 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisualizing Convolutional Neural Networks to Improve Decision Support for Skin Lesion Classification
Sep 11, 2018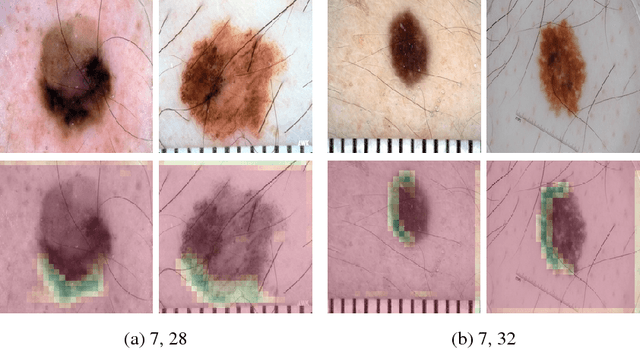
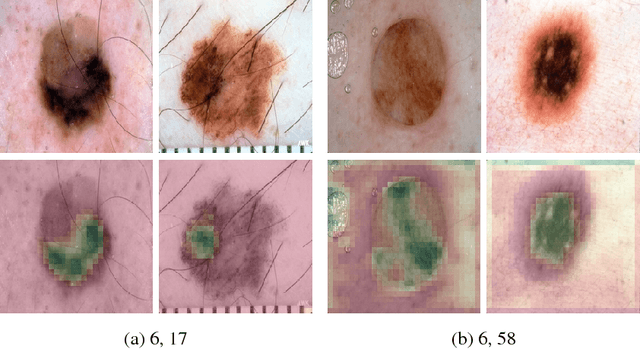

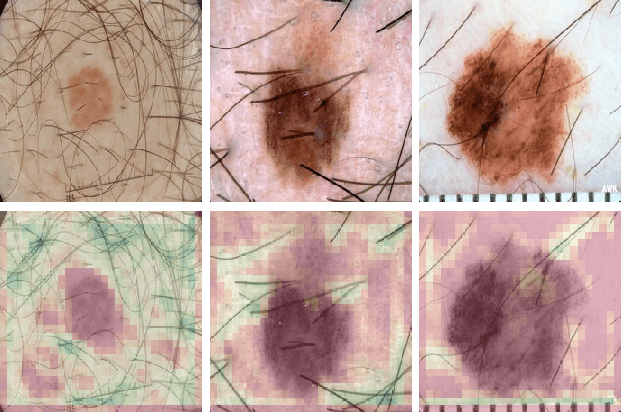
Because of their state-of-the-art performance in computer vision, CNNs are becoming increasingly popular in a variety of fields, including medicine. However, as neural networks are black box function approximators, it is difficult, if not impossible, for a medical expert to reason about their output. This could potentially result in the expert distrusting the network when he or she does not agree with its output. In such a case, explaining why the CNN makes a certain decision becomes valuable information. In this paper, we try to open the black box of the CNN by inspecting and visualizing the learned feature maps, in the field of dermatology. We show that, to some extent, CNNs focus on features similar to those used by dermatologists to make a diagnosis. However, more research is required for fully explaining their output.
Transfer Learning with Binary Neural Networks
Nov 29, 2017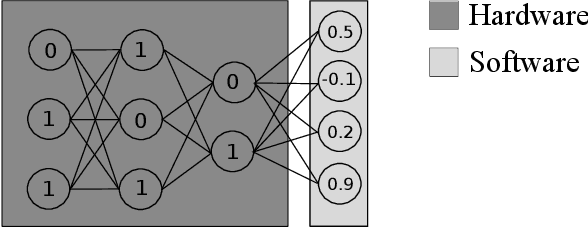
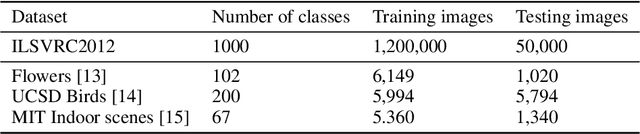
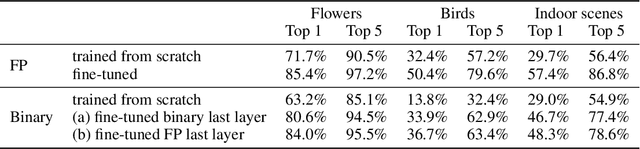
Previous work has shown that it is possible to train deep neural networks with low precision weights and activations. In the extreme case it is even possible to constrain the network to binary values. The costly floating point multiplications are then reduced to fast logical operations. High end smart phones such as Google's Pixel 2 and Apple's iPhone X are already equipped with specialised hardware for image processing and it is very likely that other future consumer hardware will also have dedicated accelerators for deep neural networks. Binary neural networks are attractive in this case because the logical operations are very fast and efficient when implemented in hardware. We propose a transfer learning based architecture where we first train a binary network on Imagenet and then retrain part of the network for different tasks while keeping most of the network fixed. The fixed binary part could be implemented in a hardware accelerator while the last layers of the network are evaluated in software. We show that a single binary neural network trained on the Imagenet dataset can indeed be used as a feature extractor for other datasets.
Sensor Fusion for Robot Control through Deep Reinforcement Learning
Mar 13, 2017
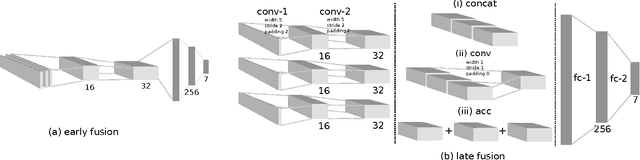
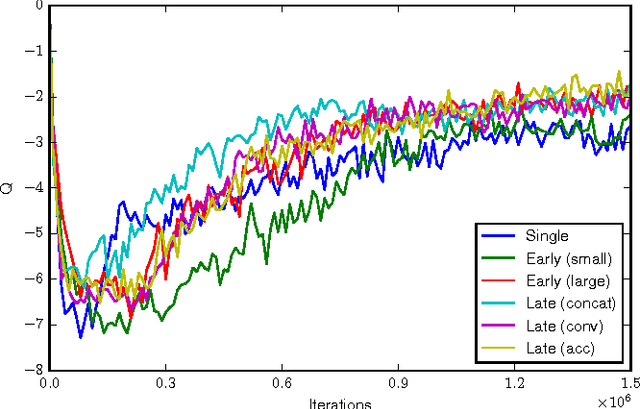
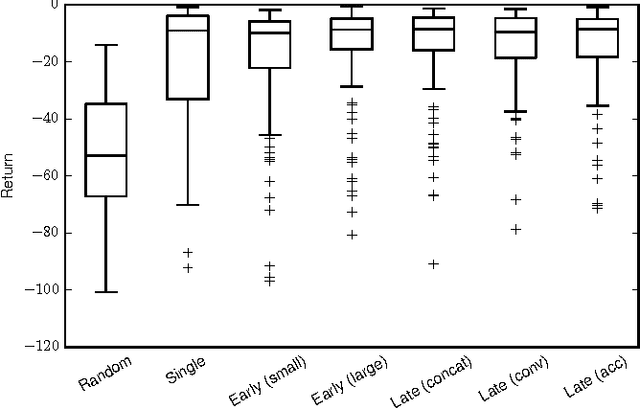
Deep reinforcement learning is becoming increasingly popular for robot control algorithms, with the aim for a robot to self-learn useful feature representations from unstructured sensory input leading to the optimal actuation policy. In addition to sensors mounted on the robot, sensors might also be deployed in the environment, although these might need to be accessed via an unreliable wireless connection. In this paper, we demonstrate deep neural network architectures that are able to fuse information coming from multiple sensors and are robust to sensor failures at runtime. We evaluate our method on a search and pick task for a robot both in simulation and the real world.
Lazy Evaluation of Convolutional Filters
May 27, 2016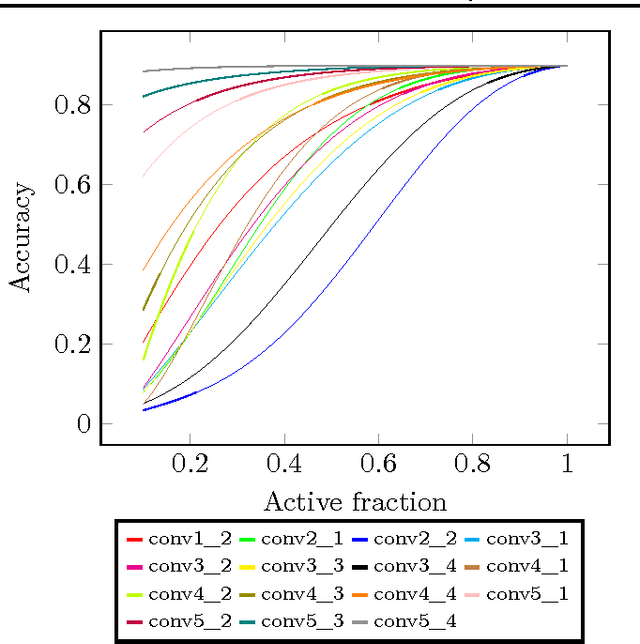
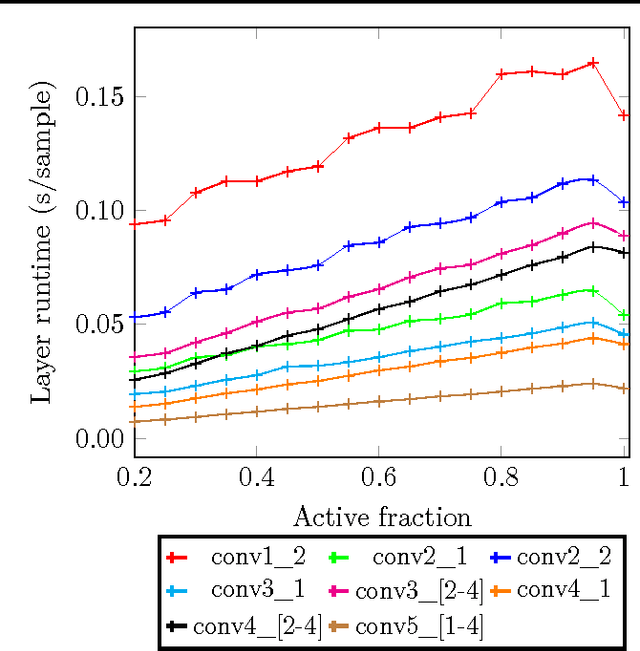
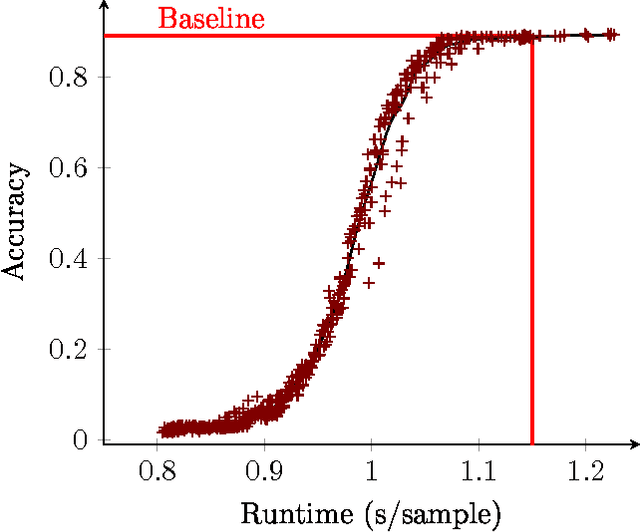
In this paper we propose a technique which avoids the evaluation of certain convolutional filters in a deep neural network. This allows to trade-off the accuracy of a deep neural network with the computational and memory requirements. This is especially important on a constrained device unable to hold all the weights of the network in memory.