 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedded event based object detection with spiking neural network
Jun 25, 2024The complexity of event-based object detection (OD) poses considerable challenges. Spiking Neural Networks (SNNs) show promising results and pave the way for efficient event-based OD. Despite this success, the path to efficient SNNs on embedded devices remains a challenge. This is due to the size of the networks required to accomplish the task and the ability of devices to take advantage of SNNs benefits. Even when "edge" devices are considered, they typically use embedded GPUs that consume tens of watts. In response to these challenges, our research introduces an embedded neuromorphic testbench that utilizes the SPiking Low-power Event-based ArchiTecture (SPLEAT) accelerator. Using an extended version of the Qualia framework, we can train, evaluate, quantize, and deploy spiking neural networks on an FPGA implementation of SPLEAT. We used this testbench to load a state-of-the-art SNN solution, estimate the performance loss associated with deploying the network on dedicated hardware, and run real-world event-based OD on neuromorphic hardware specifically designed for low-power spiking neural networks. Remarkably, our embedded spiking solution, which includes a model with 1.08 million parameters, operates efficiently with 490 mJ per prediction.
Design Space Exploration of Hardware Spiking Neurons for Embedded Artificial Intelligence
Oct 01, 2019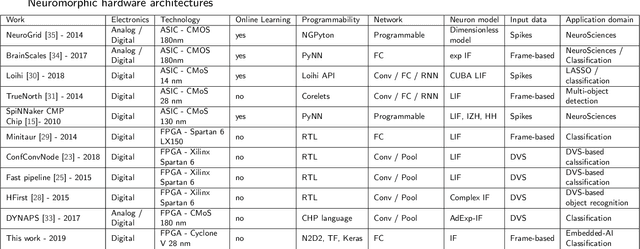

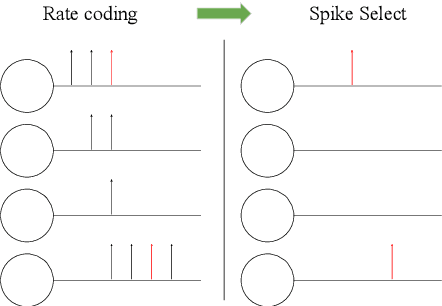
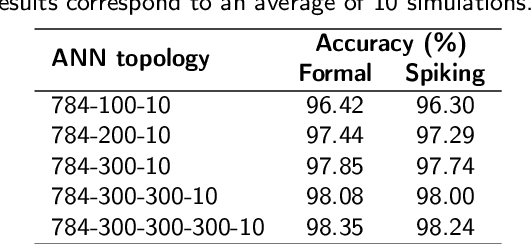
Machine learning is yielding unprecedented interest in research and industry, due to recent success in many applied contexts such as image classification and object recognition. However, the deployment of these systems requires huge computing capabilities, thus making them unsuitable for embedded systems. To deal with this limitation, many researchers are investigating brain-inspired computing, which would be a perfect alternative to the conventional Von Neumann architecture based computers (CPU/GPU) that meet the requirements for computing performance, but not for energy-efficiency. Therefore, neuromorphic hardware circuits that are adaptable for both parallel and distributed computations need to be designed. In this paper, we focus on Spiking Neural Networks (SNNs) with a comprehensive study of information coding methods and hardware exploration. In this context, we propose a framework for neuromorphic hardware design space exploration, which allows to define a suitable architecture based on application-specific constraints and starting from a wide variety of possible architectural choices. For this framework, we have developed a behavioral level simulator for neuromorphic hardware architectural exploration named NAXT. Moreover, we propose modified versions of the standard Rate Coding technique to make trade-offs with the Time Coding paradigm, which is characterized by the low number of spikes propagating in the network. Thus, we are able to reduce the number of spikes while keeping the same neuron's model, which results in an SNN with fewer events to process. By doing so, we seek to reduce the amount of power consumed by the hardware. Furthermore, we present three neuromorphic hardware architectures in order to quantitatively study the implementation of SNNs. These architectures are derived from a novel funnel-like Design Space Exploration framework for neuromorphic hardware.