Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpdating the silent speech challenge benchmark with deep learning
Sep 20, 2017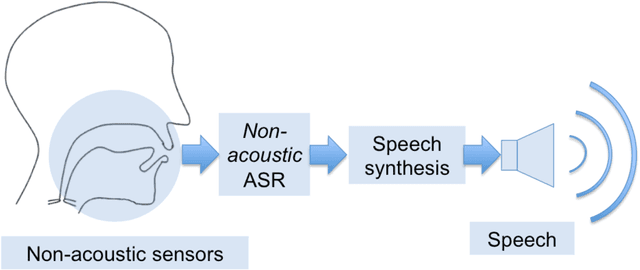
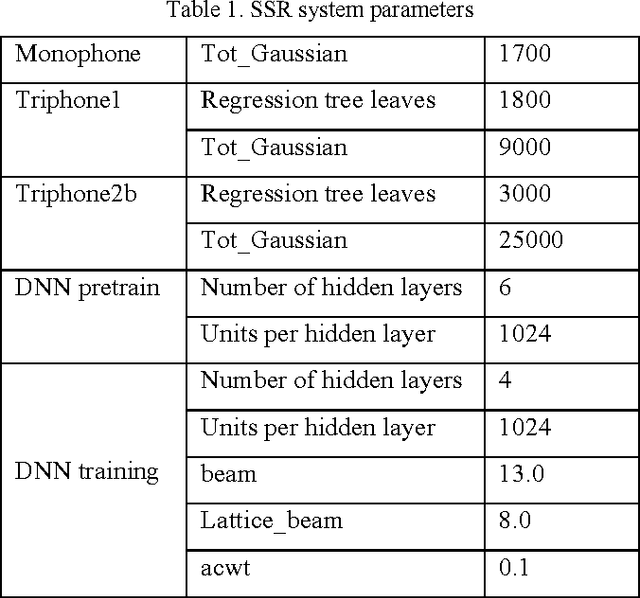
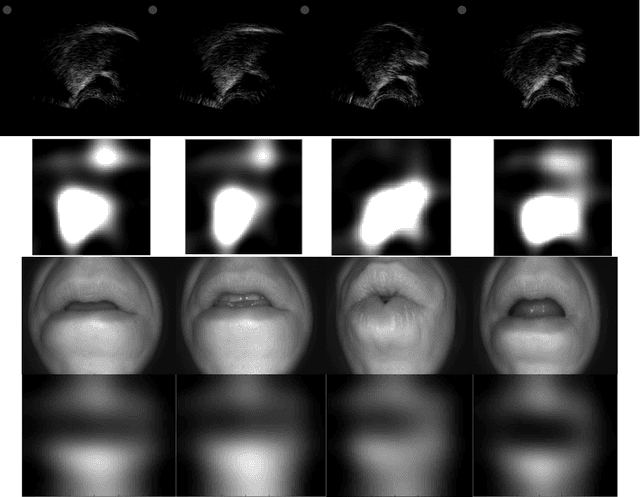
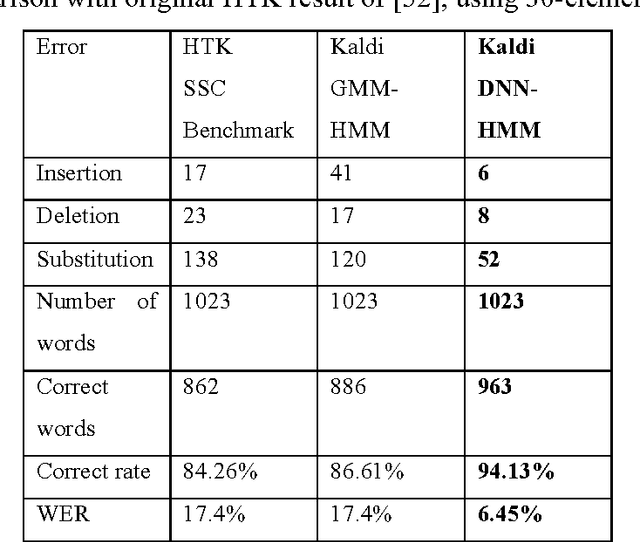
The 2010 Silent Speech Challenge benchmark is updated with new results obtained in a Deep Learning strategy, using the same input features and decoding strategy as in the original article. A Word Error Rate of 6.4% is obtained, compared to the published value of 17.4%. Additional results comparing new auto-encoder-based features with the original features at reduced dimensionality, as well as decoding scenarios on two different language models, are also presented. The Silent Speech Challenge archive has been updated to contain both the original and the new auto-encoder features, in addition to the original raw data.
* 25 pages, 6 pages
Via