 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded event based object detection with spiking neural network
Jun 25, 2024The complexity of event-based object detection (OD) poses considerable challenges. Spiking Neural Networks (SNNs) show promising results and pave the way for efficient event-based OD. Despite this success, the path to efficient SNNs on embedded devices remains a challenge. This is due to the size of the networks required to accomplish the task and the ability of devices to take advantage of SNNs benefits. Even when "edge" devices are considered, they typically use embedded GPUs that consume tens of watts. In response to these challenges, our research introduces an embedded neuromorphic testbench that utilizes the SPiking Low-power Event-based ArchiTecture (SPLEAT) accelerator. Using an extended version of the Qualia framework, we can train, evaluate, quantize, and deploy spiking neural networks on an FPGA implementation of SPLEAT. We used this testbench to load a state-of-the-art SNN solution, estimate the performance loss associated with deploying the network on dedicated hardware, and run real-world event-based OD on neuromorphic hardware specifically designed for low-power spiking neural networks. Remarkably, our embedded spiking solution, which includes a model with 1.08 million parameters, operates efficiently with 490 mJ per prediction.
Quantization and Deployment of Deep Neural Networks on Microcontrollers
May 27, 2021
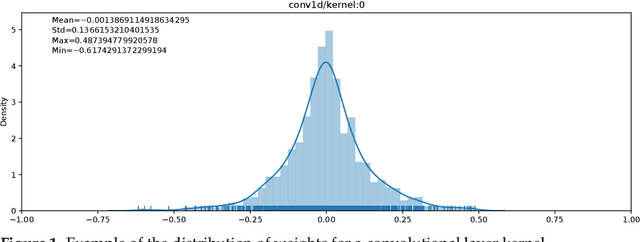

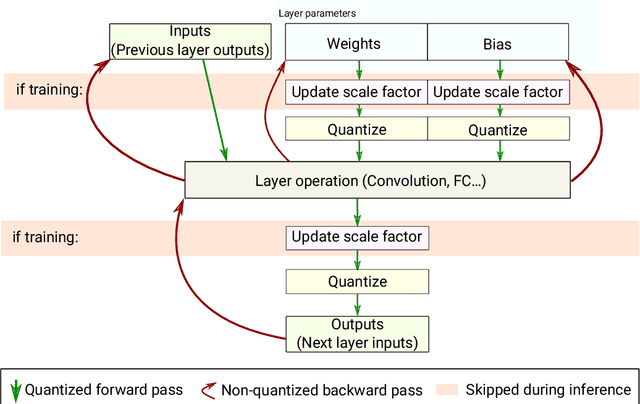
Embedding Artificial Intelligence onto low-power devices is a challenging task that has been partly overcome with recent advances in machine learning and hardware design. Presently, deep neural networks can be deployed on embedded targets to perform different tasks such as speech recognition,object detection or Human Activity Recognition. However, there is still room for optimization of deep neural networks onto embedded devices. These optimizations mainly address power consumption,memory and real-time constraints, but also an easier deployment at the edge. Moreover, there is still a need for a better understanding of what can be achieved for different use cases. This work focuses on quantization and deployment of deep neural networks onto low-power 32-bit microcontrollers. The quantization methods, relevant in the context of an embedded execution onto a microcontroller, are first outlined. Then, a new framework for end-to-end deep neural networks training, quantization and deployment is presented. This framework, called MicroAI, is designed as an alternative to existing inference engines (TensorFlow Lite for Microcontrollers and STM32Cube.AI). Our framework can indeed be easily adjusted and/or extended for specific use cases. Execution using single precision 32-bit floating-point as well as fixed-point on 8- and 16-bit integers are supported. The proposed quantization method is evaluated with three different datasets (UCI-HAR, Spoken MNIST and GTSRB). Finally, a comparison study between MicroAI and both existing embedded inference engines is provided in terms of memory and power efficiency. On-device evaluation is done using ARM Cortex-M4F-based microcontrollers (Ambiq Apollo3 and STM32L452RE).
* 36 pages, 14 figures. Published in MDPI Sensors 2021, special issue "Embedded Artificial Intelligence (AI) for Smart Sensing and IoT Applications": https://www.mdpi.com/1424-8220/21/9/2984