 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFantastic Questions and Where to Find Them: FairytaleQA -- An Authentic Dataset for Narrative Comprehension
Mar 26, 2022


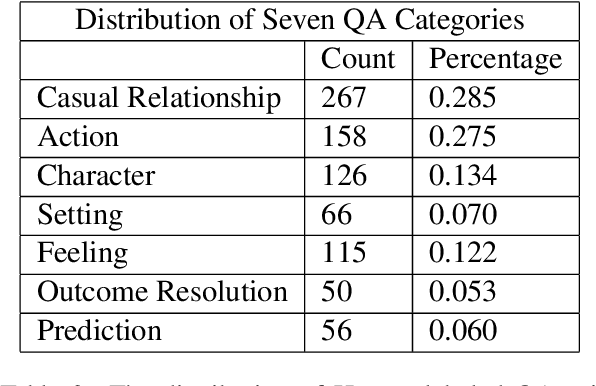
Question answering (QA) is a fundamental means to facilitate assessment and training of narrative comprehension skills for both machines and young children, yet there is scarcity of high-quality QA datasets carefully designed to serve this purpose. In particular, existing datasets rarely distinguish fine-grained reading skills, such as the understanding of varying narrative elements. Drawing on the reading education research, we introduce FairytaleQA, a dataset focusing on narrative comprehension of kindergarten to eighth-grade students. Generated by educational experts based on an evidence-based theoretical framework, FairytaleQA consists of 10,580 explicit and implicit questions derived from 278 children-friendly stories, covering seven types of narrative elements or relations. Our dataset is valuable in two folds: First, we ran existing QA models on our dataset and confirmed that this annotation helps assess models' fine-grained learning skills. Second, the dataset supports question generation (QG) task in the education domain. Through benchmarking with QG models, we show that the QG model trained on FairytaleQA is capable of asking high-quality and more diverse questions.
It is AI's Turn to Ask Human a Question: Question and Answer Pair Generation for Children Storybooks in FairytaleQA Dataset
Sep 09, 2021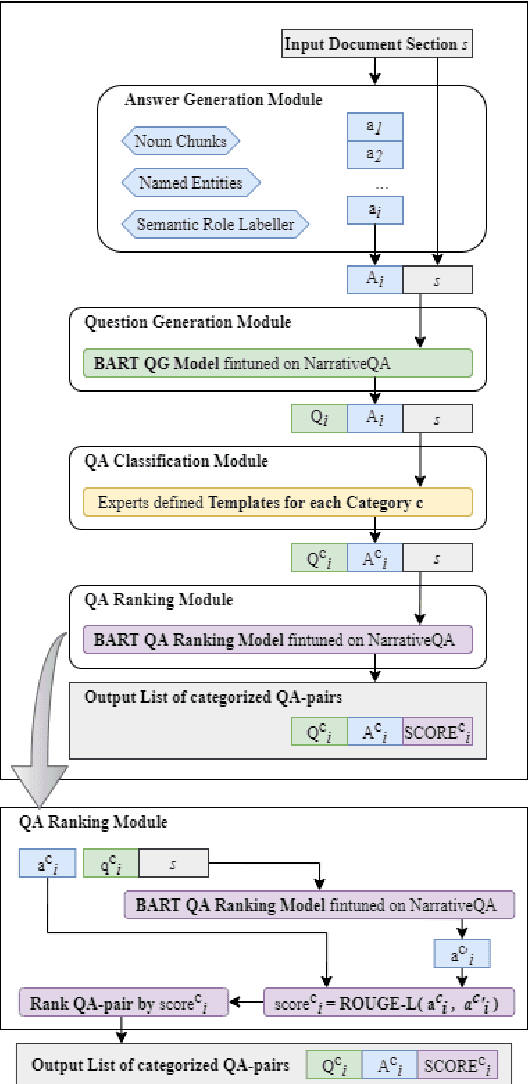


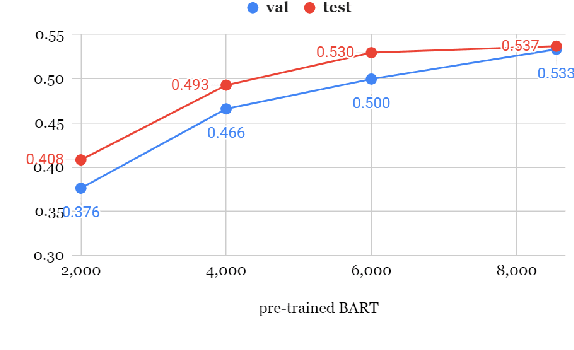
Existing question answering (QA) datasets are created mainly for the application of having AI to be able to answer questions asked by humans. But in educational applications, teachers and parents sometimes may not know what questions they should ask a child that can maximize their language learning results. With a newly released book QA dataset (FairytaleQA), which educational experts labeled on 46 fairytale storybooks for early childhood readers, we developed an automated QA generation model architecture for this novel application. Our model (1) extracts candidate answers from a given storybook passage through carefully designed heuristics based on a pedagogical framework; (2) generates appropriate questions corresponding to each extracted answer using a language model; and, (3) uses another QA model to rank top QA-pairs. Automatic and human evaluations show that our model outperforms baselines. We also demonstrate that our method can help with the scarcity issue of the children's book QA dataset via data augmentation on 200 unlabeled storybooks.