 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdating the silent speech challenge benchmark with deep learning
Sep 20, 2017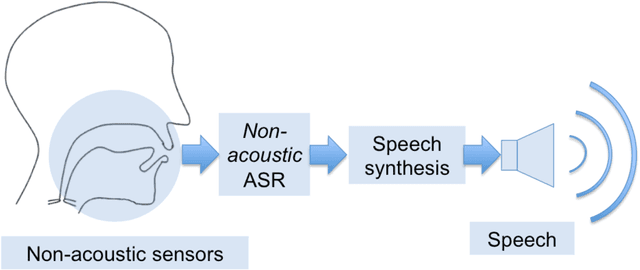
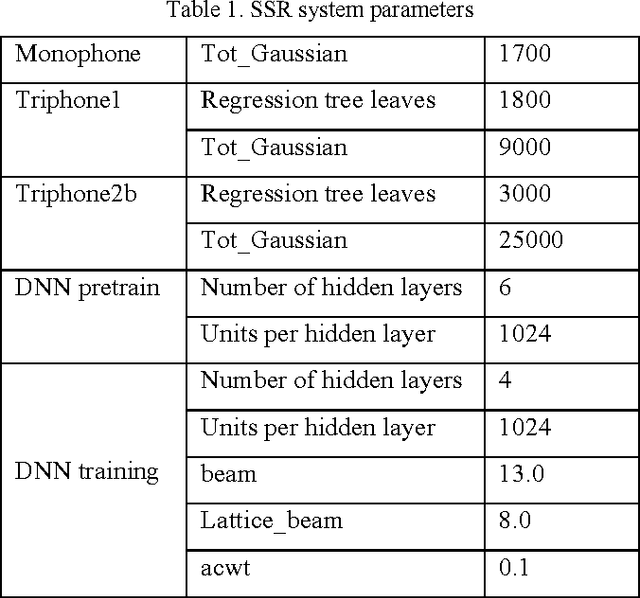
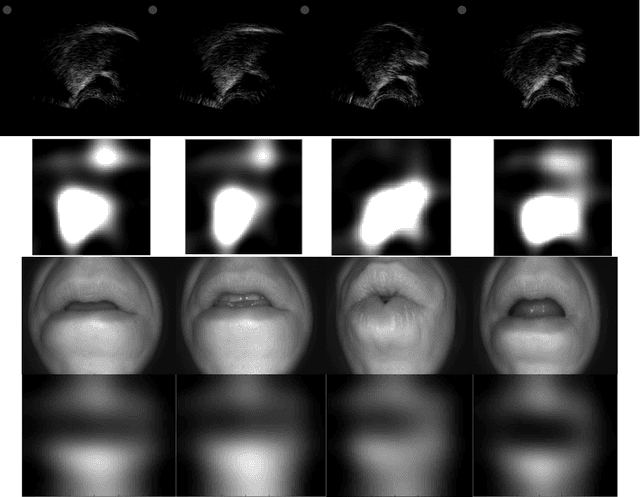
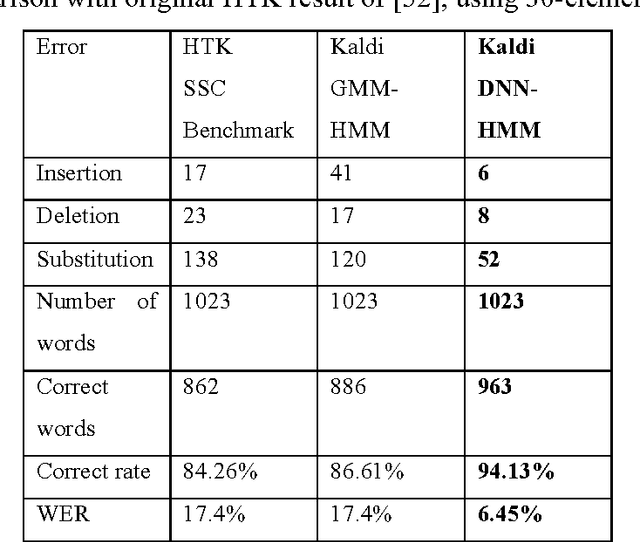
The 2010 Silent Speech Challenge benchmark is updated with new results obtained in a Deep Learning strategy, using the same input features and decoding strategy as in the original article. A Word Error Rate of 6.4% is obtained, compared to the published value of 17.4%. Additional results comparing new auto-encoder-based features with the original features at reduced dimensionality, as well as decoding scenarios on two different language models, are also presented. The Silent Speech Challenge archive has been updated to contain both the original and the new auto-encoder features, in addition to the original raw data.
Development of a 3D tongue motion visualization platform based on ultrasound image sequences
May 19, 2016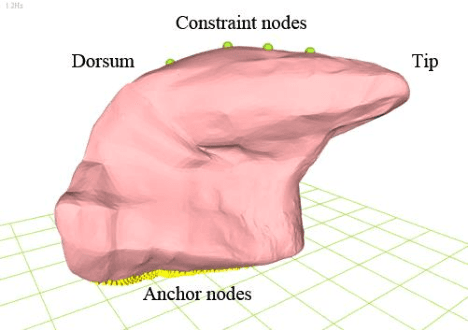
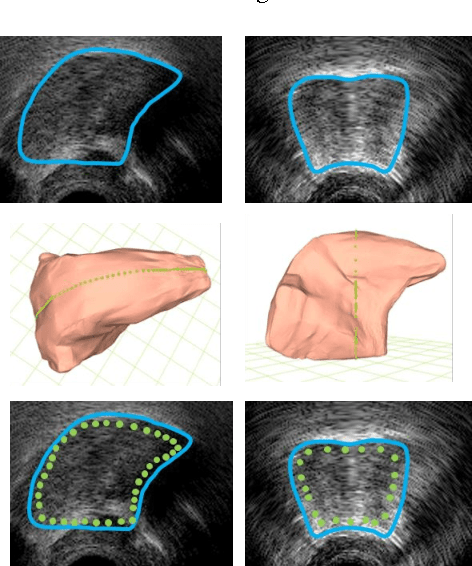

This article describes the development of a platform designed to visualize the 3D motion of the tongue using ultrasound image sequences. An overview of the system design is given and promising results are presented. Compared to the analysis of motion in 2D image sequences, such a system can provide additional visual information and a quantitative description of the tongue 3D motion. The platform can be useful in a variety of fields, such as speech production, articulation training, etc.
Contour-based 3d tongue motion visualization using ultrasound image sequences
May 19, 2016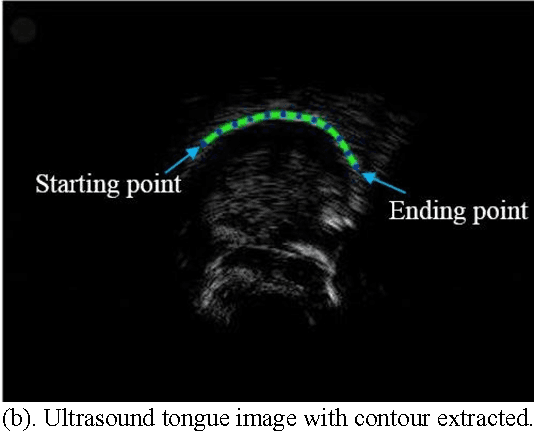
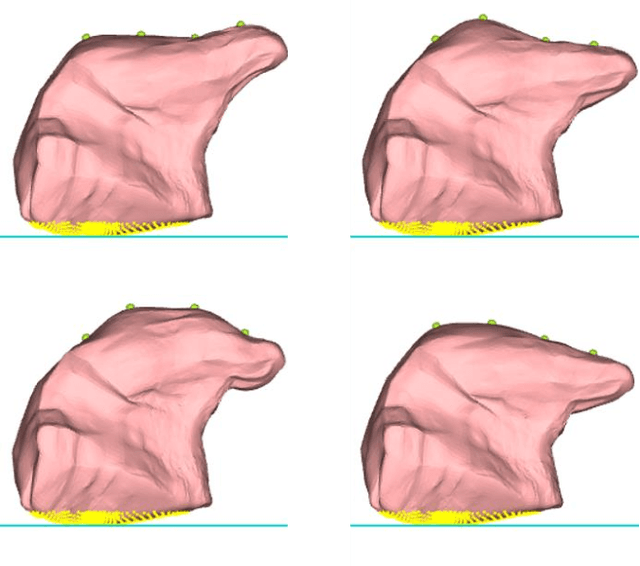
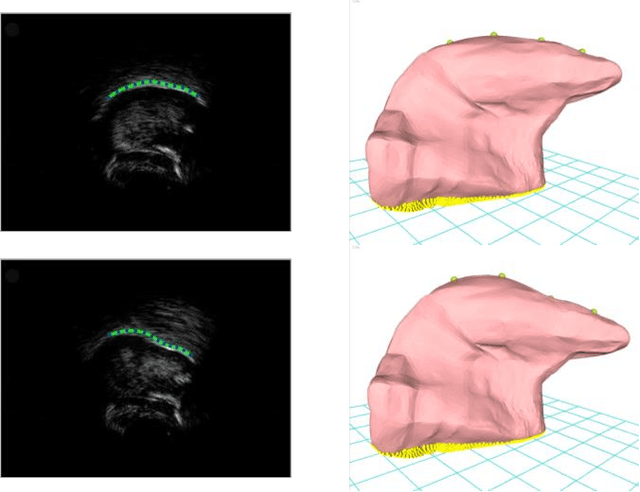
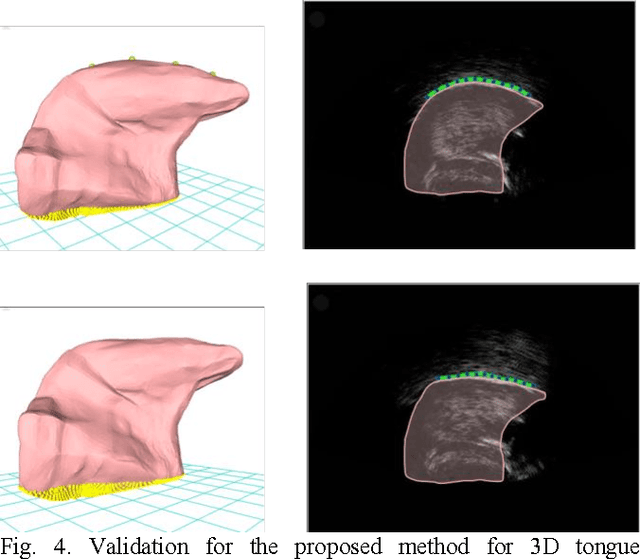
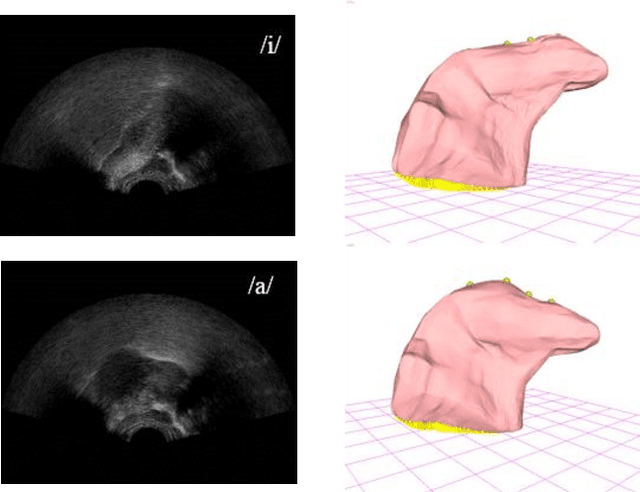
This article describes a contour-based 3D tongue deformation visualization framework using B-mode ultrasound image sequences. A robust, automatic tracking algorithm characterizes tongue motion via a contour, which is then used to drive a generic 3D Finite Element Model (FEM). A novel contour-based 3D dynamic modeling method is presented. Modal reduction and modal warping techniques are applied to model the deformation of the tongue physically and efficiently. This work can be helpful in a variety of fields, such as speech production, silent speech recognition, articulation training, speech disorder study, etc.
Tongue contour extraction from ultrasound images based on deep neural network
May 19, 2016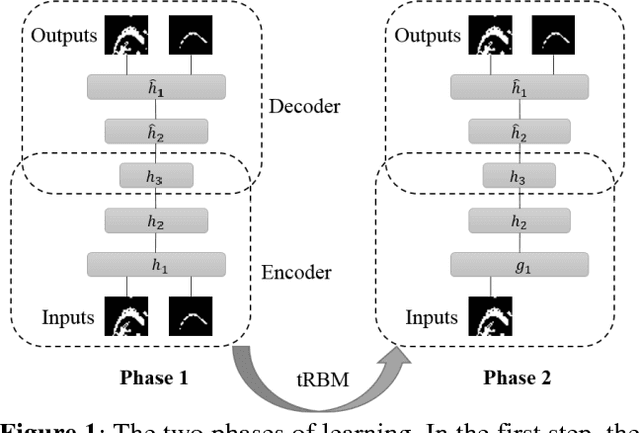


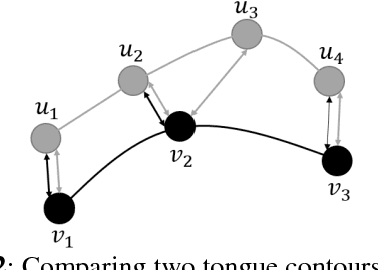
Studying tongue motion during speech using ultrasound is a standard procedure, but automatic ultrasound image labelling remains a challenge, as standard tongue shape extraction methods typically require human intervention. This article presents a method based on deep neural networks to automatically extract tongue contour from ultrasound images on a speech dataset. We use a deep autoencoder trained to learn the relationship between an image and its related contour, so that the model is able to automatically reconstruct contours from the ultrasound image alone. In this paper, we use an automatic labelling algorithm instead of time-consuming hand-labelling during the training process, and estimate the performances of both automatic labelling and contour extraction as compared to hand-labelling. Observed results show quality scores comparable to the state of the art.