 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-Footprint Keyword Spotting on Raw Audio Data with Sinc-Convolutions
Paper and Code

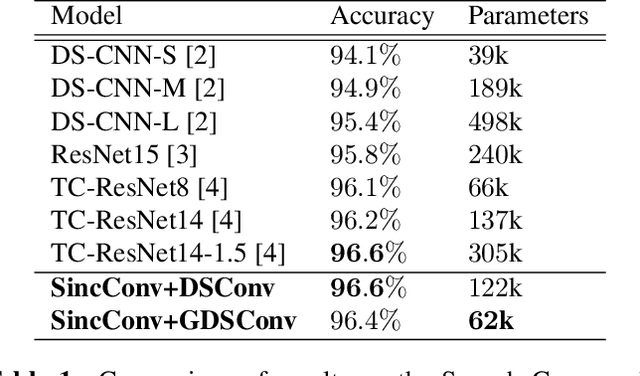

Keyword Spotting (KWS) enables speech-based user interaction on smart devices. Always-on and battery-powered application scenarios for smart devices put constraints on hardware resources and power consumption, while also demanding high accuracy as well as real-time capability. Previous architectures first extracted acoustic features and then applied a neural network to classify keyword probabilities, optimizing towards memory footprint and execution time. Compared to previous publications, we took additional steps to reduce power and memory consumption without reducing classification accuracy. Power-consuming audio preprocessing and data transfer steps are eliminated by directly classifying from raw audio. For this, our end-to-end architecture extracts spectral features using parametrized Sinc-convolutions. Its memory footprint is further reduced by grouping depthwise separable convolutions. Our network achieves the competitive accuracy of 96.4% on Google's Speech Commands test set with only 62k parameters.