 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReconciling Spatial and Temporal Abstractions for Goal Representation
Jan 18, 2024



Goal representation affects the performance of Hierarchical Reinforcement Learning (HRL) algorithms by decomposing the complex learning problem into easier subtasks. Recent studies show that representations that preserve temporally abstract environment dynamics are successful in solving difficult problems and provide theoretical guarantees for optimality. These methods however cannot scale to tasks where environment dynamics increase in complexity i.e. the temporally abstract transition relations depend on larger number of variables. On the other hand, other efforts have tried to use spatial abstraction to mitigate the previous issues. Their limitations include scalability to high dimensional environments and dependency on prior knowledge. In this paper, we propose a novel three-layer HRL algorithm that introduces, at different levels of the hierarchy, both a spatial and a temporal goal abstraction. We provide a theoretical study of the regret bounds of the learned policies. We evaluate the approach on complex continuous control tasks, demonstrating the effectiveness of spatial and temporal abstractions learned by this approach.
Goal Space Abstraction in Hierarchical Reinforcement Learning via Set-Based Reachability Analysis
Sep 14, 2023


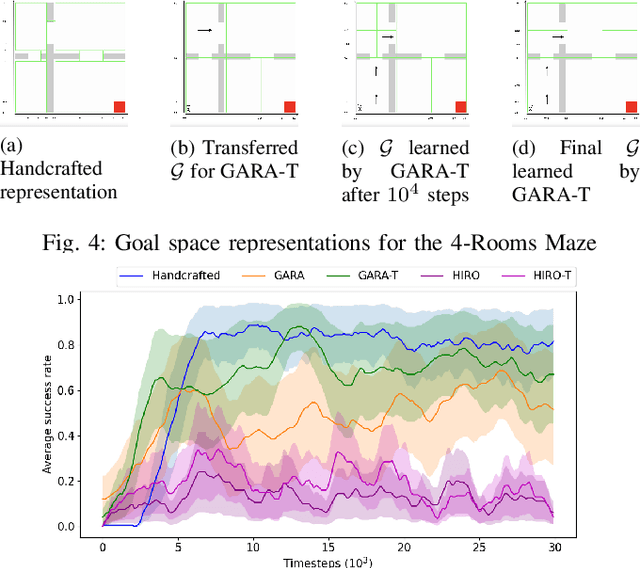
Open-ended learning benefits immensely from the use of symbolic methods for goal representation as they offer ways to structure knowledge for efficient and transferable learning. However, the existing Hierarchical Reinforcement Learning (HRL) approaches relying on symbolic reasoning are often limited as they require a manual goal representation. The challenge in autonomously discovering a symbolic goal representation is that it must preserve critical information, such as the environment dynamics. In this paper, we propose a developmental mechanism for goal discovery via an emergent representation that abstracts (i.e., groups together) sets of environment states that have similar roles in the task. We introduce a Feudal HRL algorithm that concurrently learns both the goal representation and a hierarchical policy. The algorithm uses symbolic reachability analysis for neural networks to approximate the transition relation among sets of states and to refine the goal representation. We evaluate our approach on complex navigation tasks, showing the learned representation is interpretable, transferrable and results in data efficient learning.
Goal Space Abstraction in Hierarchical Reinforcement Learning via Reachability Analysis
Sep 12, 2023


Open-ended learning benefits immensely from the use of symbolic methods for goal representation as they offer ways to structure knowledge for efficient and transferable learning. However, the existing Hierarchical Reinforcement Learning (HRL) approaches relying on symbolic reasoning are often limited as they require a manual goal representation. The challenge in autonomously discovering a symbolic goal representation is that it must preserve critical information, such as the environment dynamics. In this work, we propose a developmental mechanism for subgoal discovery via an emergent representation that abstracts (i.e., groups together) sets of environment states that have similar roles in the task. We create a HRL algorithm that gradually learns this representation along with the policies and evaluate it on navigation tasks to show the learned representation is interpretable and results in data efficiency.
DroidStar: Callback Typestates for Android Classes
Mar 02, 2018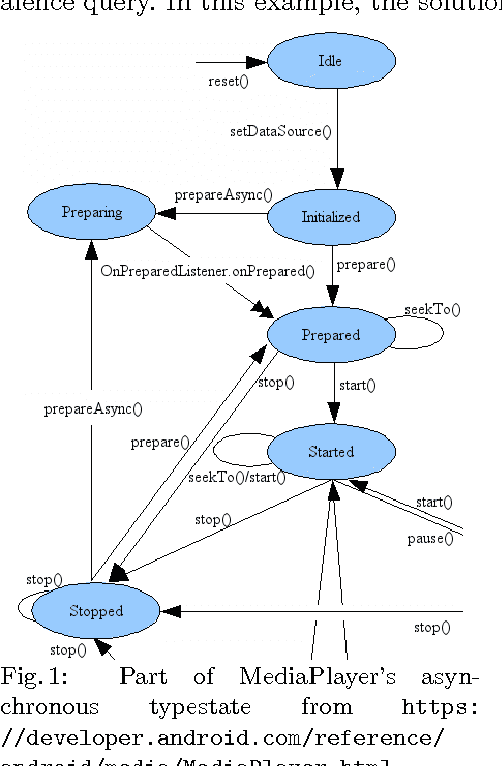
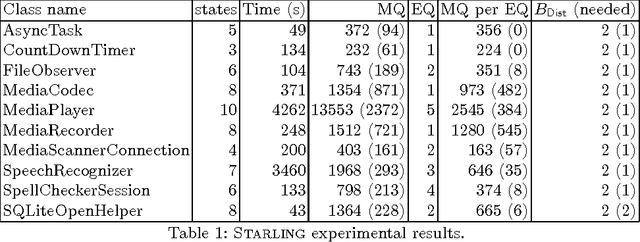
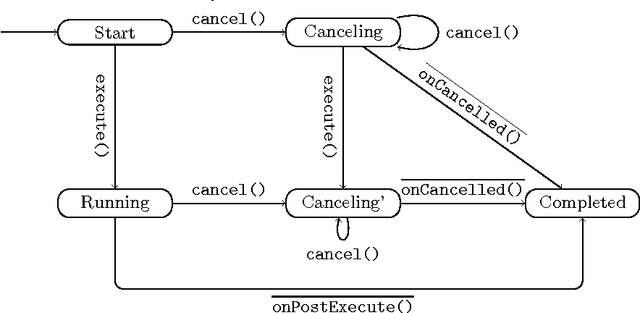
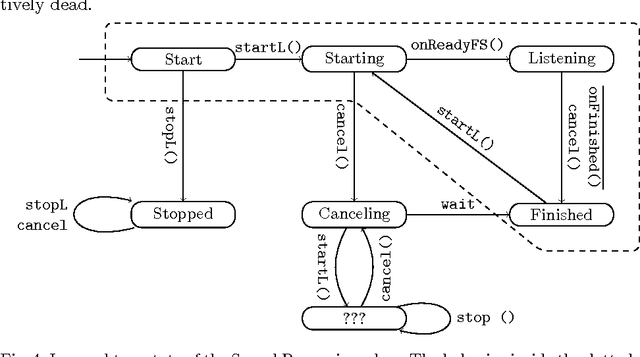
Event-driven programming frameworks, such as Android, are based on components with asynchronous interfaces. The protocols for interacting with these components can often be described by finite-state machines we dub *callback typestates*. Callback typestates are akin to classical typestates, with the difference that their outputs (callbacks) are produced asynchronously. While useful, these specifications are not commonly available, because writing them is difficult and error-prone. Our goal is to make the task of producing callback typestates significantly easier. We present a callback typestate assistant tool, DroidStar, that requires only limited user interaction to produce a callback typestate. Our approach is based on an active learning algorithm, L*. We improved the scalability of equivalence queries (a key component of L*), thus making active learning tractable on the Android system. We use DroidStar to learn callback typestates for Android classes both for cases where one is already provided by the documentation, and for cases where the documentation is unclear. The results show that DroidStar learns callback typestates accurately and efficiently. Moreover, in several cases, the synthesized callback typestates uncovered surprising and undocumented behaviors.