 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Detection and Quantification of Timing Leaks with Neural Networks
Jul 23, 2019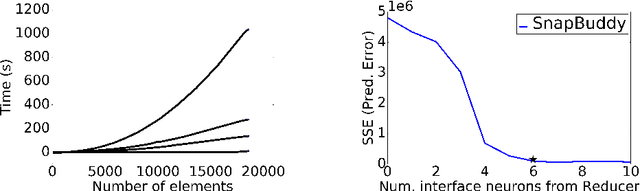

Detection and quantification of information leaks through timing side channels are important to guarantee confidentiality. Although static analysis remains the prevalent approach for detecting timing side channels, it is computationally challenging for real-world applications. In addition, the detection techniques are usually restricted to 'yes' or 'no' answers. In practice, real-world applications may need to leak information about the secret. Therefore, quantification techniques are necessary to evaluate the resulting threats of information leaks. Since both problems are very difficult or impossible for static analysis techniques, we propose a dynamic analysis method. Our novel approach is to split the problem into two tasks. First, we learn a timing model of the program as a neural network. Second, we analyze the neural network to quantify information leaks. As demonstrated in our experiments, both of these tasks are feasible in practice --- making the approach a significant improvement over the state-of-the-art side channel detectors and quantifiers. Our key technical contributions are (a) a neural network architecture that enables side channel discovery and (b) an MILP-based algorithm to estimate the side-channel strength. On a set of micro-benchmarks and real-world applications, we show that neural network models learn timing behaviors of programs with thousands of methods. We also show that neural networks with thousands of neurons can be efficiently analyzed to detect and quantify information leaks through timing side channels.
Quantitative Mitigation of Timing Side Channels
Jun 21, 2019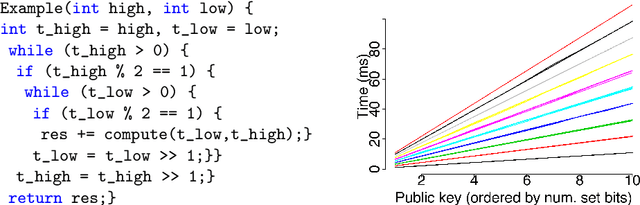
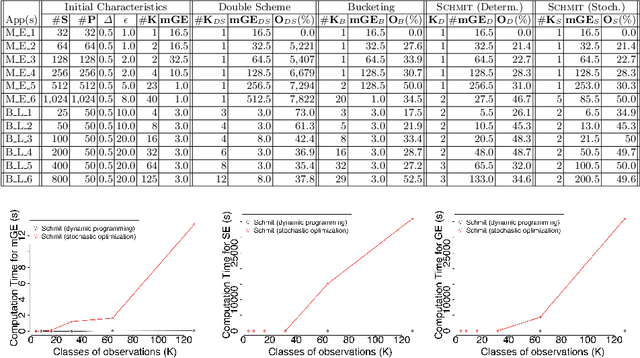
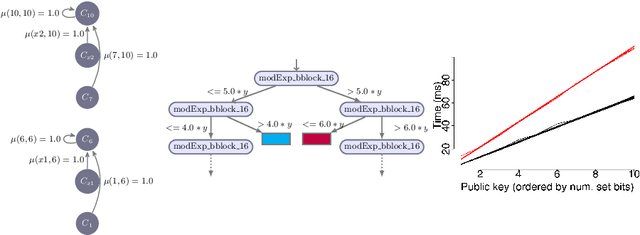
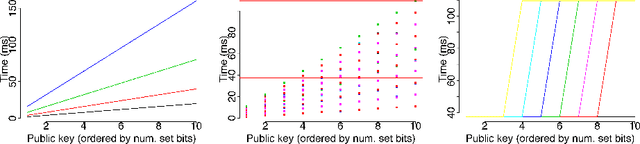
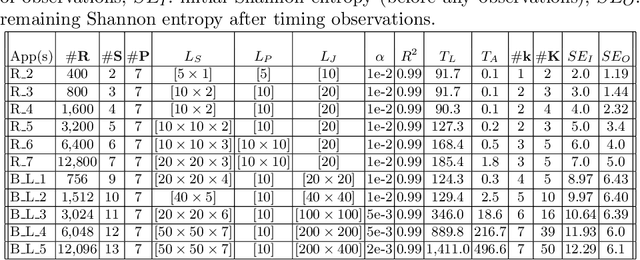
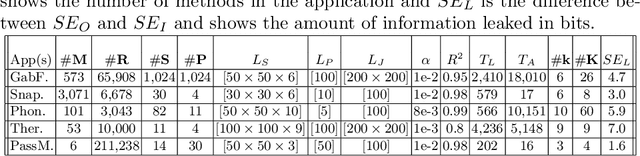
Timing side channels pose a significant threat to the security and privacy of software applications. We propose an approach for mitigating this problem by decreasing the strength of the side channels as measured by entropy-based objectives, such as min-guess entropy. Our goal is to minimize the information leaks while guaranteeing a user-specified maximal acceptable performance overhead. We dub the decision version of this problem Shannon mitigation, and consider two variants, deterministic and stochastic. First, we show the deterministic variant is NP-hard. However, we give a polynomial algorithm that finds an optimal solution from a restricted set. Second, for the stochastic variant, we develop an algorithm that uses optimization techniques specific to the entropy-based objective used. For instance, for min-guess entropy, we used mixed integer-linear programming. We apply the algorithm to a threat model where the attacker gets to make functional observations, that is, where she observes the running time of the program for the same secret value combined with different public input values. Existing mitigation approaches do not give confidentiality or performance guarantees for this threat model. We evaluate our tool SCHMIT on a number of micro-benchmarks and real-world applications with different entropy-based objectives. In contrast to the existing mitigation approaches, we show that in the functional-observation threat model, SCHMIT is scalable and able to maximize confidentiality under the performance overhead bound.
Data-Driven Debugging for Functional Side Channels
Aug 30, 2018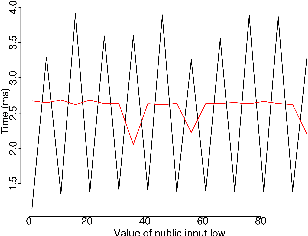
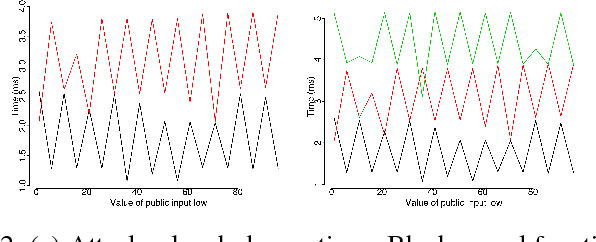

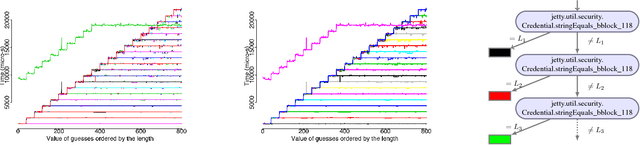
Functional side channels arise when an attacker knows that the secret value of a server stays fixed for a certain time, and can observe the server executes on a sequence of different public inputs, each paired with the same secret input. Thus for each secret, the attackers observe a (partial) function from public values to (for instance) running time, and they can compare these functions for different secrets. First, we define a notion of noninterference for functional side channels. We focus on the case of noisy observations, where we demonstrate on examples that there is a practical functional side channel in programs that would be deemed information-leak-free using the standard definition. Second, we develop a framework and techniques for debugging programs for functional side channels. We adapt existing results and algorithms in functional data analysis (such as functional clustering) to discover the existence of side channels. We use a functional extension of standard decision tree learning to pinpoint the code fragments causing a side channel if there is one. Finally, we empirically evaluate the performance of our tool Fuschia on a series of micro-benchmarks, as well as on realistic Java programs with thousands of methods. Fuschia is able to discover (and locate in the code) functional side channels, including one that was since fixed by the original developers.
Differential Performance Debugging with Discriminant Regression Trees
Nov 28, 2017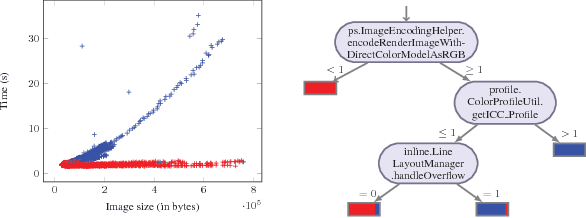
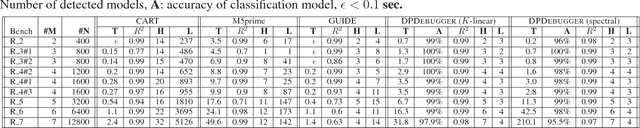

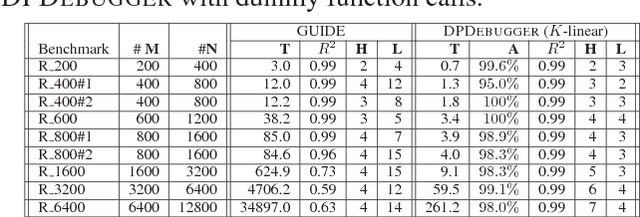
Differential performance debugging is a technique to find performance problems. It applies in situations where the performance of a program is (unexpectedly) different for different classes of inputs. The task is to explain the differences in asymptotic performance among various input classes in terms of program internals. We propose a data-driven technique based on discriminant regression tree (DRT) learning problem where the goal is to discriminate among different classes of inputs. We propose a new algorithm for DRT learning that first clusters the data into functional clusters, capturing different asymptotic performance classes, and then invokes off-the-shelf decision tree learning algorithms to explain these clusters. We focus on linear functional clusters and adapt classical clustering algorithms (K-means and spectral) to produce them. For the K-means algorithm, we generalize the notion of the cluster centroid from a point to a linear function. We adapt spectral clustering by defining a novel kernel function to capture the notion of linear similarity between two data points. We evaluate our approach on benchmarks consisting of Java programs where we are interested in debugging performance. We show that our algorithm significantly outperforms other well-known regression tree learning algorithms in terms of running time and accuracy of classification.
Discriminating Traces with Time
Feb 23, 2017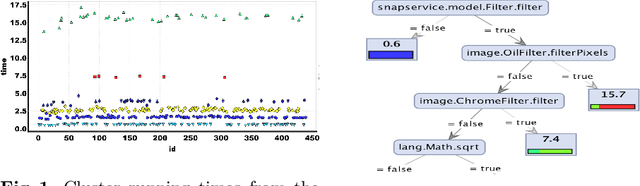

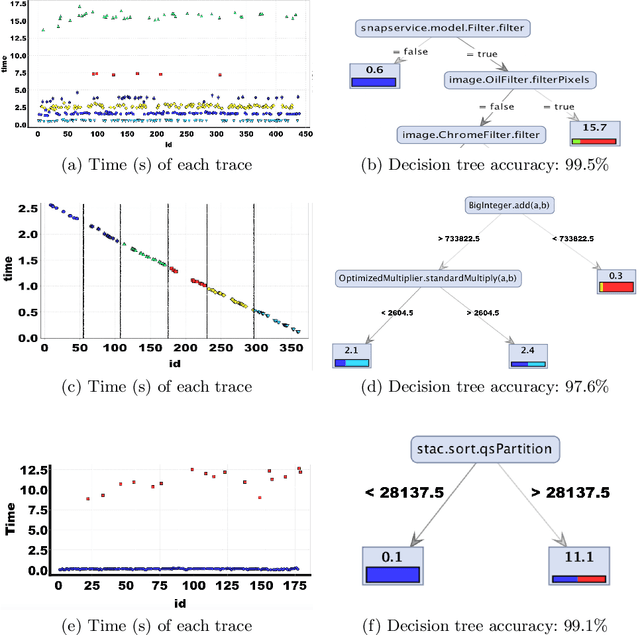
What properties about the internals of a program explain the possible differences in its overall running time for different inputs? In this paper, we propose a formal framework for considering this question we dub trace-set discrimination. We show that even though the algorithmic problem of computing maximum likelihood discriminants is NP-hard, approaches based on integer linear programming (ILP) and decision tree learning can be useful in zeroing-in on the program internals. On a set of Java benchmarks, we find that compactly-represented decision trees scalably discriminate with high accuracy---more scalably than maximum likelihood discriminants and with comparable accuracy. We demonstrate on three larger case studies how decision-tree discriminants produced by our tool are useful for debugging timing side-channel vulnerabilities (i.e., where a malicious observer infers secrets simply from passively watching execution times) and availability vulnerabilities.