 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQoS-Nets: Adaptive Approximate Neural Network Inference
Oct 10, 2024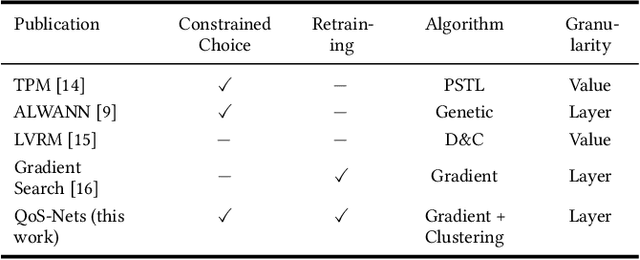
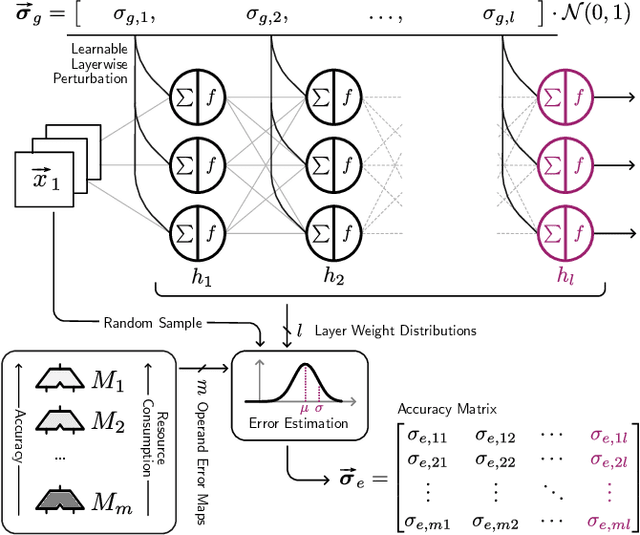
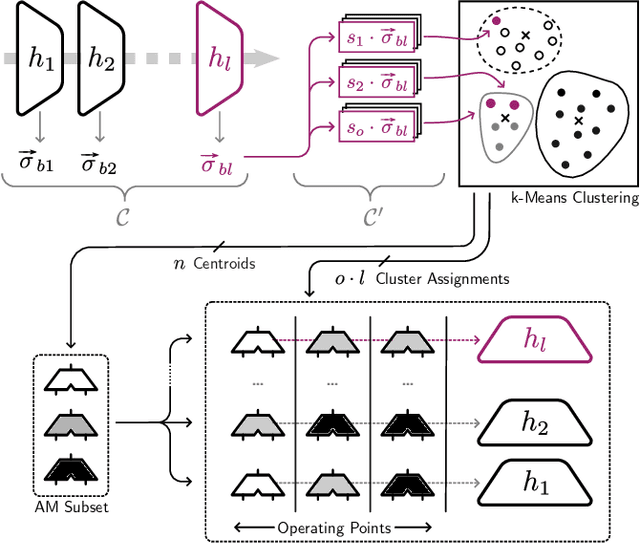

In order to vary the arithmetic resource consumption of neural network applications at runtime, this work proposes the flexible reuse of approximate multipliers for neural network layer computations. We introduce a search algorithm that chooses an appropriate subset of approximate multipliers of a user-defined size from a larger search space and enables retraining to maximize task performance. Unlike previous work, our approach can output more than a single, static assignment of approximate multiplier instances to layers. These different operating points allow a system to gradually adapt its Quality of Service (QoS) to changing environmental conditions by increasing or decreasing its accuracy and resource consumption. QoS-Nets achieves this by reassigning the selected approximate multiplier instances to layers at runtime. To combine multiple operating points with the use of retraining, we propose a fine-tuning scheme that shares the majority of parameters between operating points, with only a small amount of additional parameters required per operating point. In our evaluation on MobileNetV2, QoS-Nets is used to select four approximate multiplier instances for three different operating points. These operating points result in power savings for multiplications between 15.3% and 42.8% at a Top-5 accuracy loss between 0.3 and 2.33 percentage points. Through our fine-tuning scheme, all three operating points only increase the model's parameter count by only 2.75%.
Temporal Decisions: Leveraging Temporal Correlation for Efficient Decisions in Early Exit Neural Networks
Mar 12, 2024



Deep Learning is becoming increasingly relevant in Embedded and Internet-of-things applications. However, deploying models on embedded devices poses a challenge due to their resource limitations. This can impact the model's inference accuracy and latency. One potential solution are Early Exit Neural Networks, which adjust model depth dynamically through additional classifiers attached between their hidden layers. However, the real-time termination decision mechanism is critical for the system's efficiency, latency, and sustained accuracy. This paper introduces Difference Detection and Temporal Patience as decision mechanisms for Early Exit Neural Networks. They leverage the temporal correlation present in sensor data streams to efficiently terminate the inference. We evaluate their effectiveness in health monitoring, image classification, and wake-word detection tasks. Our novel contributions were able to reduce the computational footprint compared to established decision mechanisms significantly while maintaining higher accuracy scores. We achieved a reduction of mean operations per inference by up to 80% while maintaining accuracy levels within 5% of the original model. These findings highlight the importance of considering temporal correlation in sensor data to improve the termination decision.
Efficient Post-Training Augmentation for Adaptive Inference in Heterogeneous and Distributed IoT Environments
Mar 12, 2024



Early Exit Neural Networks (EENNs) present a solution to enhance the efficiency of neural network deployments. However, creating EENNs is challenging and requires specialized domain knowledge, due to the large amount of additional design choices. To address this issue, we propose an automated augmentation flow that focuses on converting an existing model into an EENN. It performs all required design decisions for the deployment to heterogeneous or distributed hardware targets: Our framework constructs the EENN architecture, maps its subgraphs to the hardware targets, and configures its decision mechanism. To the best of our knowledge, it is the first framework that is able to perform all of these steps. We evaluated our approach on a collection of Internet-of-Things and standard image classification use cases. For a speech command detection task, our solution was able to reduce the mean operations per inference by 59.67%. For an ECG classification task, it was able to terminate all samples early, reducing the mean inference energy by 74.9% and computations by 78.3%. On CIFAR-10, our solution was able to achieve up to a 58.75% reduction in computations. The search on a ResNet-152 base model for CIFAR-10 took less than nine hours on a laptop CPU. Our proposed approach enables the creation of EENN optimized for IoT environments and can reduce the inference cost of Deep Learning applications on embedded and fog platforms, while also significantly reducing the search cost - making it more accessible for scientists and engineers in industry and research. The low search cost improves the accessibility of EENNs, with the potential to improve the efficiency of neural networks in a wide range of practical applications.
Temporal Patience: Efficient Adaptive Deep Learning for Embedded Radar Data Processing
Sep 11, 2023



Radar sensors offer power-efficient solutions for always-on smart devices, but processing the data streams on resource-constrained embedded platforms remains challenging. This paper presents novel techniques that leverage the temporal correlation present in streaming radar data to enhance the efficiency of Early Exit Neural Networks for Deep Learning inference on embedded devices. These networks add additional classifier branches between the architecture's hidden layers that allow for an early termination of the inference if their result is deemed sufficient enough by an at-runtime decision mechanism. Our methods enable more informed decisions on when to terminate the inference, reducing computational costs while maintaining a minimal loss of accuracy. Our results demonstrate that our techniques save up to 26% of operations per inference over a Single Exit Network and 12% over a confidence-based Early Exit version. Our proposed techniques work on commodity hardware and can be combined with traditional optimizations, making them accessible for resource-constrained embedded platforms commonly used in smart devices. Such efficiency gains enable real-time radar data processing on resource-constrained platforms, allowing for new applications in the context of smart homes, Internet-of-Things, and human-computer interaction.
Convolutional Neural Networks Quantization with Attention
Sep 30, 2022



It has been proven that, compared to using 32-bit floating-point numbers in the training phase, Deep Convolutional Neural Networks (DCNNs) can operate with low precision during inference, thereby saving memory space and power consumption. However, quantizing networks is always accompanied by an accuracy decrease. Here, we propose a method, double-stage Squeeze-and-Threshold (double-stage ST). It uses the attention mechanism to quantize networks and achieve state-of-art results. Using our method, the 3-bit model can achieve accuracy that exceeds the accuracy of the full-precision baseline model. The proposed double-stage ST activation quantization is easy to apply: inserting it before the convolution.
Combining Gradients and Probabilities for Heterogeneous Approximation of Neural Networks
Aug 15, 2022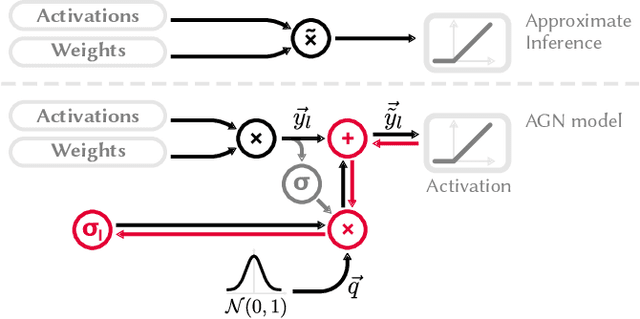
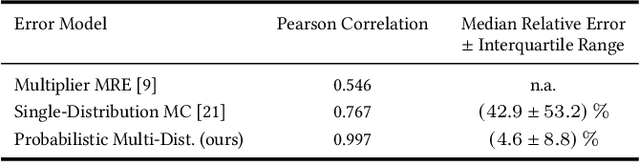
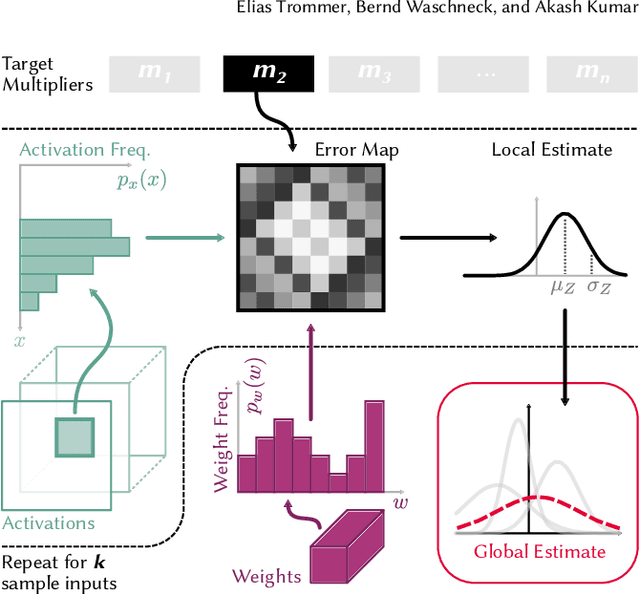
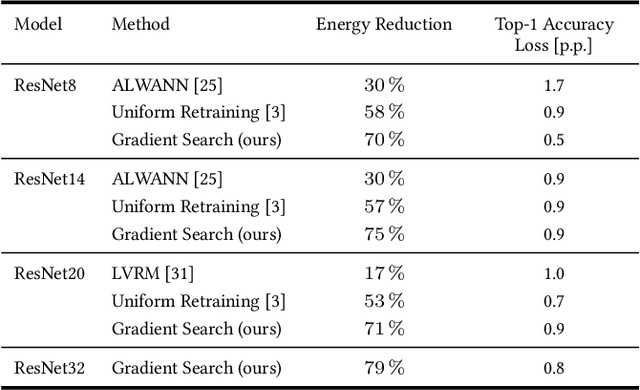
This work explores the search for heterogeneous approximate multiplier configurations for neural networks that produce high accuracy and low energy consumption. We discuss the validity of additive Gaussian noise added to accurate neural network computations as a surrogate model for behavioral simulation of approximate multipliers. The continuous and differentiable properties of the solution space spanned by the additive Gaussian noise model are used as a heuristic that generates meaningful estimates of layer robustness without the need for combinatorial optimization techniques. Instead, the amount of noise injected into the accurate computations is learned during network training using backpropagation. A probabilistic model of the multiplier error is presented to bridge the gap between the domains; the model estimates the standard deviation of the approximate multiplier error, connecting solutions in the additive Gaussian noise space to actual hardware instances. Our experiments show that the combination of heterogeneous approximation and neural network retraining reduces the energy consumption for multiplications by 70% to 79% for different ResNet variants on the CIFAR-10 dataset with a Top-1 accuracy loss below one percentage point. For the more complex Tiny ImageNet task, our VGG16 model achieves a 53 % reduction in energy consumption with a drop in Top-5 accuracy of 0.5 percentage points. We further demonstrate that our error model can predict the parameters of an approximate multiplier in the context of the commonly used additive Gaussian noise (AGN) model with high accuracy. Our software implementation is available under https://github.com/etrommer/agn-approx.
Small-Footprint Keyword Spotting on Raw Audio Data with Sinc-Convolutions
Nov 05, 2019
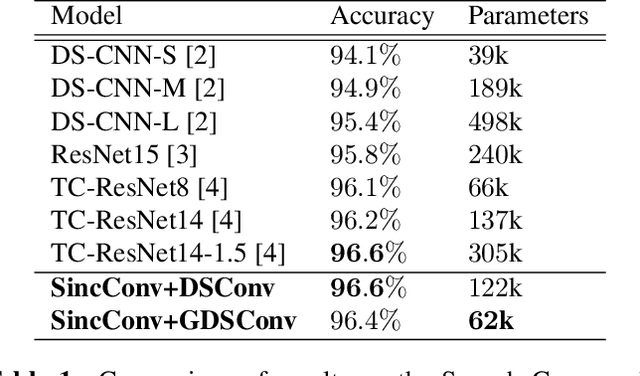

Keyword Spotting (KWS) enables speech-based user interaction on smart devices. Always-on and battery-powered application scenarios for smart devices put constraints on hardware resources and power consumption, while also demanding high accuracy as well as real-time capability. Previous architectures first extracted acoustic features and then applied a neural network to classify keyword probabilities, optimizing towards memory footprint and execution time. Compared to previous publications, we took additional steps to reduce power and memory consumption without reducing classification accuracy. Power-consuming audio preprocessing and data transfer steps are eliminated by directly classifying from raw audio. For this, our end-to-end architecture extracts spectral features using parametrized Sinc-convolutions. Its memory footprint is further reduced by grouping depthwise separable convolutions. Our network achieves the competitive accuracy of 96.4% on Google's Speech Commands test set with only 62k parameters.