 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross-Domain Graph Learning Protocol for Single-Step Molecular Geometry Refinement
Jan 30, 2026Accurate molecular geometries are a prerequisite for reliable quantum-chemical predictions, yet density functional theory (DFT) optimization remains a major bottleneck for high-throughput molecular screening. Here we present GeoOpt-Net, a multi-branch SE(3)-equivariant geometry refinement network that predicts DFT-quality structures at the B3LYP/TZVP level of theory in a single forward pass starting from inexpensive initial conformers generated at a low-cost force-field level. GeoOpt-Net is trained using a two-stage strategy in which a broadly pretrained geometric representation is subsequently fine-tuned to approach B3LYP/TZVP-level accuracy, with theory- and basis-set-aware calibration enabled by a fidelity-aware feature modulation (FAFM) mechanism. Benchmarking against representative approaches spanning classical conformer generation (RDKit), semiempirical quantum methods (xTB), data-driven geometry refinement pipelines (Auto3D), and machine-learning interatomic potentials (UMA) on external drug-like molecules demonstrates that GeoOpt-Net achieves sub-milli-Å all-atom RMSD with near-zero B3LYP/TZVP single-point energy deviations, indicating DFT-ready geometries that closely reproduce both structural and energetic references. Beyond geometric metrics, GeoOpt-Net generates initial guesses intrinsically compatible with DFT convergence criteria, yielding nonzero ``All-YES'' convergence rates (65.0\% under loose and 33.4\% under default thresholds), and substantially reducing re-optimization steps and wall-clock time. GeoOpt-Net further exhibits smooth and predictable energy scaling with molecular complexity while preserving key electronic observables such as dipole moments. Collectively, these results establish GeoOpt-Net as a scalable, physically consistent geometry refinement framework that enables efficient acceleration of DFT-based quantum-chemical workflows.
RLogist: Fast Observation Strategy on Whole-slide Images with Deep Reinforcement Learning
Dec 13, 2022Whole-slide images (WSI) in computational pathology have high resolution with gigapixel size, but are generally with sparse regions of interest, which leads to weak diagnostic relevance and data inefficiency for each area in the slide. Most of the existing methods rely on a multiple instance learning framework that requires densely sampling local patches at high magnification. The limitation is evident in the application stage as the heavy computation for extracting patch-level features is inevitable. In this paper, we develop RLogist, a benchmarking deep reinforcement learning (DRL) method for fast observation strategy on WSIs. Imitating the diagnostic logic of human pathologists, our RL agent learns how to find regions of observation value and obtain representative features across multiple resolution levels, without having to analyze each part of the WSI at the high magnification. We benchmark our method on two whole-slide level classification tasks, including detection of metastases in WSIs of lymph node sections, and subtyping of lung cancer. Experimental results demonstrate that RLogist achieves competitive classification performance compared to typical multiple instance learning algorithms, while having a significantly short observation path. In addition, the observation path given by RLogist provides good decision-making interpretability, and its ability of reading path navigation can potentially be used by pathologists for educational/assistive purposes. Our code is available at: \url{https://github.com/tencent-ailab/RLogist}.
Fusing Motion Patterns and Key Visual Information for Semantic Event Recognition in Basketball Videos
Jul 13, 2020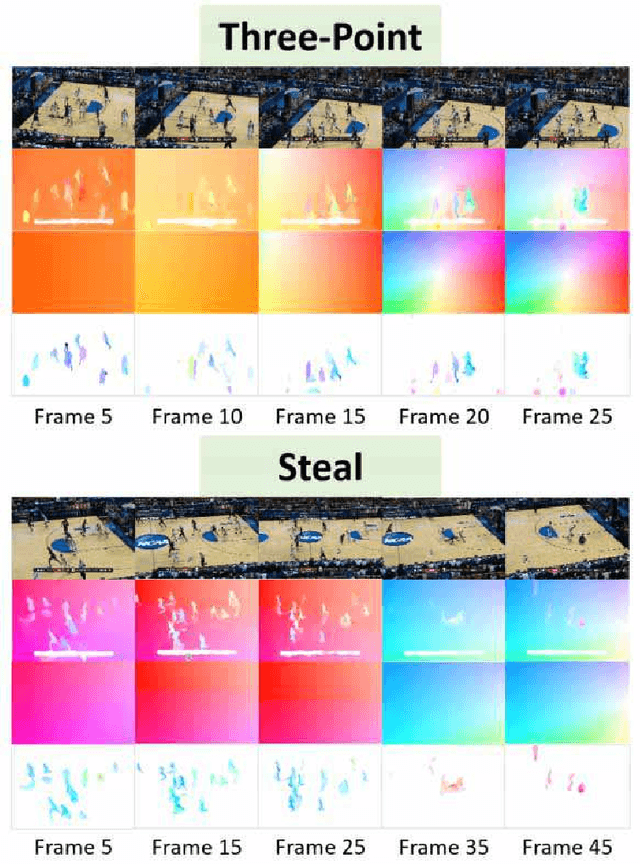
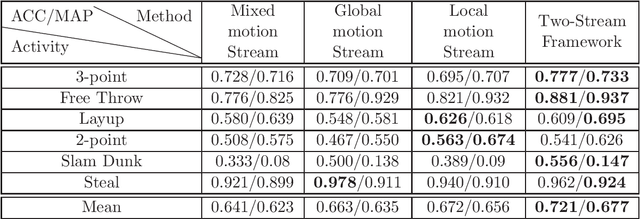


Many semantic events in team sport activities e.g. basketball often involve both group activities and the outcome (score or not). Motion patterns can be an effective means to identify different activities. Global and local motions have their respective emphasis on different activities, which are difficult to capture from the optical flow due to the mixture of global and local motions. Hence it calls for a more effective way to separate the global and local motions. When it comes to the specific case for basketball game analysis, the successful score for each round can be reliably detected by the appearance variation around the basket. Based on the observations, we propose a scheme to fuse global and local motion patterns (MPs) and key visual information (KVI) for semantic event recognition in basketball videos. Firstly, an algorithm is proposed to estimate the global motions from the mixed motions based on the intrinsic property of camera adjustments. And the local motions could be obtained from the mixed and global motions. Secondly, a two-stream 3D CNN framework is utilized for group activity recognition over the separated global and local motion patterns. Thirdly, the basket is detected and its appearance features are extracted through a CNN structure. The features are utilized to predict the success or failure. Finally, the group activity recognition and success/failure prediction results are integrated using the kronecker product for event recognition. Experiments on NCAA dataset demonstrate that the proposed method obtains state-of-the-art performance.