 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Saccade-inspired Approach to Image Classification using Vision Transformer Attention Maps
Mar 11, 2026Human vision achieves remarkable perceptual performance while operating under strict metabolic constraints. A key ingredient is the selective attention mechanism, driven by rapid saccadic eye movements that constantly reposition the high-resolution fovea onto task-relevant locations, unlike conventional AI systems that process entire images with equal emphasis. Our work aims to draw inspiration from the human visual system to create smarter, more efficient image processing models. Using DINO, a self-supervised Vision Transformer that produces attention maps strikingly similar to human gaze patterns, we explore a saccade inspired method to focus the processing of information on key regions in visual space. To do so, we use the ImageNet dataset in a standard classification task and measure how each successive saccade affects the model's class scores. This selective-processing strategy preserves most of the full-image classification performance and can even outperform it in certain cases. By benchmarking against established saliency models built for human gaze prediction, we demonstrate that DINO provides superior fixation guidance for selecting informative regions. These findings highlight Vision Transformer attention as a promising basis for biologically inspired active vision and open new directions for efficient, neuromorphic visual processing.
Spiking monocular event based 6D pose estimation for space application
Jan 06, 2025With the growing interest in on On-orbit servicing (OOS) and Active Debris Removal (ADR) missions, spacecraft poses estimation algorithms are being developed using deep learning to improve the precision of this complex task and find the most efficient solution. With the advances of bio-inspired low-power solutions, such a spiking neural networks and event-based processing and cameras, and their recent work for space applications, we propose to investigate the feasibility of a fully event-based solution to improve event-based pose estimation for spacecraft. In this paper, we address the first event-based dataset SEENIC with real event frames captured by an event-based camera on a testbed. We show the methods and results of the first event-based solution for this use case, where our small spiking end-to-end network (S2E2) solution achieves interesting results over 21cm position error and 14degree rotation error, which is the first step towards fully event-based processing for embedded spacecraft pose estimation.
* 6 pages, 2 figures, 1 table. This paper has been presented in the Thursday 19 September poster session at the SPAICE 2024 conference (17-19 September 2024)
Neural information coding for efficient spike-based image denoising
May 15, 2023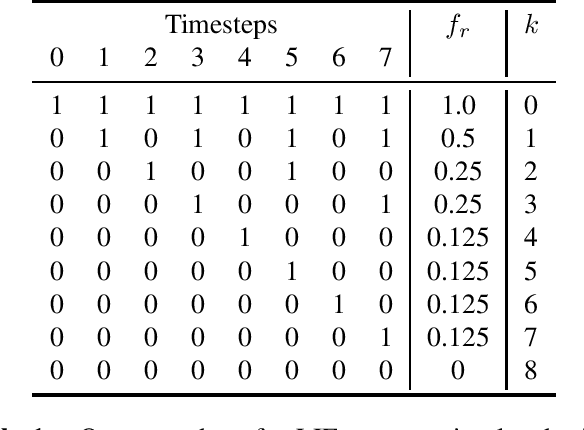
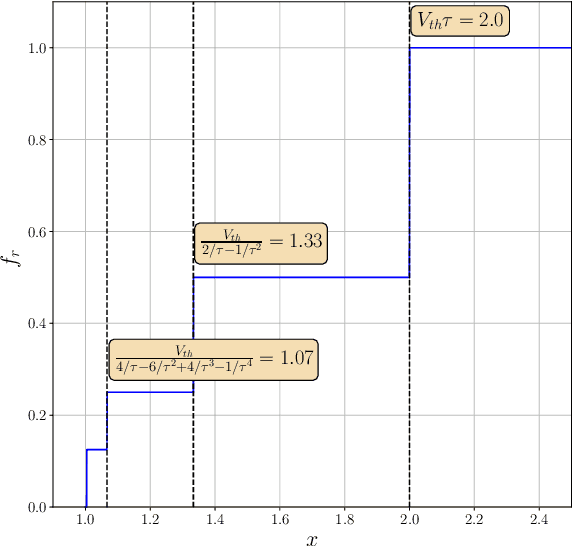
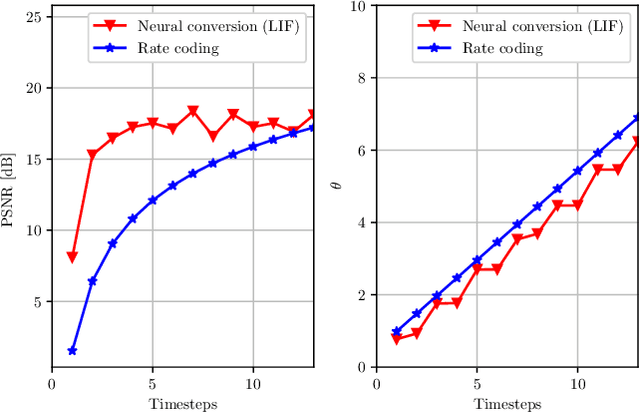
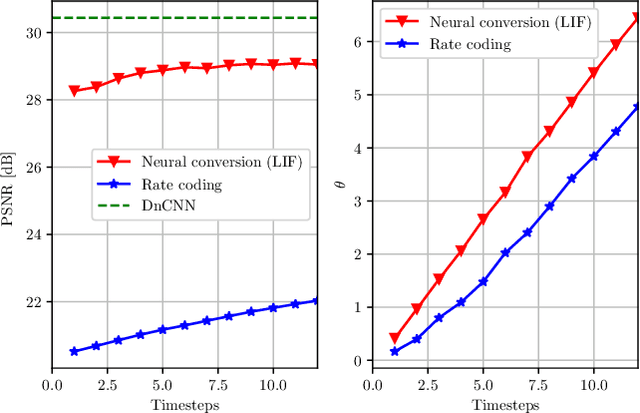
In recent years, Deep Convolutional Neural Networks (DCNNs) have outreached the performance of classical algorithms for image restoration tasks. However most of these methods are not suited for computational efficiency and are therefore too expensive to be executed on embedded and mobile devices. In this work we investigate Spiking Neural Networks (SNNs) for Gaussian denoising, with the goal of approaching the performance of conventional DCNN while reducing the computational load. We propose a formal analysis of the information conversion processing carried out by the Leaky Integrate and Fire (LIF) neurons and we compare its performance with the classical rate-coding mechanism. The neural coding schemes are then evaluated through experiments in terms of denoising performance and computation efficiency for a state-of-the-art deep convolutional neural network. Our results show that SNNs with LIF neurons can provide competitive denoising performance but at a reduced computational cost.
Object Detection with Spiking Neural Networks on Automotive Event Data
May 09, 2022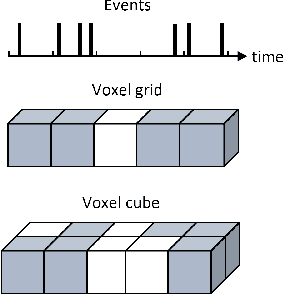

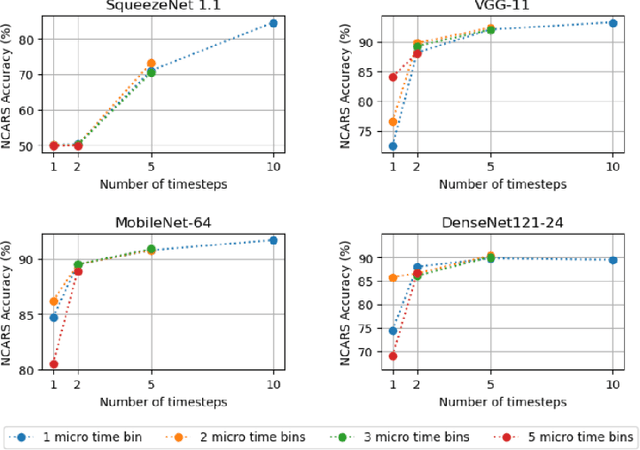
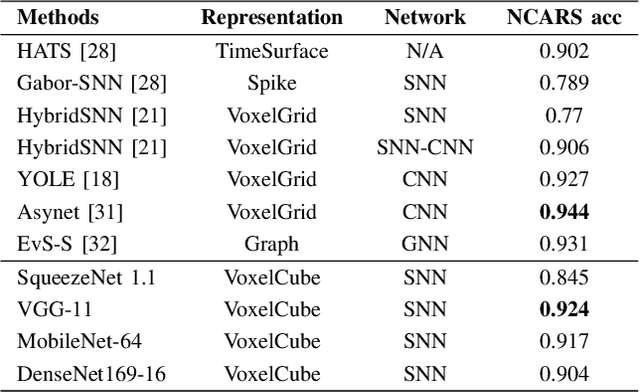
Automotive embedded algorithms have very high constraints in terms of latency, accuracy and power consumption. In this work, we propose to train spiking neural networks (SNNs) directly on data coming from event cameras to design fast and efficient automotive embedded applications. Indeed, SNNs are more biologically realistic neural networks where neurons communicate using discrete and asynchronous spikes, a naturally energy-efficient and hardware friendly operating mode. Event data, which are binary and sparse in space and time, are therefore the ideal input for spiking neural networks. But to date, their performance was insufficient for automotive real-world problems, such as detecting complex objects in an uncontrolled environment. To address this issue, we took advantage of the latest advancements in matter of spike backpropagation - surrogate gradient learning, parametric LIF, SpikingJelly framework - and of our new \textit{voxel cube} event encoding to train 4 different SNNs based on popular deep learning networks: SqueezeNet, VGG, MobileNet, and DenseNet. As a result, we managed to increase the size and the complexity of SNNs usually considered in the literature. In this paper, we conducted experiments on two automotive event datasets, establishing new state-of-the-art classification results for spiking neural networks. Based on these results, we combined our SNNs with SSD to propose the first spiking neural networks capable of performing object detection on the complex GEN1 Automotive Detection event dataset.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021

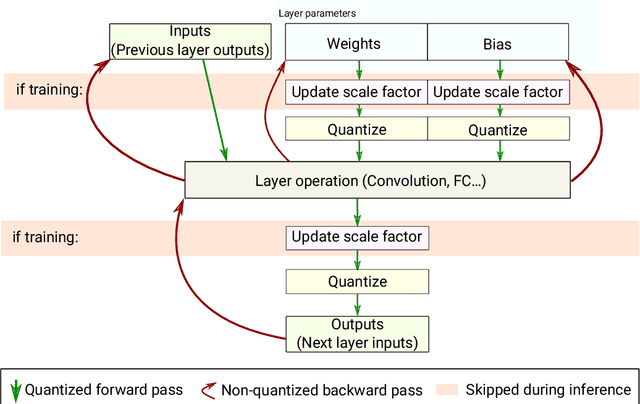
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984
Learning from Event Cameras with Sparse Spiking Convolutional Neural Networks
Apr 26, 2021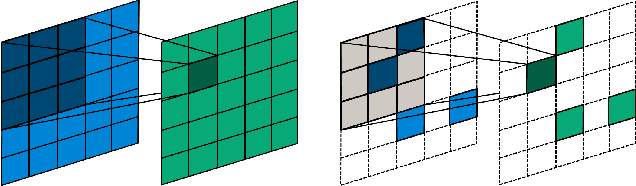
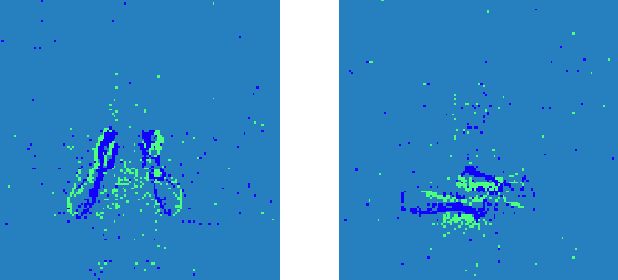
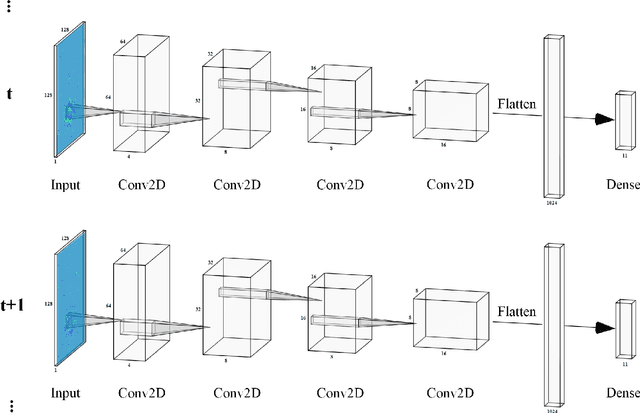
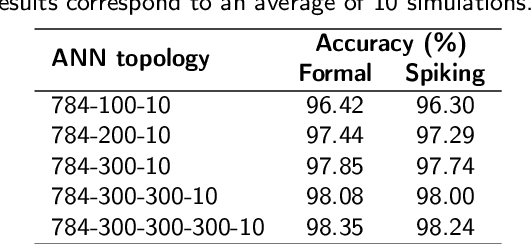
Convolutional neural networks (CNNs) are now the de facto solution for computer vision problems thanks to their impressive results and ease of learning. These networks are composed of layers of connected units called artificial neurons, loosely modeling the neurons in a biological brain. However, their implementation on conventional hardware (CPU/GPU) results in high power consumption, making their integration on embedded systems difficult. In a car for example, embedded algorithms have very high constraints in term of energy, latency and accuracy. To design more efficient computer vision algorithms, we propose to follow an end-to-end biologically inspired approach using event cameras and spiking neural networks (SNNs). Event cameras output asynchronous and sparse events, providing an incredibly efficient data source, but processing these events with synchronous and dense algorithms such as CNNs does not yield any significant benefits. To address this limitation, we use spiking neural networks (SNNs), which are more biologically realistic neural networks where units communicate using discrete spikes. Due to the nature of their operations, they are hardware friendly and energy-efficient, but training them still remains a challenge. Our method enables the training of sparse spiking convolutional neural networks directly on event data, using the popular deep learning framework PyTorch. The performances in terms of accuracy, sparsity and training time on the popular DVS128 Gesture Dataset make it possible to use this bio-inspired approach for the future embedding of real-time applications on low-power neuromorphic hardware.
Design Space Exploration of Hardware Spiking Neurons for Embedded Artificial Intelligence
Oct 01, 2019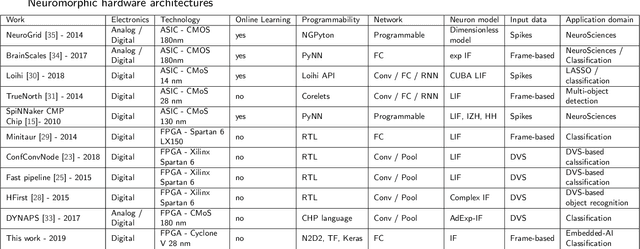

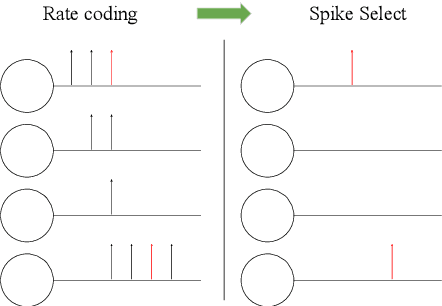
Machine learning is yielding unprecedented interest in research and industry, due to recent success in many applied contexts such as image classification and object recognition. However, the deployment of these systems requires huge computing capabilities, thus making them unsuitable for embedded systems. To deal with this limitation, many researchers are investigating brain-inspired computing, which would be a perfect alternative to the conventional Von Neumann architecture based computers (CPU/GPU) that meet the requirements for computing performance, but not for energy-efficiency. Therefore, neuromorphic hardware circuits that are adaptable for both parallel and distributed computations need to be designed. In this paper, we focus on Spiking Neural Networks (SNNs) with a comprehensive study of information coding methods and hardware exploration. In this context, we propose a framework for neuromorphic hardware design space exploration, which allows to define a suitable architecture based on application-specific constraints and starting from a wide variety of possible architectural choices. For this framework, we have developed a behavioral level simulator for neuromorphic hardware architectural exploration named NAXT. Moreover, we propose modified versions of the standard Rate Coding technique to make trade-offs with the Time Coding paradigm, which is characterized by the low number of spikes propagating in the network. Thus, we are able to reduce the number of spikes while keeping the same neuron's model, which results in an SNN with fewer events to process. By doing so, we seek to reduce the amount of power consumed by the hardware. Furthermore, we present three neuromorphic hardware architectures in order to quantitatively study the implementation of SNNs. These architectures are derived from a novel funnel-like Design Space Exploration framework for neuromorphic hardware.