonstrates it on a collection of semi-synthetic and real-world datasets
On the Interpretability of Attention Networks
Dec 30, 2022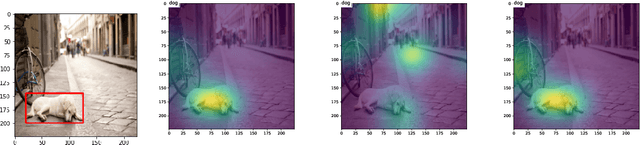

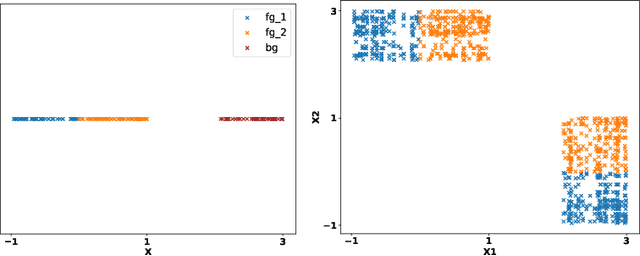

Attention mechanisms form a core component of several successful deep learning architectures, and are based on one key idea: ''The output depends only on a small (but unknown) segment of the input.'' In several practical applications like image captioning and language translation, this is mostly true. In trained models with an attention mechanism, the outputs of an intermediate module that encodes the segment of input responsible for the output is often used as a way to peek into the `reasoning` of the network. We make such a notion more precise for a variant of the classification problem that we term selective dependence classification (SDC) when used with attention model architectures. Under such a setting, we demonstrate various error modes where an attention model can be accurate but fail to be interpretable, and show that such models do occur as a result of training. We illustrate various situations that can accentuate and mitigate this behaviour. Finally, we use our objective definition of interpretability for SDC tasks to evaluate a few attention model learning algorithms designed to encourage sparsity and demonstrate that these algorithms help improve interpretability.
Using noise resilience for ranking generalization of deep neural networks
Dec 16, 2020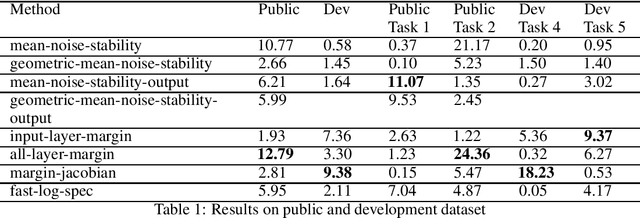
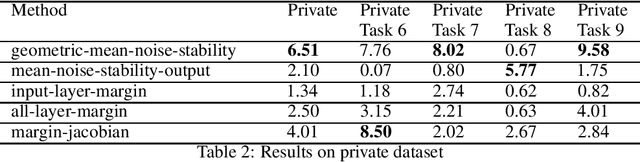
Recent papers have shown that sufficiently overparameterized neural networks can perfectly fit even random labels. Thus, it is crucial to understand the underlying reason behind the generalization performance of a network on real-world data. In this work, we propose several measures to predict the generalization error of a network given the training data and its parameters. Using one of these measures, based on noise resilience of the network, we secured 5th position in the predicting generalization in deep learning (PGDL) competition at NeurIPS 2020.
Structural Health Monitoring of Cantilever Beam, a Case Study -- Using Bayesian Neural Network AND Deep Learning
Aug 17, 2019



The advancement of machine learning algorithms has opened a wide scope for vibration-based SHM (Structural Health Monitoring). Vibration-based SHM is based on the fact that damage will alter the dynamic properties viz., structural response, frequencies, mode shapes, etc of the structure. The responses measured using sensors, which are high dimensional in nature, can be intelligently analyzed using machine learning techniques for damage assessment. Neural networks employing multilayer architectures are expressive models capable of capturing complex relationships between input-output pairs but do not account for uncertainty in network outputs. A BNN (Bayesian Neural Network) refers to extending standard networks with posterior inference. It is a neural network with a prior distribution on its weights. Deep learning architectures like CNN (Convolutional neural network) and LSTM(Long Short Term Memory) are good candidates for representation learning from high dimensional data. The advantage of using CNN over multi-layer neural networks is that they are good feature extractors as well as classifiers, which eliminates the need for generating hand-engineered features. LSTM networks are mainly used for sequence modeling. This paper presents both a Bayesian multi-layer perceptron and deep learning-based approach for damage detection and location identification in beam-like structures. Raw frequency response data simulated using finite element analysis is fed as the input of the network. As part of this, frequency response was generated for a series of simulations in the cantilever beam involving different damage scenarios. This case study shows the effectiveness of the above approaches to predict bending rigidity with an acceptable error rate.