 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplicitising The Implicit Intrepretability of Deep Neural Networks Via Duality
Mar 01, 2022



Recent work by Lakshminarayanan and Singh [2020] provided a dual view for fully connected deep neural networks (DNNs) with rectified linear units (ReLU). It was shown that (i) the information in the gates is analytically characterised by a kernel called the neural path kernel (NPK) and (ii) most critical information is learnt in the gates, in that, given the learnt gates, the weights can be retrained from scratch without significant loss in performance. Using the dual view, in this paper, we rethink the conventional interpretations of DNNs thereby explicitsing the implicit interpretability of DNNs. Towards this, we first show new theoretical properties namely rotational invariance and ensemble structure of the NPK in the presence of convolutional layers and skip connections respectively. Our theory leads to two surprising empirical results that challenge conventional wisdom: (i) the weights can be trained even with a constant 1 input, (ii) the gating masks can be shuffled, without any significant loss in performance. These results motivate a novel class of networks which we call deep linearly gated networks (DLGNs). DLGNs using the phenomenon of dual lifting pave way to more direct and simpler interpretation of DNNs as opposed to conventional interpretations. We show via extensive experiments on CIFAR-10 and CIFAR-100 that these DLGNs lead to much better interpretability-accuracy tradeoff.
Disentangling deep neural networks with rectified linear units using duality
Oct 06, 2021

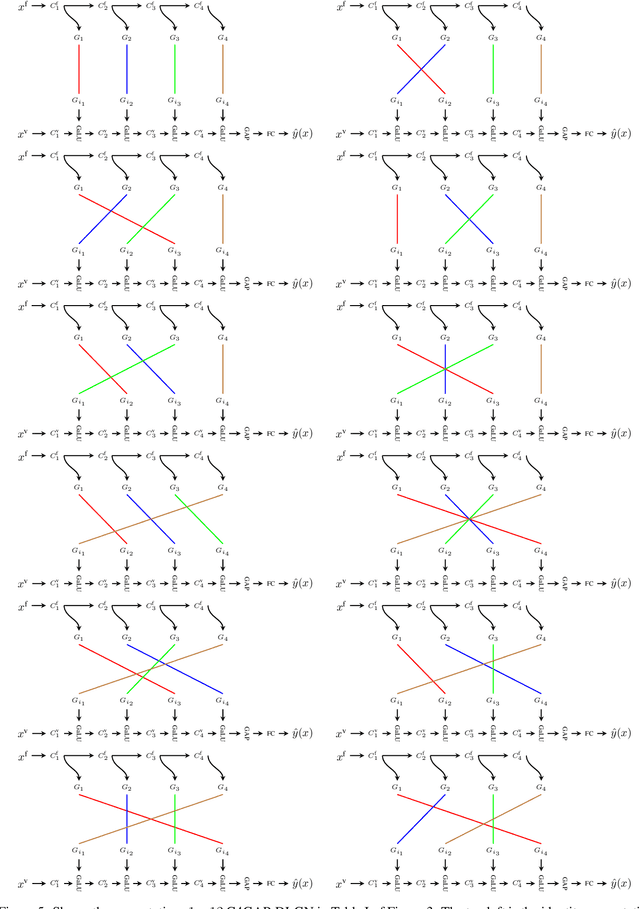
Despite their success deep neural networks (DNNs) are still largely considered as black boxes. The main issue is that the linear and non-linear operations are entangled in every layer, making it hard to interpret the hidden layer outputs. In this paper, we look at DNNs with rectified linear units (ReLUs), and focus on the gating property (`on/off' states) of the ReLUs. We extend the recently developed dual view in which the computation is broken path-wise to show that learning in the gates is more crucial, and learning the weights given the gates is characterised analytically via the so called neural path kernel (NPK) which depends on inputs and gates. In this paper, we present novel results to show that convolution with global pooling and skip connection provide respectively rotational invariance and ensemble structure to the NPK. To address `black box'-ness, we propose a novel interpretable counterpart of DNNs with ReLUs namely deep linearly gated networks (DLGN): the pre-activations to the gates are generated by a deep linear network, and the gates are then applied as external masks to learn the weights in a different network. The DLGN is not an alternative architecture per se, but a disentanglement and an interpretable re-arrangement of the computations in a DNN with ReLUs. The DLGN disentangles the computations into two `mathematically' interpretable linearities (i) the `primal' linearity between the input and the pre-activations in the gating network and (ii) the `dual' linearity in the path space in the weights network characterised by the NPK. We compare the performance of DNN, DGN and DLGN on CIFAR-10 and CIFAR-100 to show that, the DLGN recovers more than $83.5\%$ of the performance of state-of-the-art DNNs. This brings us to an interesting question: `Is DLGN a universal spectral approximator?'
Neural Path Features and Neural Path Kernel : Understanding the role of gates in deep learning
Jun 11, 2020
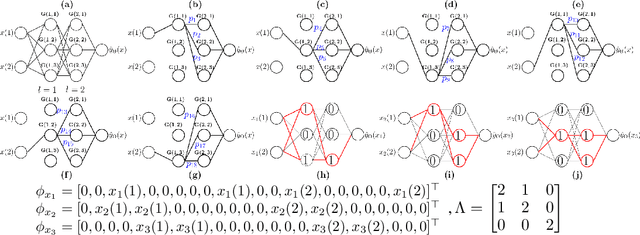

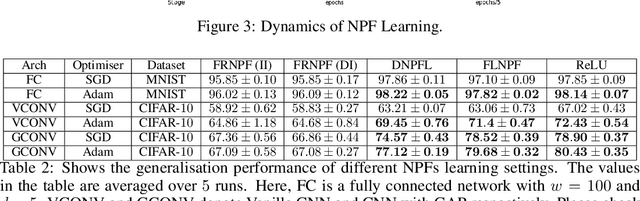
Rectified linear unit (ReLU) activations can also be thought of as \emph{gates}, which, either pass or stop their pre-activation input when they are \emph{on} (when the pre-activation input is positive) or \emph{off} (when the pre-activation input is negative) respectively. A deep neural network (DNN) with ReLU activations has many gates, and the {on/off} status of each gate changes across input examples as well as network weights. For a given input example, only a subset of gates are \emph{active}, i.e., on, and the sub-network of weights connected to these active gates is responsible for producing the output. At randomised initialisation, the active sub-network corresponding to a given input example is random. During training, as the weights are learnt, the active sub-networks are also learnt, and potentially hold very valuable information. In this paper, we analytically characterise the role of active sub-networks in deep learning. To this end, we encode the {on/off} state of the gates of a given input in a novel \emph{neural path feature} (NPF), and the weights of the DNN are encoded in a novel \emph{neural path value} (NPV). Further, we show that the output of network is indeed the inner product of NPF and NPV. The main result of the paper shows that the \emph{neural path kernel} associated with the NPF is a fundamental quantity that characterises the information stored in the gates of a DNN. We show via experiments (on MNIST and CIFAR-10) that in standard DNNs with ReLU activations NPFs are learnt during training and such learning is key for generalisation. Furthermore, NPFs and NPVs can be learnt in two separate networks and such learning also generalises well in experiments.
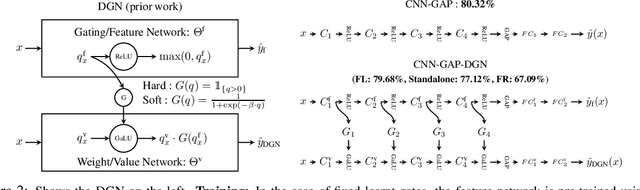
Deep Gated Networks: A framework to understand training and generalisation in deep learning
Mar 02, 2020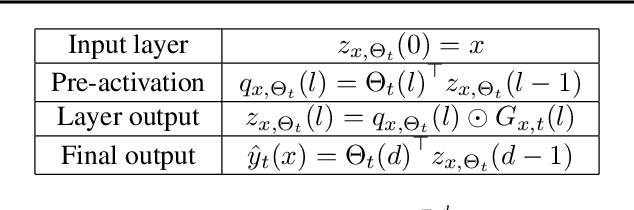
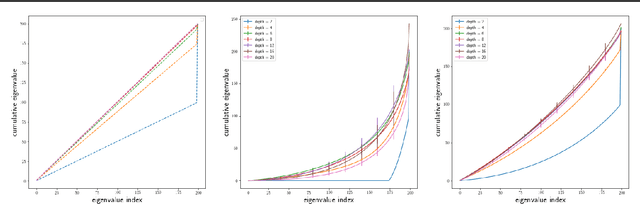
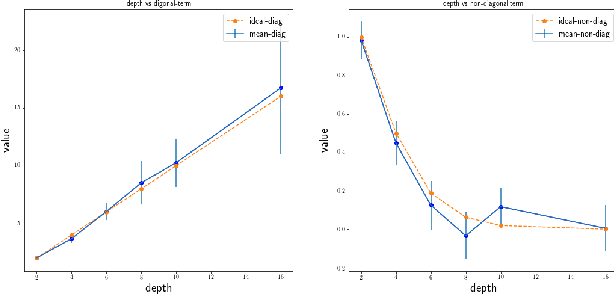

Understanding the role of (stochastic) gradient descent (SGD) in the training and generalisation of deep neural networks (DNNs) with ReLU activation has been the object study in the recent past. In this paper, we make use of deep gated networks (DGNs) as a framework to obtain insights about DNNs with ReLU activation. In DGNs, a single neuronal unit has two components namely the pre-activation input (equal to the inner product the weights of the layer and the previous layer outputs), and a gating value which belongs to $[0,1]$ and the output of the neuronal unit is equal to the multiplication of pre-activation input and the gating value. The standard DNN with ReLU activation, is a special case of the DGNs, wherein the gating value is $1/0$ based on whether or not the pre-activation input is positive or negative. We theoretically analyse and experiment with several variants of DGNs, each variant suited to understand a particular aspect of either training or generalisation in DNNs with ReLU activation. Our theory throws light on two questions namely i) why increasing depth till a point helps in training and ii) why increasing depth beyond a point hurts training? We also present experimental evidence to show that gate adaptation, i.e., the change of gating value through the course of training is key for generalisation.