 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sample Complexity of Rank Regression from Pairwise Comparisons
May 04, 2021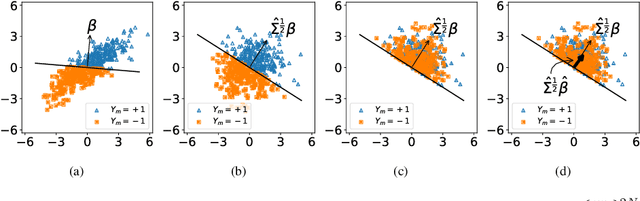

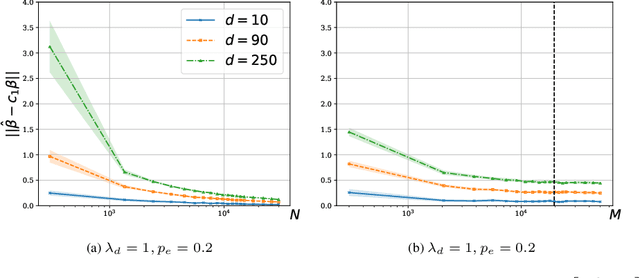
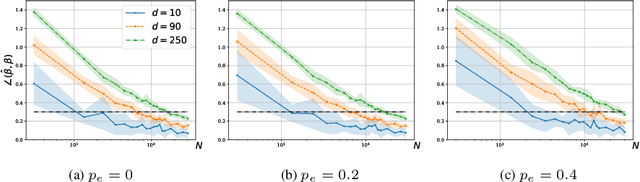
We consider a rank regression setting, in which a dataset of $N$ samples with features in $\mathbb{R}^d$ is ranked by an oracle via $M$ pairwise comparisons. Specifically, there exists a latent total ordering of the samples; when presented with a pair of samples, a noisy oracle identifies the one ranked higher with respect to the underlying total ordering. A learner observes a dataset of such comparisons and wishes to regress sample ranks from their features. We show that to learn the model parameters with $\epsilon > 0$ accuracy, it suffices to conduct $M \in \Omega(dN\log^3 N/\epsilon^2)$ comparisons uniformly at random when $N$ is $\Omega(d/\epsilon^2)$.
An empirical study of Conv-TasNet
Feb 24, 2020



Conv-TasNet is a recently proposed waveform-based deep neural network that achieves state-of-the-art performance in speech source separation. Its architecture consists of a learnable encoder/decoder and a separator that operates on top of this learned space. Various improvements have been proposed to Conv-TasNet. However, they mostly focus on the separator, leaving its encoder/decoder as a (shallow) linear operator. In this paper, we conduct an empirical study of Conv-TasNet and propose an enhancement to the encoder/decoder that is based on a (deep) non-linear variant of it. In addition, we experiment with the larger and more diverse LibriTTS dataset and investigate the generalization capabilities of the studied models when trained on a much larger dataset. We propose cross-dataset evaluation that includes assessing separations from the WSJ0-2mix, LibriTTS and VCTK databases. Our results show that enhancements to the encoder/decoder can improve average SI-SNR performance by more than 1 dB. Furthermore, we offer insights into the generalization capabilities of Conv-TasNet and the potential value of improvements to the encoder/decoder.