 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs to Infer Non-Binary COVID-19 Sentiments of Chinese Micro-bloggers
Jan 09, 2025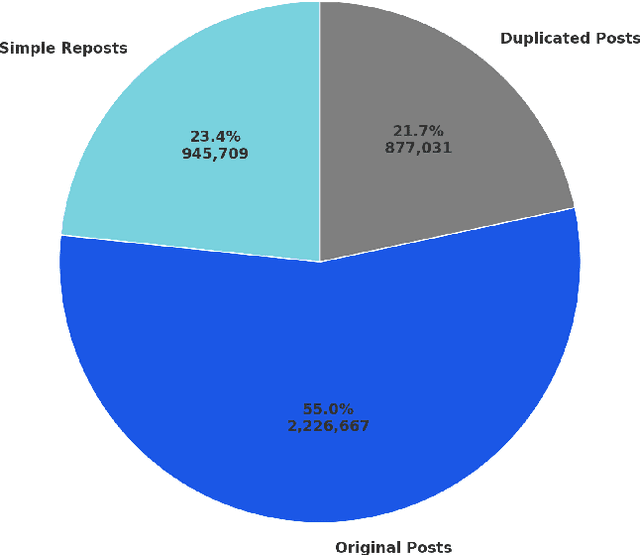

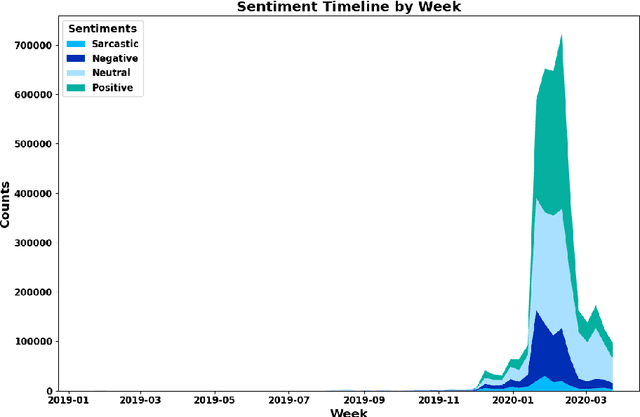
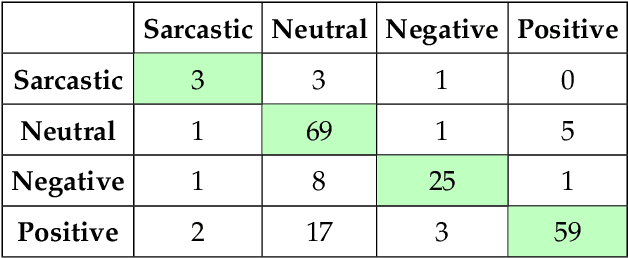
Studying public sentiment during crises is crucial for understanding how opinions and sentiments shift, resulting in polarized societies. We study Weibo, the most popular microblogging site in China, using posts made during the outbreak of the COVID-19 crisis. The study period includes the pre-COVID-19 stage, the outbreak stage, and the early stage of epidemic prevention. We use Llama 3 8B, a Large Language Model, to analyze users' sentiments on the platform by classifying them into positive, negative, sarcastic, and neutral categories. Analyzing sentiment shifts on Weibo provides insights into how social events and government actions influence public opinion. This study contributes to understanding the dynamics of social sentiments during health crises, fulfilling a gap in sentiment analysis for Chinese platforms. By examining these dynamics, we aim to offer valuable perspectives on digital communication's role in shaping society's responses during unprecedented global challenges.
Limits of Large Language Models in Debating Humans
Feb 06, 2024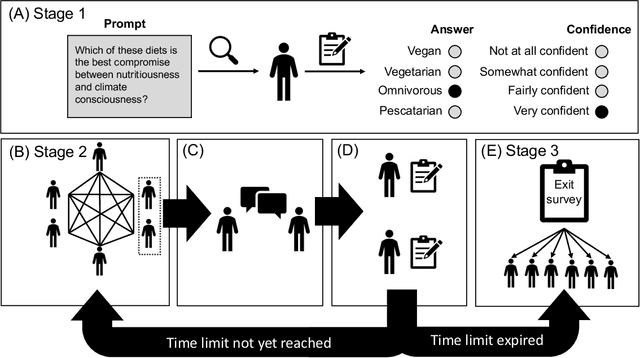
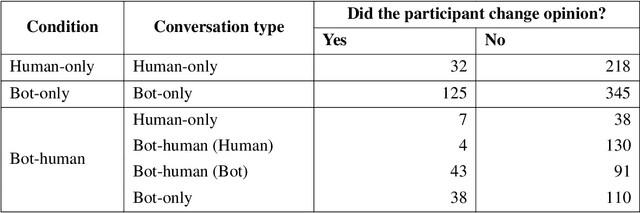
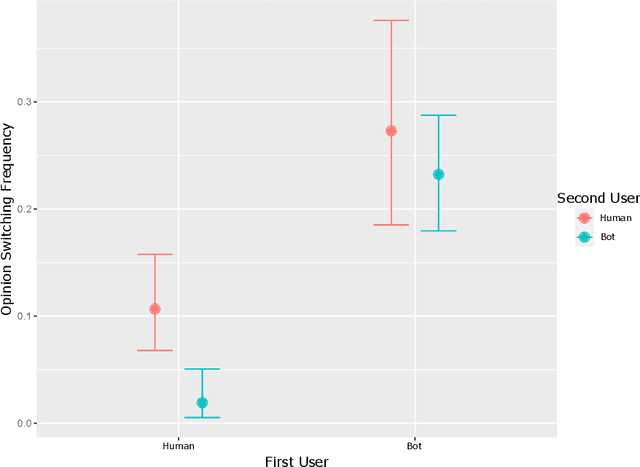
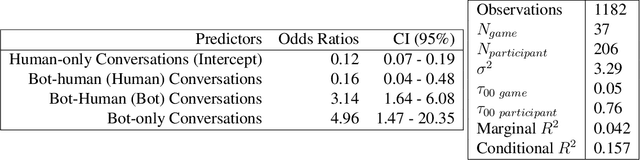
Large Language Models (LLMs) have shown remarkable promise in their ability to interact proficiently with humans. Subsequently, their potential use as artificial confederates and surrogates in sociological experiments involving conversation is an exciting prospect. But how viable is this idea? This paper endeavors to test the limits of current-day LLMs with a pre-registered study integrating real people with LLM agents acting as people. The study focuses on debate-based opinion consensus formation in three environments: humans only, agents and humans, and agents only. Our goal is to understand how LLM agents influence humans, and how capable they are in debating like humans. We find that LLMs can blend in and facilitate human productivity but are less convincing in debate, with their behavior ultimately deviating from human's. We elucidate these primary failings and anticipate that LLMs must evolve further before being viable debaters.
Analyzing Trendy Twitter Hashtags in the 2022 French Election
Oct 11, 2023Regressions trained to predict the future activity of social media users need rich features for accurate predictions. Many advanced models exist to generate such features; however, the time complexities of their computations are often prohibitive when they run on enormous data-sets. Some studies have shown that simple semantic network features can be rich enough to use for regressions without requiring complex computations. We propose a method for using semantic networks as user-level features for machine learning tasks. We conducted an experiment using a semantic network of 1037 Twitter hashtags from a corpus of 3.7 million tweets related to the 2022 French presidential election. A bipartite graph is formed where hashtags are nodes and weighted edges connect the hashtags reflecting the number of Twitter users that interacted with both hashtags. The graph is then transformed into a maximum-spanning tree with the most popular hashtag as its root node to construct a hierarchy amongst the hashtags. We then provide a vector feature for each user based on this tree. To validate the usefulness of our semantic feature we performed a regression experiment to predict the response rate of each user with six emotions like anger, enjoyment, or disgust. Our semantic feature performs well with the regression with most emotions having $R^2$ above 0.5. These results suggest that our semantic feature could be considered for use in further experiments predicting social media response on big data-sets.
A Machine Learning Approach to Predicting Continuous Tie Strengths
Jan 23, 2021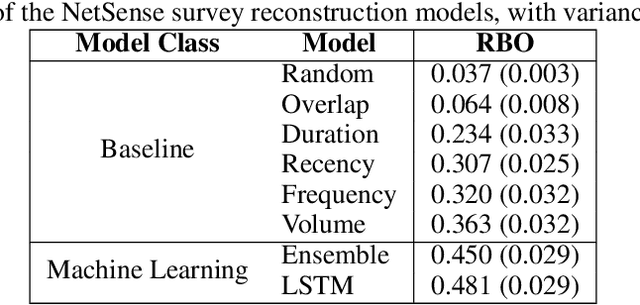
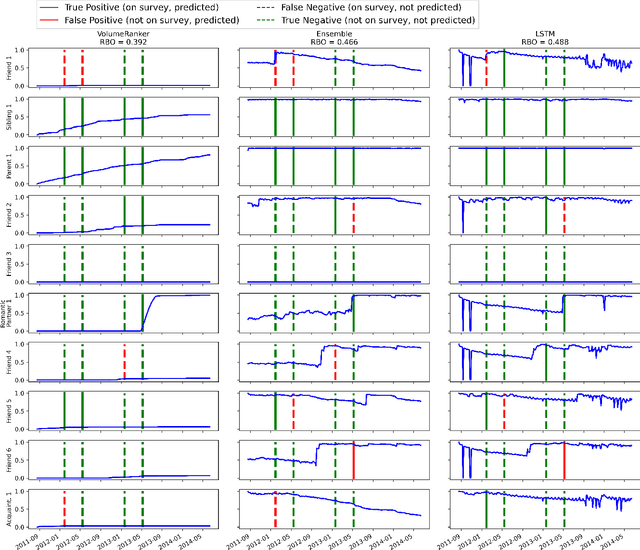

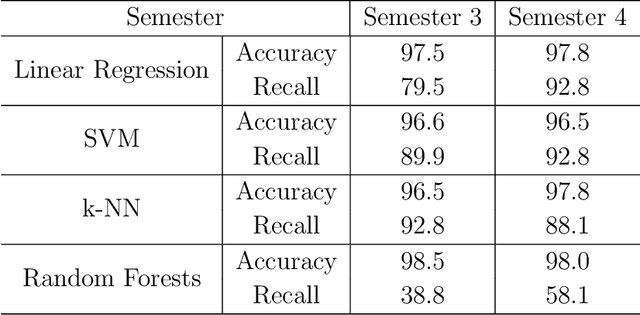
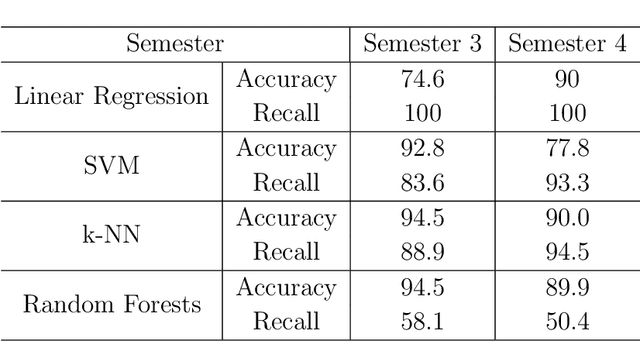
Relationships between people constantly evolve, altering interpersonal behavior and defining social groups. Relationships between nodes in social networks can be represented by a tie strength, often empirically assessed using surveys. While this is effective for taking static snapshots of relationships, such methods are difficult to scale to dynamic networks. In this paper, we propose a system that allows for the continuous approximation of relationships as they evolve over time. We evaluate this system using the NetSense study, which provides comprehensive communication records of students at the University of Notre Dame over the course of four years. These records are complemented by semesterly ego network surveys, which provide discrete samples over time of each participant's true social tie strength with others. We develop a pair of powerful machine learning models (complemented by a suite of baselines extracted from past works) that learn from these surveys to interpret the communications records as signals. These signals represent dynamic tie strengths, accurately recording the evolution of relationships between the individuals in our social networks. With these evolving tie values, we are able to make several empirically derived observations which we compare to past works.
Learning Parameters for Balanced Index Influence Maximization
Dec 15, 2020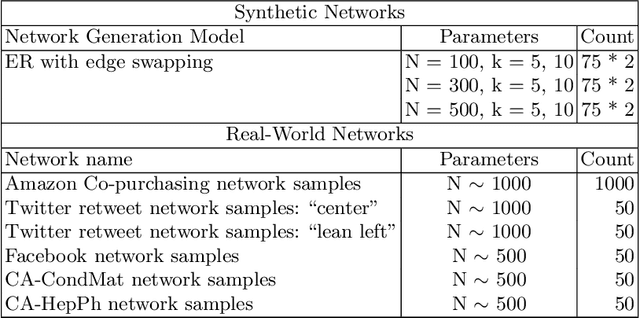
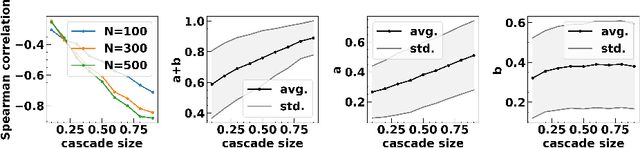

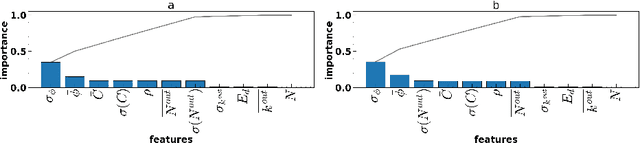
Influence maximization is the task of finding the smallest set of nodes whose activation in a social network can trigger an activation cascade that reaches the targeted network coverage, where threshold rules determine the outcome of influence. This problem is NP-hard and it has generated a significant amount of recent research on finding efficient heuristics. We focus on a {\it Balance Index} algorithm that relies on three parameters to tune its performance to the given network structure. We propose using a supervised machine-learning approach for such tuning. We select the most influential graph features for the parameter tuning. Then, using random-walk-based graph-sampling, we create small snapshots from the given synthetic and large-scale real-world networks. Using exhaustive search, we find for these snapshots the high accuracy values of BI parameters to use as a ground truth. Then, we train our machine-learning model on the snapshots and apply this model to the real-word network to find the best BI parameters. We apply these parameters to the sampled real-world network to measure the quality of the sets of initiators found this way. We use various real-world networks to validate our approach against other heuristic.
Network resilience
Jul 26, 2020
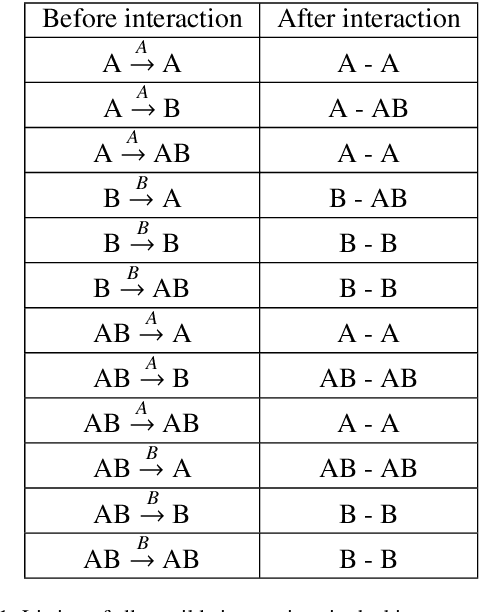
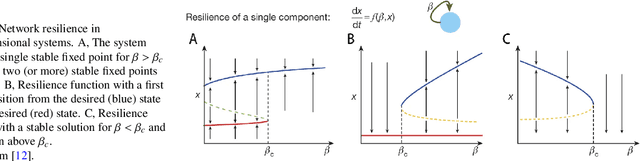

Many systems on our planet are known to shift abruptly and irreversibly from one state to another when they are forced across a "tipping point," such as mass extinctions in ecological networks, cascading failures in infrastructure systems, and social convention changes in human and animal networks. Such a regime shift demonstrates a system's resilience that characterizes the ability of a system to adjust its activity to retain its basic functionality in the face of internal disturbances or external environmental changes. In the past 50 years, attention was almost exclusively given to low dimensional systems and calibration of their resilience functions and indicators of early warning signals without considerations for the interactions between the components. Only in recent years, taking advantages of the network theory and lavish real data sets, network scientists have directed their interest to the real-world complex networked multidimensional systems and their resilience function and early warning indicators. This report is devoted to a comprehensive review of resilience function and regime shift of complex systems in different domains, such as ecology, biology, social systems and infrastructure. We cover the related research about empirical observations, experimental studies, mathematical modeling, and theoretical analysis. We also discuss some ambiguous definitions, such as robustness, resilience, and stability.
Modeling competitive evolution of multiple languages
Jul 16, 2019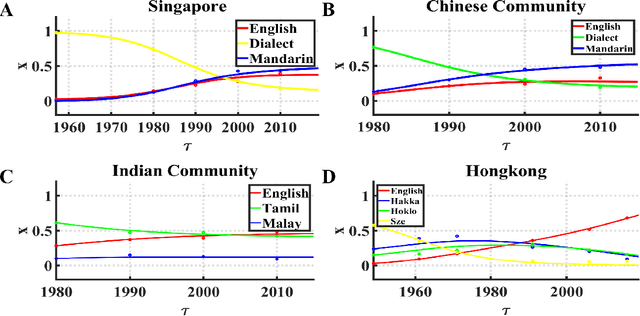
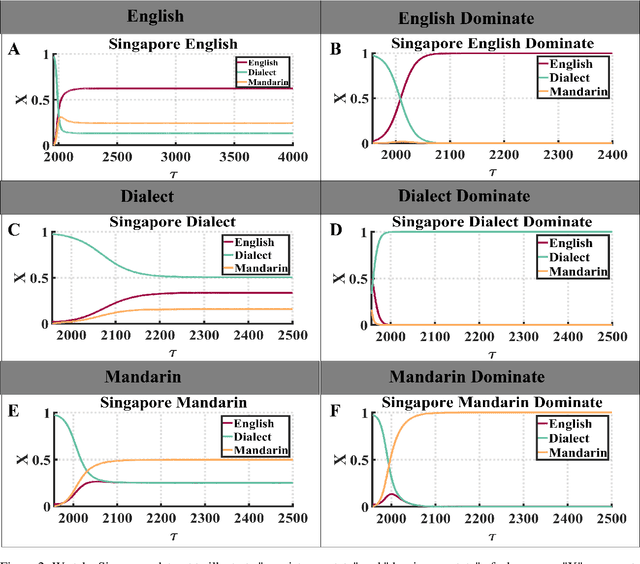
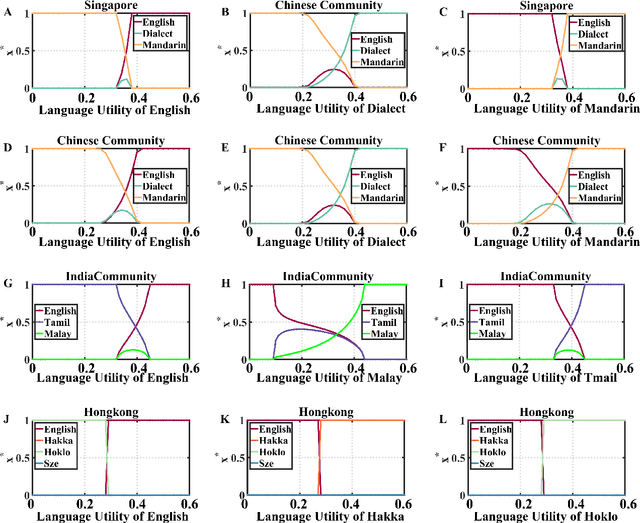
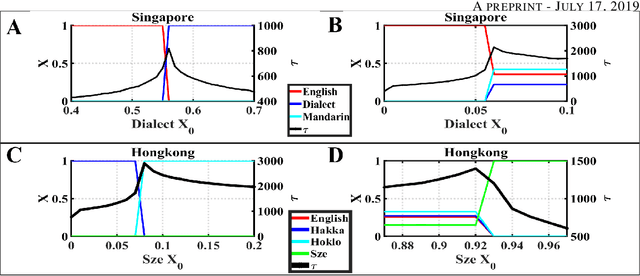
Increasing evidence demonstrates that in many places language coexistence has become ubiquitous and essential for supporting language and cultural diversity and associated with its financial and economic benefits. The competitive evolution among multiple languages determines the evolution outcome, either coexistence, decline, or extinction. Here, we extend the Abrams-Strogatz model of language competition to multiple languages and then validate it by analyzing the behavioral transitions of language usage over the recent several decades in Singapore and Hong Kong. In each case, we estimate from data the model parameters that measure each language utility for its speakers and the strength of two biases, the majority preference for their language, and the minority aversion to it. The values of these two biases decide which language is the fastest growing in the competition and what would be the stable state of the system. We also study the system convergence time to stable states and discover the existence of tipping points with multiple attractors. Moreover, the critical slowdown of convergence to the stable fractions of language users appears near and peaks at the tipping points, signaling when the system approaches them. Our analysis furthers our understanding of multiple language evolution and the role of tipping points in behavioral transitions. These insights may help to protect languages from extinction and retain the language and cultural diversity.
Influence of Personal Preferences on Link Dynamics in Social Networks
Sep 21, 2017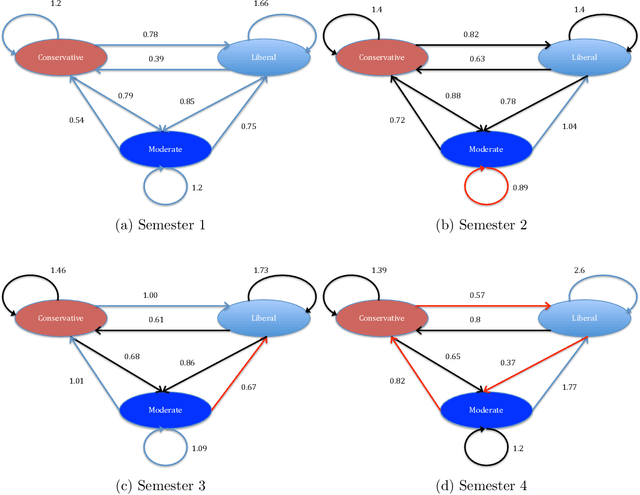
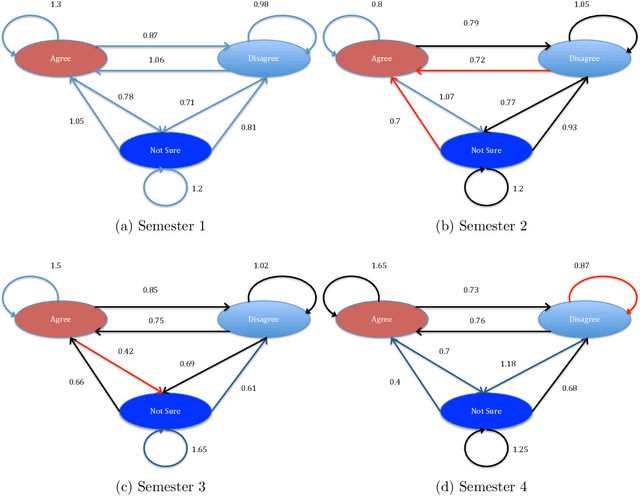
We study a unique network dataset including periodic surveys and electronic logs of dyadic contacts via smartphones. The participants were a sample of freshmen entering university in the Fall 2011. Their opinions on a variety of political and social issues and lists of activities on campus were regularly recorded at the beginning and end of each semester for the first three years of study. We identify a behavioral network defined by call and text data, and a cognitive network based on friendship nominations in ego-network surveys. Both networks are limited to study participants. Since a wide range of attributes on each node were collected in self-reports, we refer to these networks as attribute-rich networks. We study whether student preferences for certain attributes of friends can predict formation and dissolution of edges in both networks. We introduce a method for computing student preferences for different attributes which we use to predict link formation and dissolution. We then rank these attributes according to their importance for making predictions. We find that personal preferences, in particular political views, and preferences for common activities help predict link formation and dissolution in both the behavioral and cognitive networks.
* 12 pages
Naming Games in Spatially-Embedded Random Networks
May 07, 2007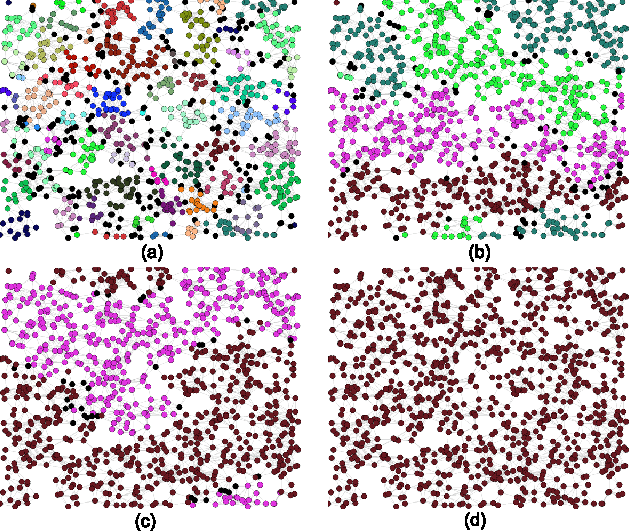
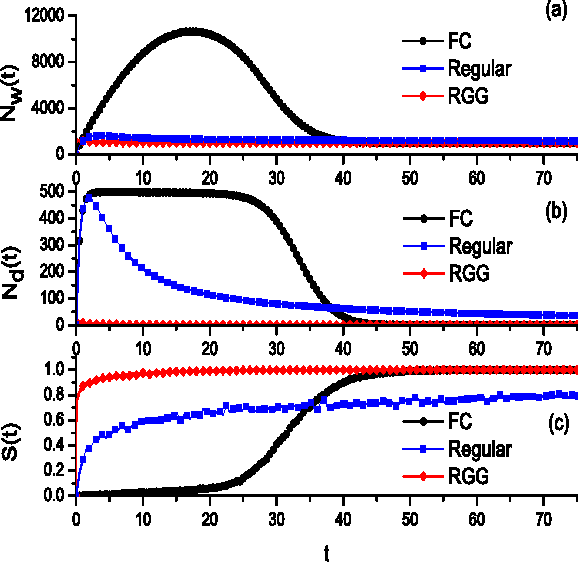
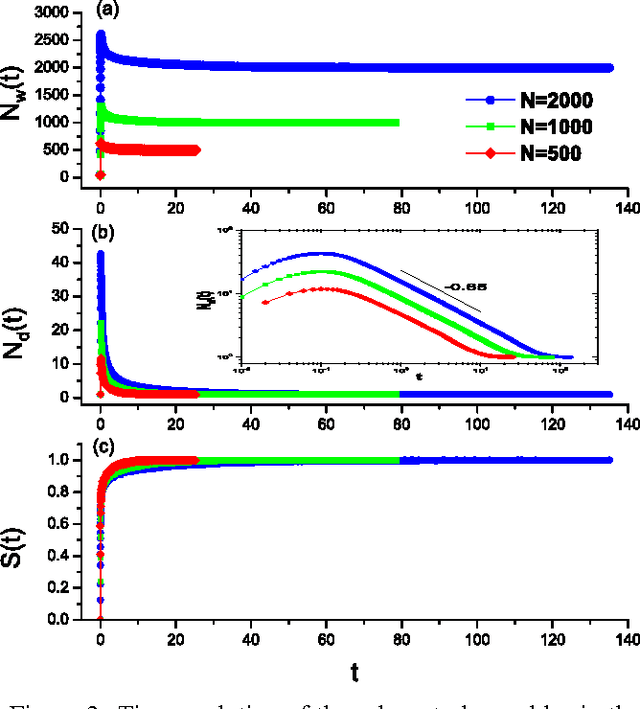
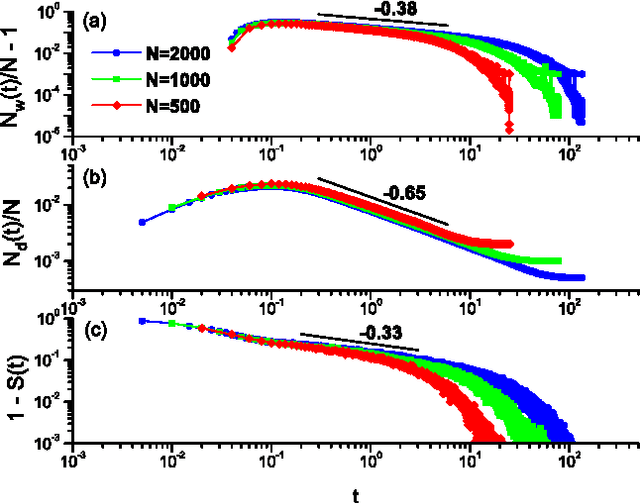
We investigate a prototypical agent-based model, the Naming Game, on random geometric networks. The Naming Game is a minimal model, employing local communications that captures the emergence of shared communication schemes (languages) in a population of autonomous semiotic agents. Implementing the Naming Games on random geometric graphs, local communications being local broadcasts, serves as a model for agreement dynamics in large-scale, autonomously operating wireless sensor networks. Further, it captures essential features of the scaling properties of the agreement process for spatially-embedded autonomous agents. We also present results for the case when a small density of long-range communication links are added on top of the random geometric graph, resulting in a "small-world"-like network and yielding a significantly reduced time to reach global agreement.
* We have found a programming error in our code used to generate the results of the earlier version. We have corrected the error, reran all simulations, and regenerated all data plots. While the qualitative behavior of the model has not changed, the numerical values of some of the scaling exponents did. 7 figures