 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Disentangled Representation Learning with the Beta Bernoulli Process
Sep 03, 2019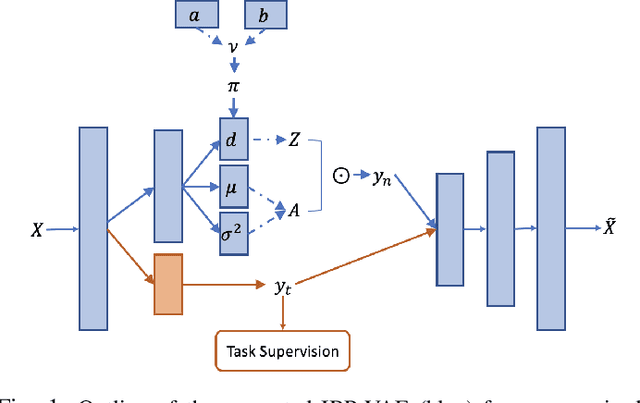
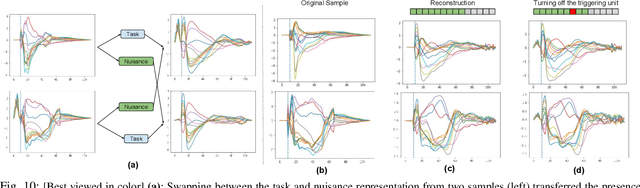


To improve the ability of VAE to disentangle in the latent space, existing works mostly focus on enforcing independence among the learned latent factors. However, the ability of these models to disentangle often decreases as the complexity of the generative factors increases. In this paper, we investigate the little-explored effect of the modeling capacity of a posterior density on the disentangling ability of the VAE. We note that the independence within and the complexity of the latent density are two different properties we constrain when regularizing the posterior density: while the former promotes the disentangling ability of VAE, the latter -- if overly limited -- creates an unnecessary competition with the data reconstruction objective in VAE. Therefore, if we preserve the independence but allow richer modeling capacity in the posterior density, we will lift this competition and thereby allow improved independence and data reconstruction at the same time. We investigate this theoretical intuition with a VAE that utilizes a non-parametric latent factor model, the Indian Buffet Process (IBP), as a latent density that is able to grow with the complexity of the data. Across three widely-used benchmark data sets and two clinical data sets little explored for disentangled learning, we qualitatively and quantitatively demonstrated the improved disentangling performance of IBP-VAE over the state of the art. In the latter two clinical data sets riddled with complex factors of variations, we further demonstrated that unsupervised disentangling of nuisance factors via IBP-VAE -- when combined with a supervised objective -- can not only improve task accuracy in comparison to relevant supervised deep architectures but also facilitate knowledge discovery related to task decision-making. A shorter version of this work will appear in the ICDM 2019 conference proceedings.
Deep Generative Model with Beta Bernoulli Process for Modeling and Learning Confounding Factors
Oct 31, 2018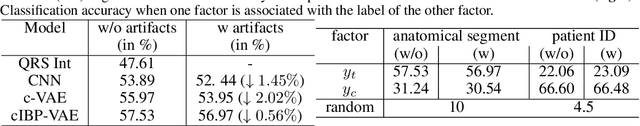
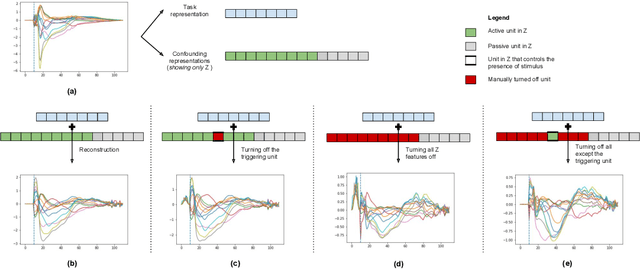


While deep representation learning has become increasingly capable of separating task-relevant representations from other confounding factors in the data, two significant challenges remain. First, there is often an unknown and potentially infinite number of confounding factors coinciding in the data. Second, not all of these factors are readily observable. In this paper, we present a deep conditional generative model that learns to disentangle a task-relevant representation from an unknown number of confounding factors that may grow infinitely. This is achieved by marrying the representational power of deep generative models with Bayesian non-parametric factor models, where a supervised deterministic encoder learns task-related representation and a probabilistic encoder with an Indian Buffet Process (IBP) learns the unknown number of unobservable confounding factors. We tested the presented model in two datasets: a handwritten digit dataset (MNIST) augmented with colored digits and a clinical ECG dataset with significant inter-subject variations and augmented with signal artifacts. These diverse data sets highlighted the ability of the presented model to grow with the complexity of the data and identify the absence or presence of unobserved confounding factors.