 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Stochastic Approximation: Constant Step-Size and Iterate Averaging
Paper and Code
Sep 12, 2017
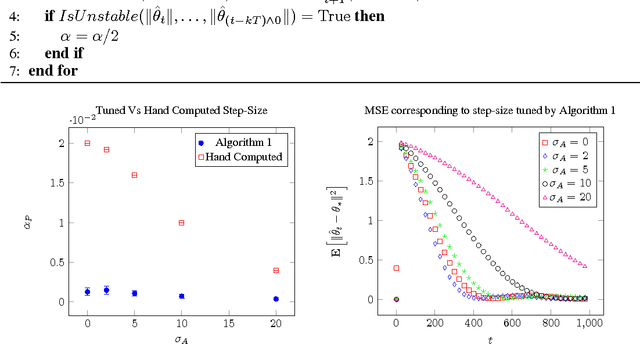
We consider $d$-dimensional linear stochastic approximation algorithms (LSAs) with a constant step-size and the so called Polyak-Ruppert (PR) averaging of iterates. LSAs are widely applied in machine learning and reinforcement learning (RL), where the aim is to compute an appropriate $\theta_{*} \in \mathbb{R}^d$ (that is an optimum or a fixed point) using noisy data and $O(d)$ updates per iteration. In this paper, we are motivated by the problem (in RL) of policy evaluation from experience replay using the \emph{temporal difference} (TD) class of learning algorithms that are also LSAs. For LSAs with a constant step-size, and PR averaging, we provide bounds for the mean squared error (MSE) after $t$ iterations. We assume that data is \iid with finite variance (underlying distribution being $P$) and that the expected dynamics is Hurwitz. For a given LSA with PR averaging, and data distribution $P$ satisfying the said assumptions, we show that there exists a range of constant step-sizes such that its MSE decays as $O(\frac{1}{t})$. We examine the conditions under which a constant step-size can be chosen uniformly for a class of data distributions $\mathcal{P}$, and show that not all data distributions `admit' such a uniform constant step-size. We also suggest a heuristic step-size tuning algorithm to choose a constant step-size of a given LSA for a given data distribution $P$. We compare our results with related work and also discuss the implication of our results in the context of TD algorithms that are LSAs.