 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDroidStar: Callback Typestates for Android Classes
Mar 02, 2018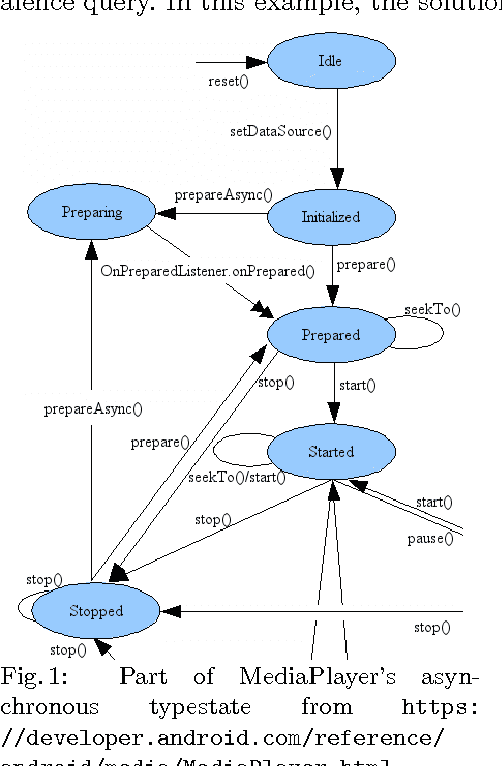
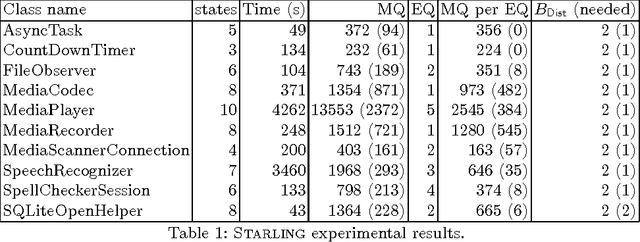
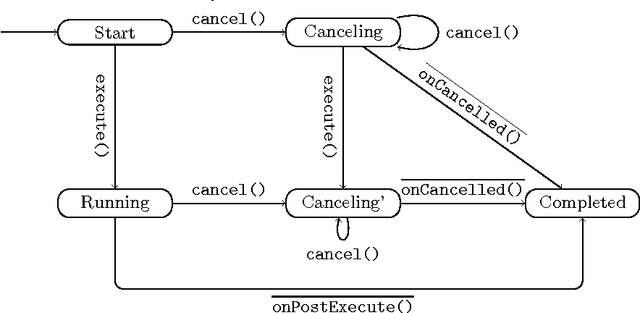
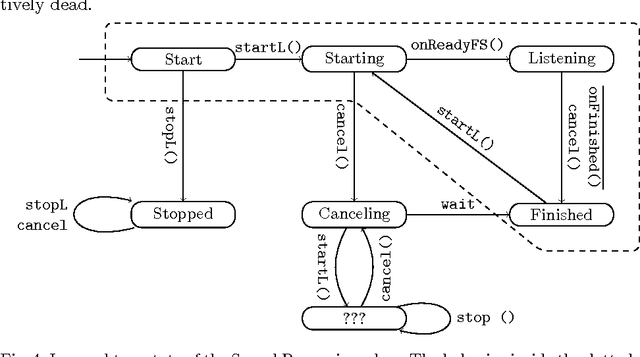
Event-driven programming frameworks, such as Android, are based on components with asynchronous interfaces. The protocols for interacting with these components can often be described by finite-state machines we dub *callback typestates*. Callback typestates are akin to classical typestates, with the difference that their outputs (callbacks) are produced asynchronously. While useful, these specifications are not commonly available, because writing them is difficult and error-prone. Our goal is to make the task of producing callback typestates significantly easier. We present a callback typestate assistant tool, DroidStar, that requires only limited user interaction to produce a callback typestate. Our approach is based on an active learning algorithm, L*. We improved the scalability of equivalence queries (a key component of L*), thus making active learning tractable on the Android system. We use DroidStar to learn callback typestates for Android classes both for cases where one is already provided by the documentation, and for cases where the documentation is unclear. The results show that DroidStar learns callback typestates accurately and efficiently. Moreover, in several cases, the synthesized callback typestates uncovered surprising and undocumented behaviors.
Differential Performance Debugging with Discriminant Regression Trees
Nov 28, 2017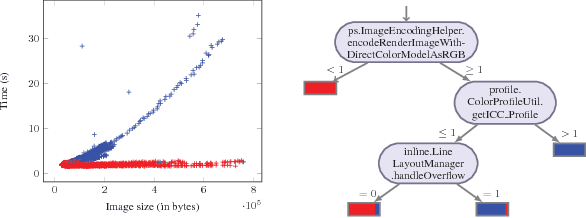
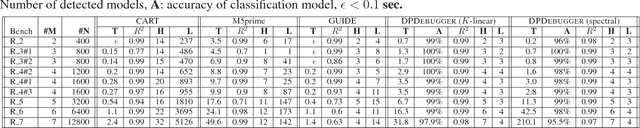

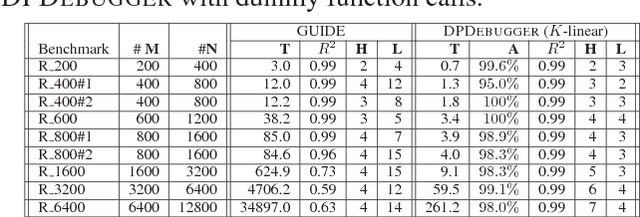
Differential performance debugging is a technique to find performance problems. It applies in situations where the performance of a program is (unexpectedly) different for different classes of inputs. The task is to explain the differences in asymptotic performance among various input classes in terms of program internals. We propose a data-driven technique based on discriminant regression tree (DRT) learning problem where the goal is to discriminate among different classes of inputs. We propose a new algorithm for DRT learning that first clusters the data into functional clusters, capturing different asymptotic performance classes, and then invokes off-the-shelf decision tree learning algorithms to explain these clusters. We focus on linear functional clusters and adapt classical clustering algorithms (K-means and spectral) to produce them. For the K-means algorithm, we generalize the notion of the cluster centroid from a point to a linear function. We adapt spectral clustering by defining a novel kernel function to capture the notion of linear similarity between two data points. We evaluate our approach on benchmarks consisting of Java programs where we are interested in debugging performance. We show that our algorithm significantly outperforms other well-known regression tree learning algorithms in terms of running time and accuracy of classification.
Discriminating Traces with Time
Feb 23, 2017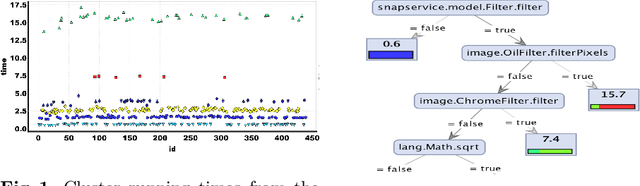

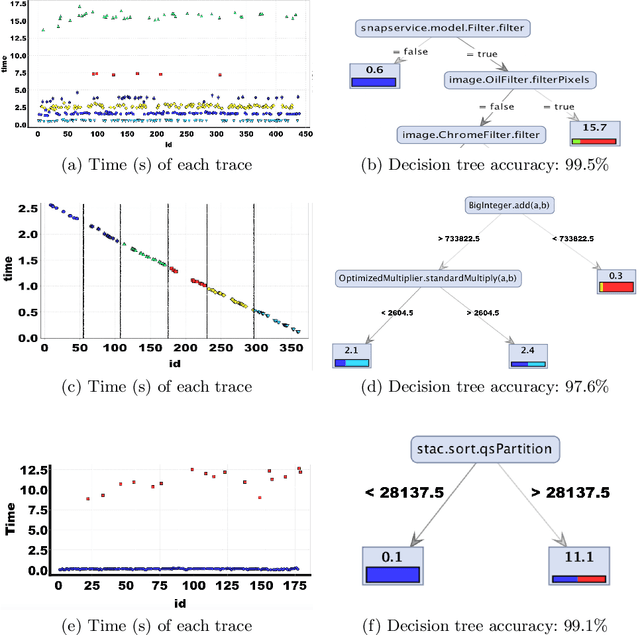
What properties about the internals of a program explain the possible differences in its overall running time for different inputs? In this paper, we propose a formal framework for considering this question we dub trace-set discrimination. We show that even though the algorithmic problem of computing maximum likelihood discriminants is NP-hard, approaches based on integer linear programming (ILP) and decision tree learning can be useful in zeroing-in on the program internals. On a set of Java benchmarks, we find that compactly-represented decision trees scalably discriminate with high accuracy---more scalably than maximum likelihood discriminants and with comparable accuracy. We demonstrate on three larger case studies how decision-tree discriminants produced by our tool are useful for debugging timing side-channel vulnerabilities (i.e., where a malicious observer infers secrets simply from passively watching execution times) and availability vulnerabilities.