 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Negatives for Siamese Architectures
Aug 06, 2019

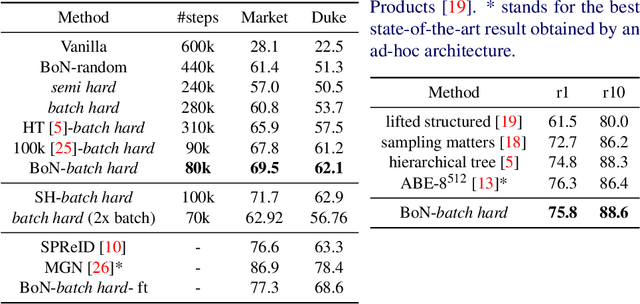
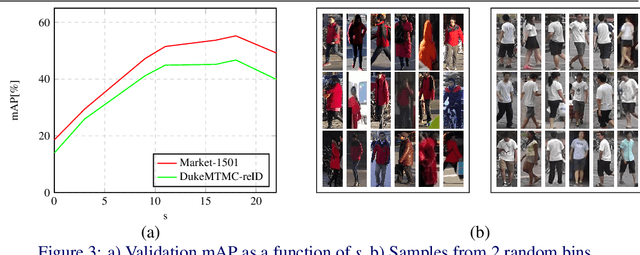
Training a Siamese architecture for re-identification with a large number of identities is a challenging task due to the difficulty of finding relevant negative samples efficiently. In this work we present Bag of Negatives (BoN), a method for accelerated and improved training of Siamese networks that scales well on datasets with a very large number of identities. BoN is an efficient and loss-independent method, able to select a bag of high quality negatives, based on a novel online hashing strategy.
Unsupervised Deep Feature Extraction for Remote Sensing Image Classification
Nov 25, 2015
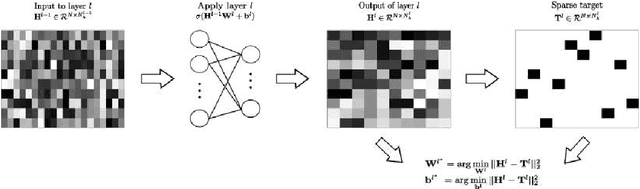

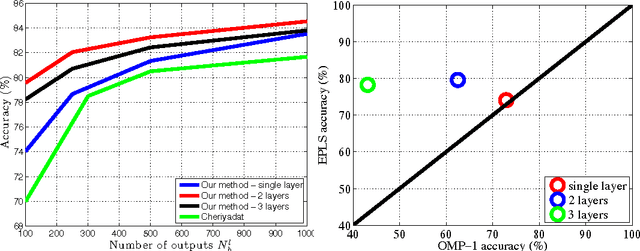
This paper introduces the use of single layer and deep convolutional networks for remote sensing data analysis. Direct application to multi- and hyper-spectral imagery of supervised (shallow or deep) convolutional networks is very challenging given the high input data dimensionality and the relatively small amount of available labeled data. Therefore, we propose the use of greedy layer-wise unsupervised pre-training coupled with a highly efficient algorithm for unsupervised learning of sparse features. The algorithm is rooted on sparse representations and enforces both population and lifetime sparsity of the extracted features, simultaneously. We successfully illustrate the expressive power of the extracted representations in several scenarios: classification of aerial scenes, as well as land-use classification in very high resolution (VHR), or land-cover classification from multi- and hyper-spectral images. The proposed algorithm clearly outperforms standard Principal Component Analysis (PCA) and its kernel counterpart (kPCA), as well as current state-of-the-art algorithms of aerial classification, while being extremely computationally efficient at learning representations of data. Results show that single layer convolutional networks can extract powerful discriminative features only when the receptive field accounts for neighboring pixels, and are preferred when the classification requires high resolution and detailed results. However, deep architectures significantly outperform single layers variants, capturing increasing levels of abstraction and complexity throughout the feature hierarchy.
FitNets: Hints for Thin Deep Nets
Mar 27, 2015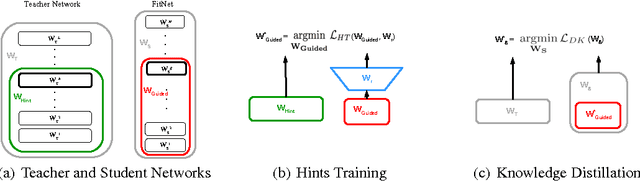
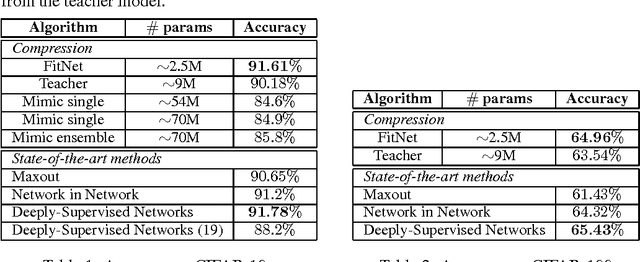
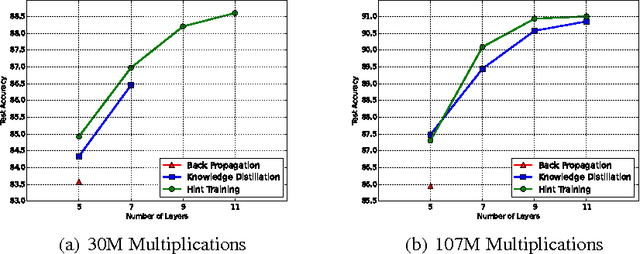
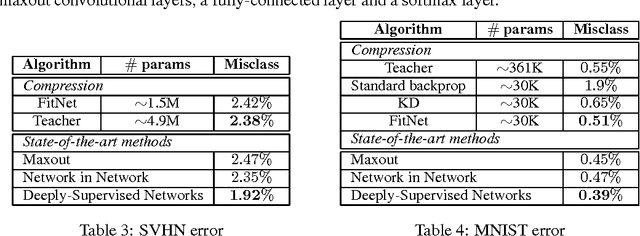
While depth tends to improve network performances, it also makes gradient-based training more difficult since deeper networks tend to be more non-linear. The recently proposed knowledge distillation approach is aimed at obtaining small and fast-to-execute models, and it has shown that a student network could imitate the soft output of a larger teacher network or ensemble of networks. In this paper, we extend this idea to allow the training of a student that is deeper and thinner than the teacher, using not only the outputs but also the intermediate representations learned by the teacher as hints to improve the training process and final performance of the student. Because the student intermediate hidden layer will generally be smaller than the teacher's intermediate hidden layer, additional parameters are introduced to map the student hidden layer to the prediction of the teacher hidden layer. This allows one to train deeper students that can generalize better or run faster, a trade-off that is controlled by the chosen student capacity. For example, on CIFAR-10, a deep student network with almost 10.4 times less parameters outperforms a larger, state-of-the-art teacher network.
No more meta-parameter tuning in unsupervised sparse feature learning
Feb 24, 2014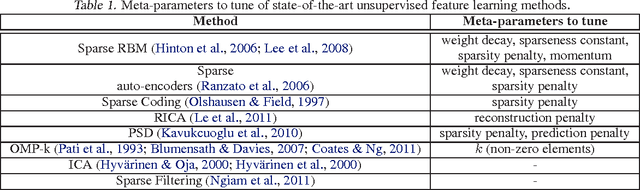

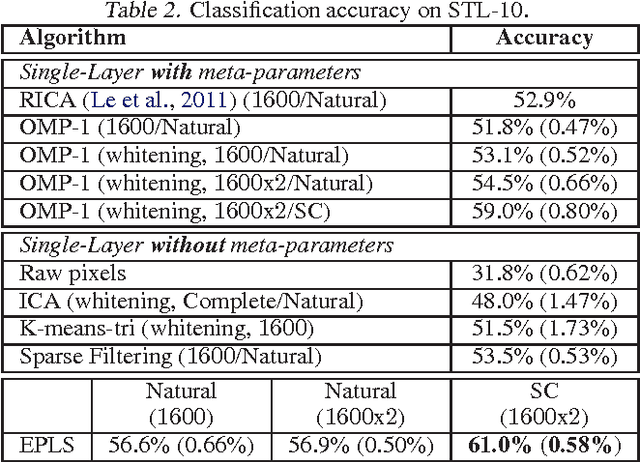
We propose a meta-parameter free, off-the-shelf, simple and fast unsupervised feature learning algorithm, which exploits a new way of optimizing for sparsity. Experiments on STL-10 show that the method presents state-of-the-art performance and provides discriminative features that generalize well.