Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLazy Evaluation of Convolutional Filters
Paper and Code
May 27, 2016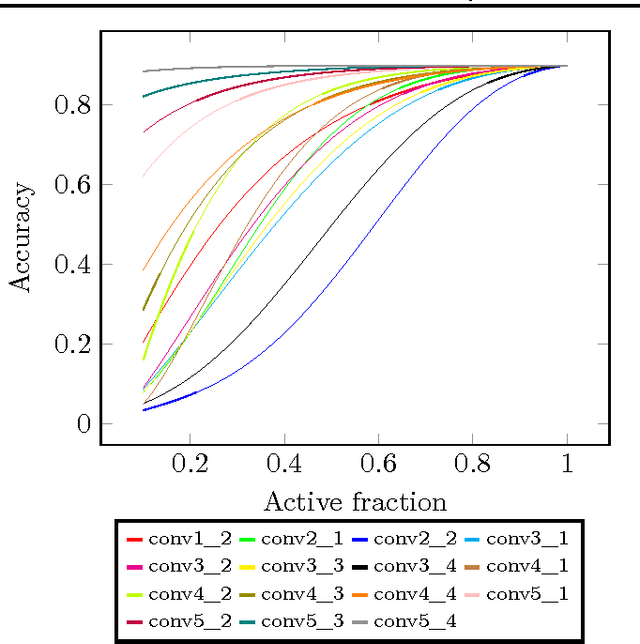
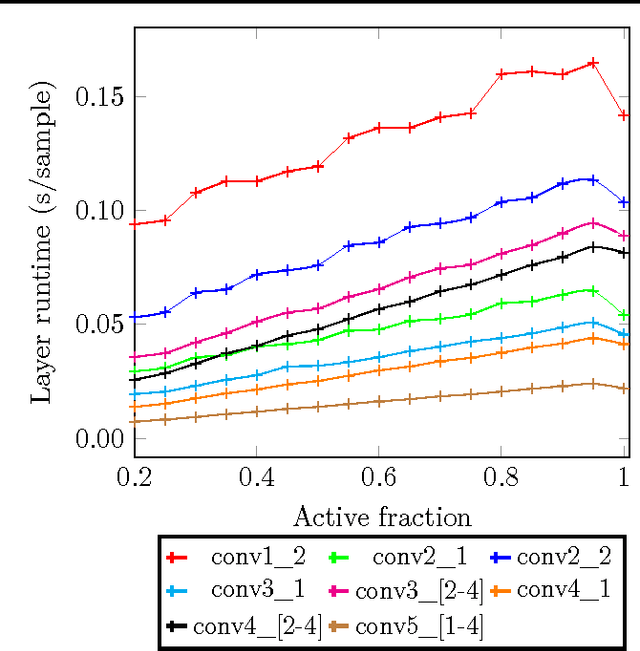
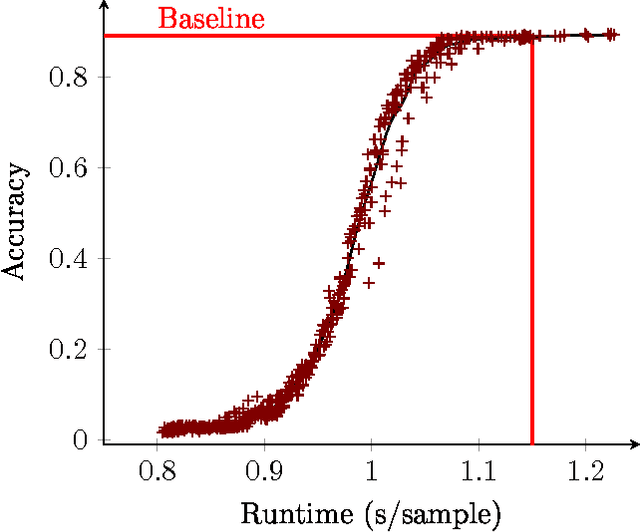
In this paper we propose a technique which avoids the evaluation of certain convolutional filters in a deep neural network. This allows to trade-off the accuracy of a deep neural network with the computational and memory requirements. This is especially important on a constrained device unable to hold all the weights of the network in memory.
View paper on