 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing LLMs to Infer Non-Binary COVID-19 Sentiments of Chinese Micro-bloggers
Jan 09, 2025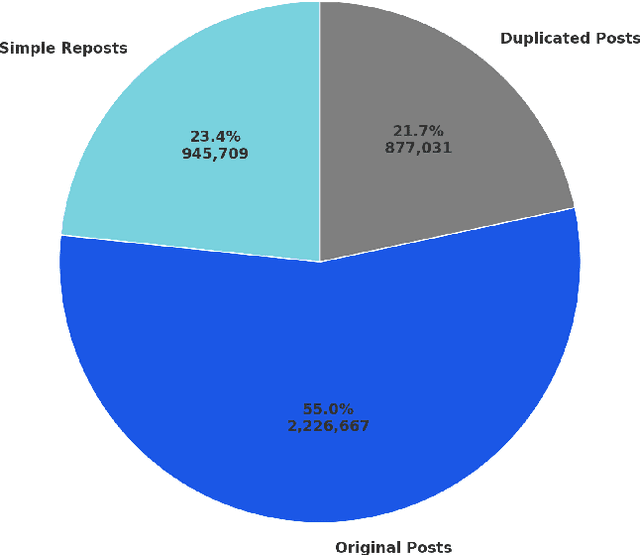

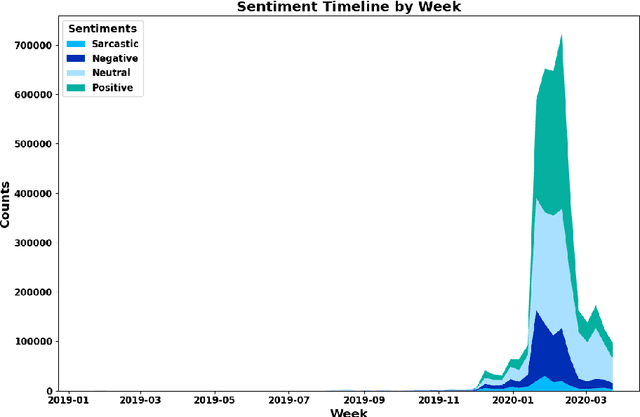
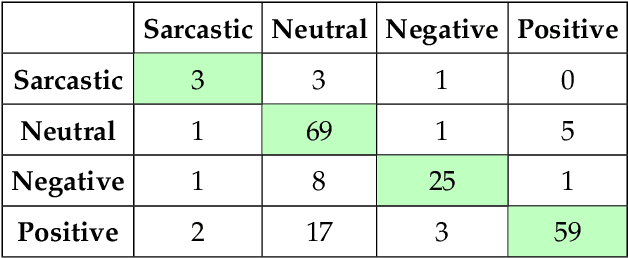
Studying public sentiment during crises is crucial for understanding how opinions and sentiments shift, resulting in polarized societies. We study Weibo, the most popular microblogging site in China, using posts made during the outbreak of the COVID-19 crisis. The study period includes the pre-COVID-19 stage, the outbreak stage, and the early stage of epidemic prevention. We use Llama 3 8B, a Large Language Model, to analyze users' sentiments on the platform by classifying them into positive, negative, sarcastic, and neutral categories. Analyzing sentiment shifts on Weibo provides insights into how social events and government actions influence public opinion. This study contributes to understanding the dynamics of social sentiments during health crises, fulfilling a gap in sentiment analysis for Chinese platforms. By examining these dynamics, we aim to offer valuable perspectives on digital communication's role in shaping society's responses during unprecedented global challenges.
Limits of Large Language Models in Debating Humans
Feb 06, 2024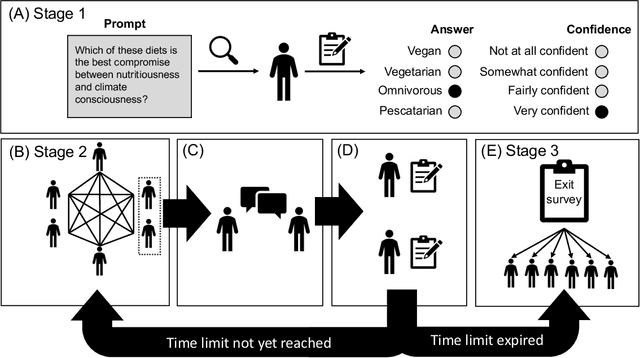
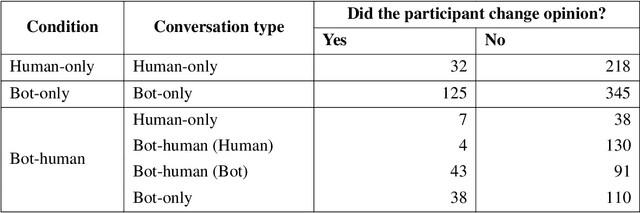
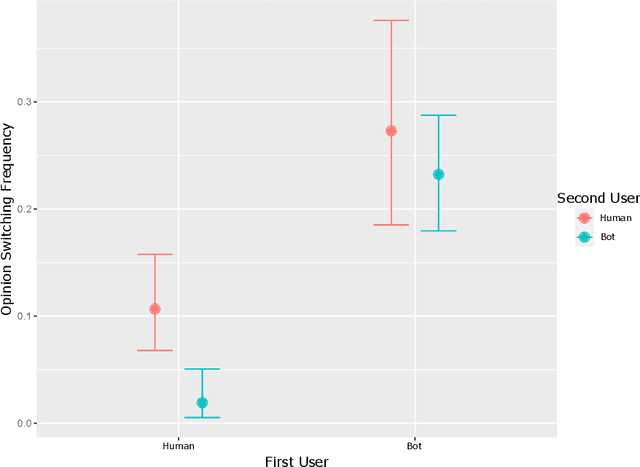
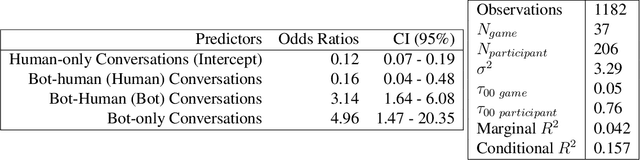
Large Language Models (LLMs) have shown remarkable promise in their ability to interact proficiently with humans. Subsequently, their potential use as artificial confederates and surrogates in sociological experiments involving conversation is an exciting prospect. But how viable is this idea? This paper endeavors to test the limits of current-day LLMs with a pre-registered study integrating real people with LLM agents acting as people. The study focuses on debate-based opinion consensus formation in three environments: humans only, agents and humans, and agents only. Our goal is to understand how LLM agents influence humans, and how capable they are in debating like humans. We find that LLMs can blend in and facilitate human productivity but are less convincing in debate, with their behavior ultimately deviating from human's. We elucidate these primary failings and anticipate that LLMs must evolve further before being viable debaters.