 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminating Traces with Time
Paper and Code
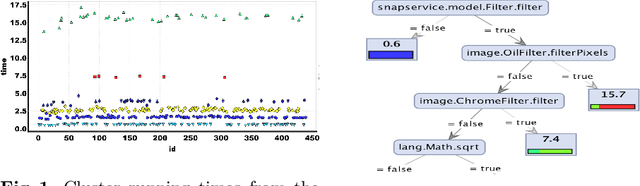

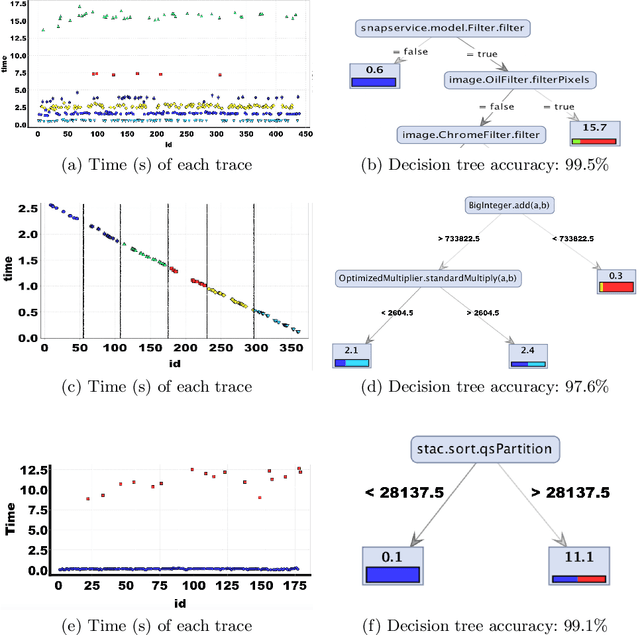
What properties about the internals of a program explain the possible differences in its overall running time for different inputs? In this paper, we propose a formal framework for considering this question we dub trace-set discrimination. We show that even though the algorithmic problem of computing maximum likelihood discriminants is NP-hard, approaches based on integer linear programming (ILP) and decision tree learning can be useful in zeroing-in on the program internals. On a set of Java benchmarks, we find that compactly-represented decision trees scalably discriminate with high accuracy---more scalably than maximum likelihood discriminants and with comparable accuracy. We demonstrate on three larger case studies how decision-tree discriminants produced by our tool are useful for debugging timing side-channel vulnerabilities (i.e., where a malicious observer infers secrets simply from passively watching execution times) and availability vulnerabilities.