 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning-based social coordination to improve safety and robustness of cooperative autonomous vehicles in mixed traffic
Nov 22, 2022It is expected that autonomous vehicles(AVs) and heterogeneous human-driven vehicles(HVs) will coexist on the same road. The safety and reliability of AVs will depend on their social awareness and their ability to engage in complex social interactions in a socially accepted manner. However, AVs are still inefficient in terms of cooperating with HVs and struggle to understand and adapt to human behavior, which is particularly challenging in mixed autonomy. In a road shared by AVs and HVs, the social preferences or individual traits of HVs are unknown to the AVs and different from AVs, which are expected to follow a policy, HVs are particularly difficult to forecast since they do not necessarily follow a stationary policy. To address these challenges, we frame the mixed-autonomy problem as a multi-agent reinforcement learning (MARL) problem and propose an approach that allows AVs to learn the decision-making of HVs implicitly from experience, account for all vehicles' interests, and safely adapt to other traffic situations. In contrast with existing works, we quantify AVs' social preferences and propose a distributed reward structure that introduces altruism into their decision-making process, allowing the altruistic AVs to learn to establish coalitions and influence the behavior of HVs.
Prediction-aware and Reinforcement Learning based Altruistic Cooperative Driving
Nov 19, 2022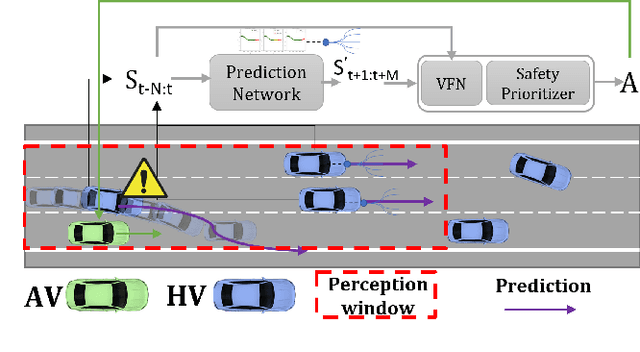
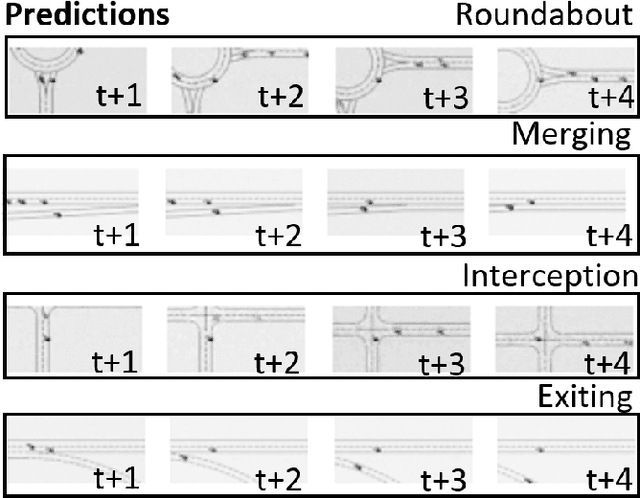
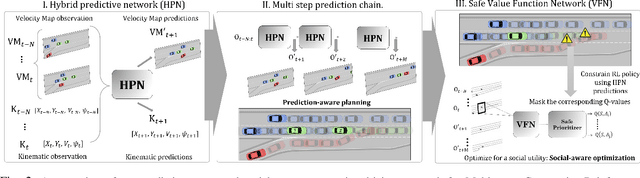
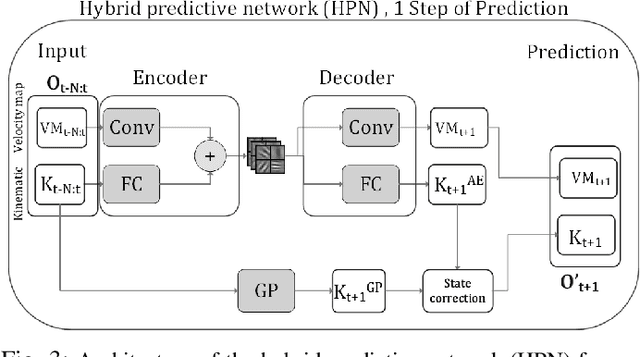
Autonomous vehicle (AV) navigation in the presence of Human-driven vehicles (HVs) is challenging, as HVs continuously update their policies in response to AVs. In order to navigate safely in the presence of complex AV-HV social interactions, the AVs must learn to predict these changes. Humans are capable of navigating such challenging social interaction settings because of their intrinsic knowledge about other agents behaviors and use that to forecast what might happen in the future. Inspired by humans, we provide our AVs the capability of anticipating future states and leveraging prediction in a cooperative reinforcement learning (RL) decision-making framework, to improve safety and robustness. In this paper, we propose an integration of two essential and earlier-presented components of AVs: social navigation and prediction. We formulate the AV decision-making process as a RL problem and seek to obtain optimal policies that produce socially beneficial results utilizing a prediction-aware planning and social-aware optimization RL framework. We also propose a Hybrid Predictive Network (HPN) that anticipates future observations. The HPN is used in a multi-step prediction chain to compute a window of predicted future observations to be used by the value function network (VFN). Finally, a safe VFN is trained to optimize a social utility using a sequence of previous and predicted observations, and a safety prioritizer is used to leverage the interpretable kinematic predictions to mask the unsafe actions, constraining the RL policy. We compare our prediction-aware AV to state-of-the-art solutions and demonstrate performance improvements in terms of efficiency and safety in multiple simulated scenarios.
Robustness and Adaptability of Reinforcement Learning based Cooperative Autonomous Driving in Mixed-autonomy Traffic
Feb 02, 2022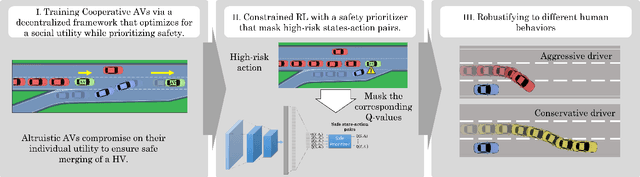
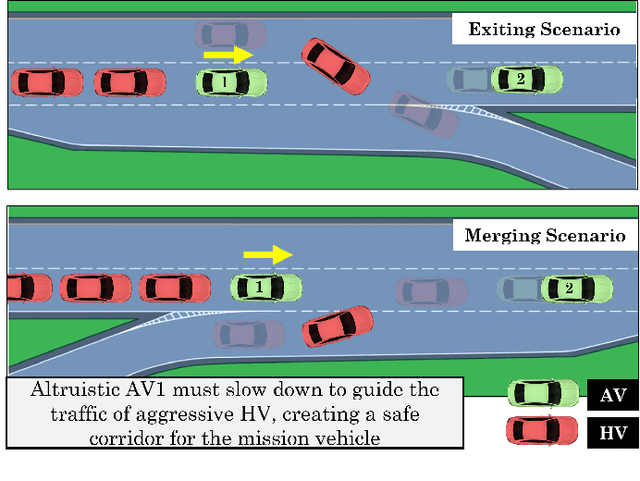
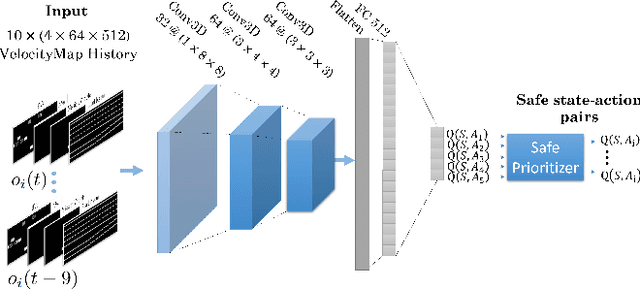
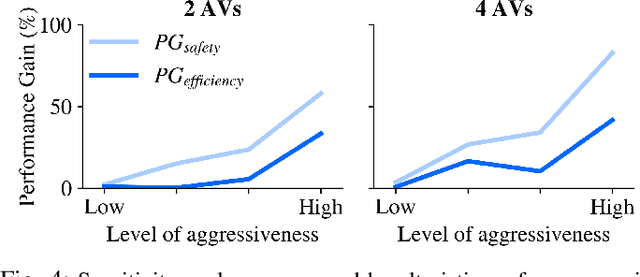
Building autonomous vehicles (AVs) is a complex problem, but enabling them to operate in the real world where they will be surrounded by human-driven vehicles (HVs) is extremely challenging. Prior works have shown the possibilities of creating inter-agent cooperation between a group of AVs that follow a social utility. Such altruistic AVs can form alliances and affect the behavior of HVs to achieve socially desirable outcomes. We identify two major challenges in the co-existence of AVs and HVs. First, social preferences and individual traits of a given human driver, e.g., selflessness and aggressiveness are unknown to an AV, and it is almost impossible to infer them in real-time during a short AV-HV interaction. Second, contrary to AVs that are expected to follow a policy, HVs do not necessarily follow a stationary policy and therefore are extremely hard to predict. To alleviate the above-mentioned challenges, we formulate the mixed-autonomy problem as a multi-agent reinforcement learning (MARL) problem and propose a decentralized framework and reward function for training cooperative AVs. Our approach enables AVs to learn the decision-making of HVs implicitly from experience, optimizes for a social utility while prioritizing safety and allowing adaptability; robustifying altruistic AVs to different human behaviors and constraining them to a safe action space. Finally, we investigate the robustness, safety and sensitivity of AVs to various HVs behavioral traits and present the settings in which the AVs can learn cooperative policies that are adaptable to different situations.
Towards Learning Generalizable Driving Policies from Restricted Latent Representations
Nov 05, 2021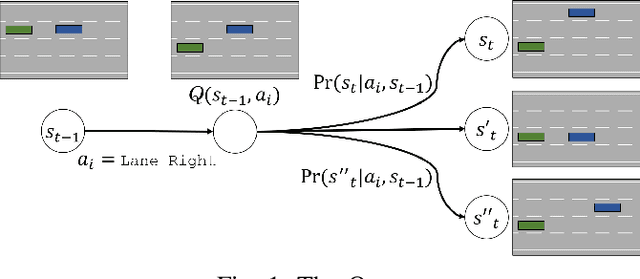
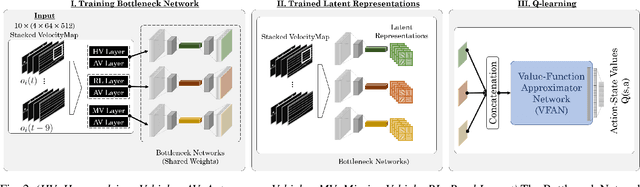
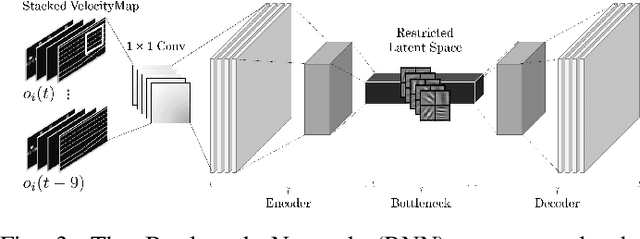
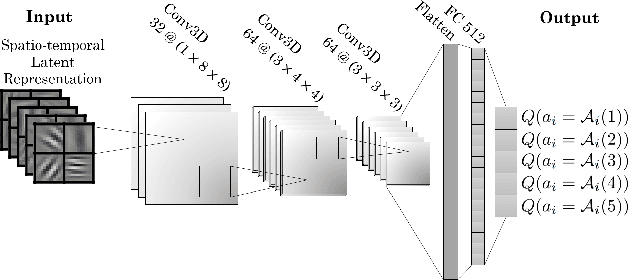
Training intelligent agents that can drive autonomously in various urban and highway scenarios has been a hot topic in the robotics society within the last decades. However, the diversity of driving environments in terms of road topology and positioning of the neighboring vehicles makes this problem very challenging. It goes without saying that although scenario-specific driving policies for autonomous driving are promising and can improve transportation safety and efficiency, they are clearly not a universal scalable solution. Instead, we seek decision-making schemes and driving policies that can generalize to novel and unseen environments. In this work, we capitalize on the key idea that human drivers learn abstract representations of their surroundings that are fairly similar among various driving scenarios and environments. Through these representations, human drivers are able to quickly adapt to novel environments and drive in unseen conditions. Formally, through imposing an information bottleneck, we extract a latent representation that minimizes the \textit{distance} -- a quantification that we introduce to gauge the similarity among different driving configurations -- between driving scenarios. This latent space is then employed as the input to a Q-learning module to learn generalizable driving policies. Our experiments revealed that, using this latent representation can reduce the number of crashes to about half.
Social Coordination and Altruism in Autonomous Driving
Jul 20, 2021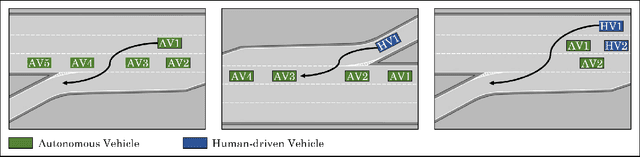
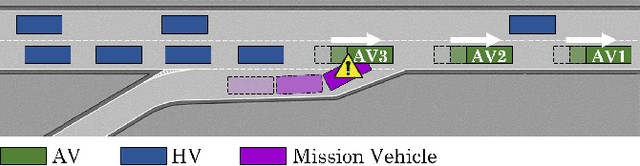
Despite the advances in the autonomous driving domain, autonomous vehicles (AVs) are still inefficient and limited in terms of cooperating with each other or coordinating with vehicles operated by humans. A group of autonomous and human-driven vehicles (HVs) which work together to optimize an altruistic social utility -- as opposed to the egoistic individual utility -- can co-exist seamlessly and assure safety and efficiency on the road. Achieving this mission without explicit coordination among agents is challenging, mainly due to the difficulty of predicting the behavior of humans with heterogeneous preferences in mixed-autonomy environments. Formally, we model an AV's maneuver planning in mixed-autonomy traffic as a partially-observable stochastic game and attempt to derive optimal policies that lead to socially-desirable outcomes using a multi-agent reinforcement learning framework. We introduce a quantitative representation of the AVs' social preferences and design a distributed reward structure that induces altruism into their decision making process. Our altruistic AVs are able to form alliances, guide the traffic, and affect the behavior of the HVs to handle competitive driving scenarios. As a case study, we compare egoistic AVs to our altruistic autonomous agents in a highway merging setting and demonstrate the emerging behaviors that lead to a noticeable improvement in the number of successful merges as well as the overall traffic flow and safety.
Altruistic Maneuver Planning for Cooperative Autonomous Vehicles Using Multi-agent Advantage Actor-Critic
Jul 12, 2021

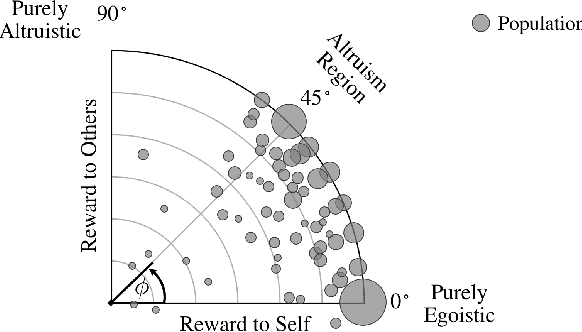
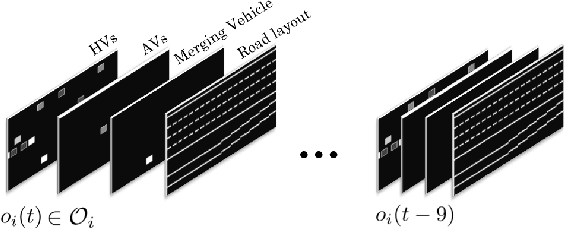
With the adoption of autonomous vehicles on our roads, we will witness a mixed-autonomy environment where autonomous and human-driven vehicles must learn to co-exist by sharing the same road infrastructure. To attain socially-desirable behaviors, autonomous vehicles must be instructed to consider the utility of other vehicles around them in their decision-making process. Particularly, we study the maneuver planning problem for autonomous vehicles and investigate how a decentralized reward structure can induce altruism in their behavior and incentivize them to account for the interest of other autonomous and human-driven vehicles. This is a challenging problem due to the ambiguity of a human driver's willingness to cooperate with an autonomous vehicle. Thus, in contrast with the existing works which rely on behavior models of human drivers, we take an end-to-end approach and let the autonomous agents to implicitly learn the decision-making process of human drivers only from experience. We introduce a multi-agent variant of the synchronous Advantage Actor-Critic (A2C) algorithm and train agents that coordinate with each other and can affect the behavior of human drivers to improve traffic flow and safety.
Cooperative Autonomous Vehicles that Sympathize with Human Drivers
Jul 02, 2021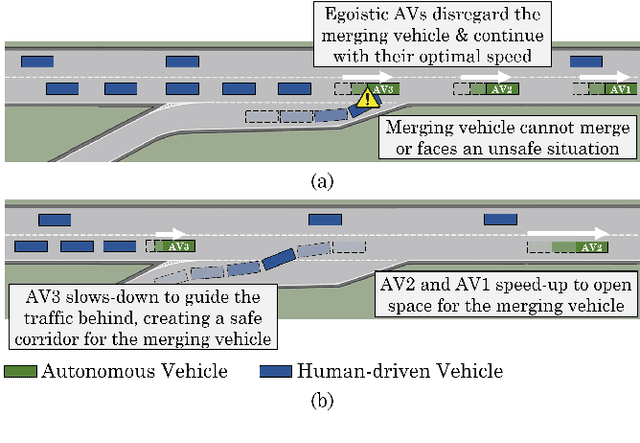
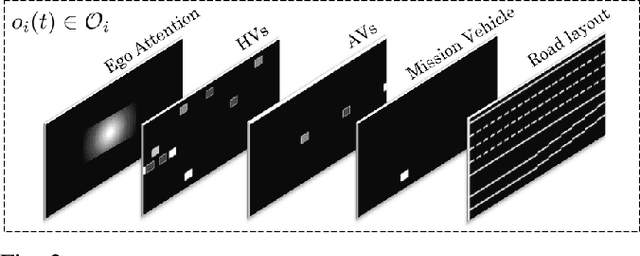
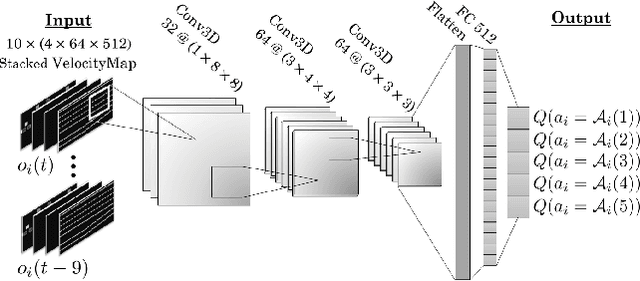
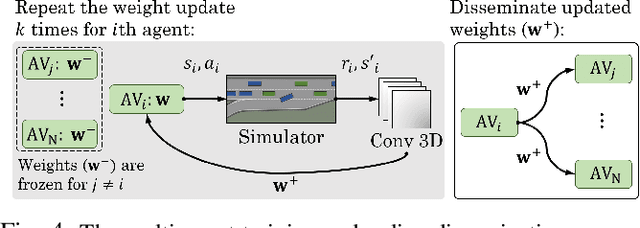
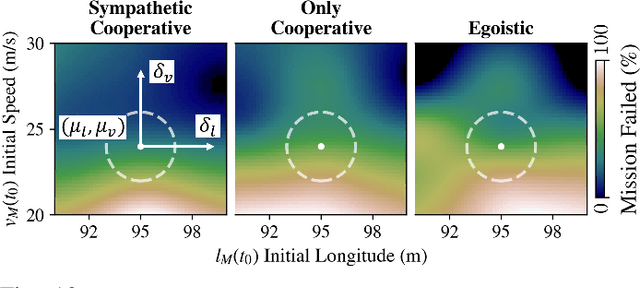
Widespread adoption of autonomous vehicles will not become a reality until solutions are developed that enable these intelligent agents to co-exist with humans. This includes safely and efficiently interacting with human-driven vehicles, especially in both conflictive and competitive scenarios. We build up on the prior work on socially-aware navigation and borrow the concept of social value orientation from psychology -- that formalizes how much importance a person allocates to the welfare of others -- in order to induce altruistic behavior in autonomous driving. In contrast with existing works that explicitly model the behavior of human drivers and rely on their expected response to create opportunities for cooperation, our Sympathetic Cooperative Driving (SymCoDrive) paradigm trains altruistic agents that realize safe and smooth traffic flow in competitive driving scenarios only from experiential learning and without any explicit coordination. We demonstrate a significant improvement in both safety and traffic-level metrics as a result of this altruistic behavior and importantly conclude that the level of altruism in agents requires proper tuning as agents that are too altruistic also lead to sub-optimal traffic flow. The code and supplementary material are available at: https://symcodrive.toghi.net/
A Maneuver-based Urban Driving Dataset and Model for Cooperative Vehicle Applications
Jun 08, 2020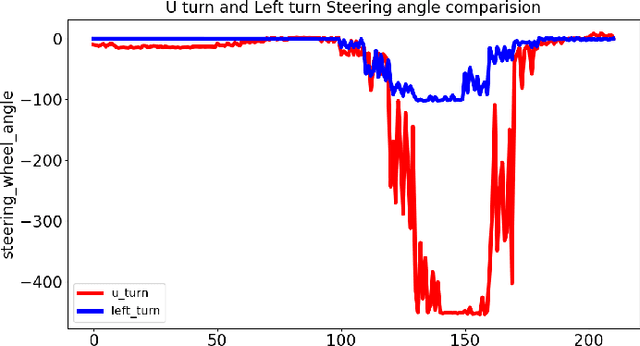
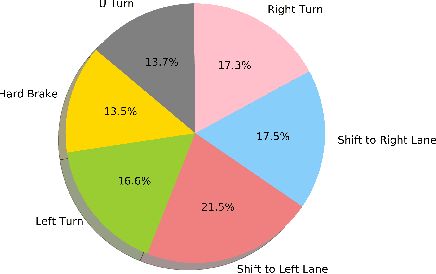
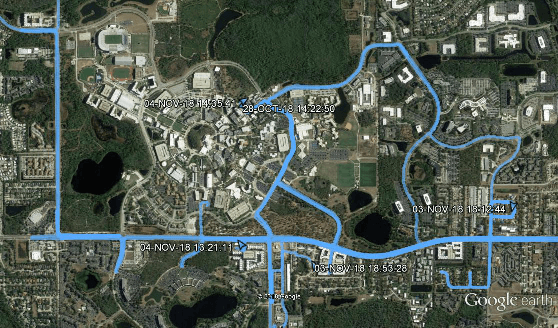
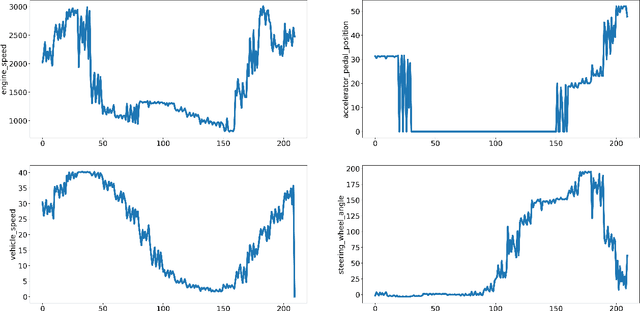
Short-term future of automated driving can be imagined as a hybrid scenario in which both automated and human-driven vehicles co-exist in the same environment. In order to address the needs of such road configuration, many technology solutions such as vehicular communication and predictive control for automated vehicles have been introduced in the literature. Both aforementioned solutions rely on driving data of the human driver. In this work, we investigate the currently available driving datasets and introduce a real-world maneuver-based driving dataset that is collected during our urban driving data collection campaign. We also provide a model that embeds the patterns in maneuver-specific samples. Such model can be employed for classification and prediction purposes.
V2X System Architecture Utilizing Hybrid Gaussian Process-based Model Structures
Mar 06, 2019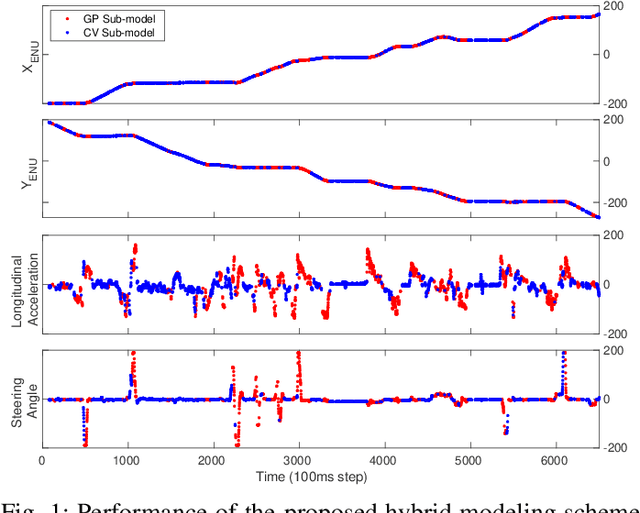

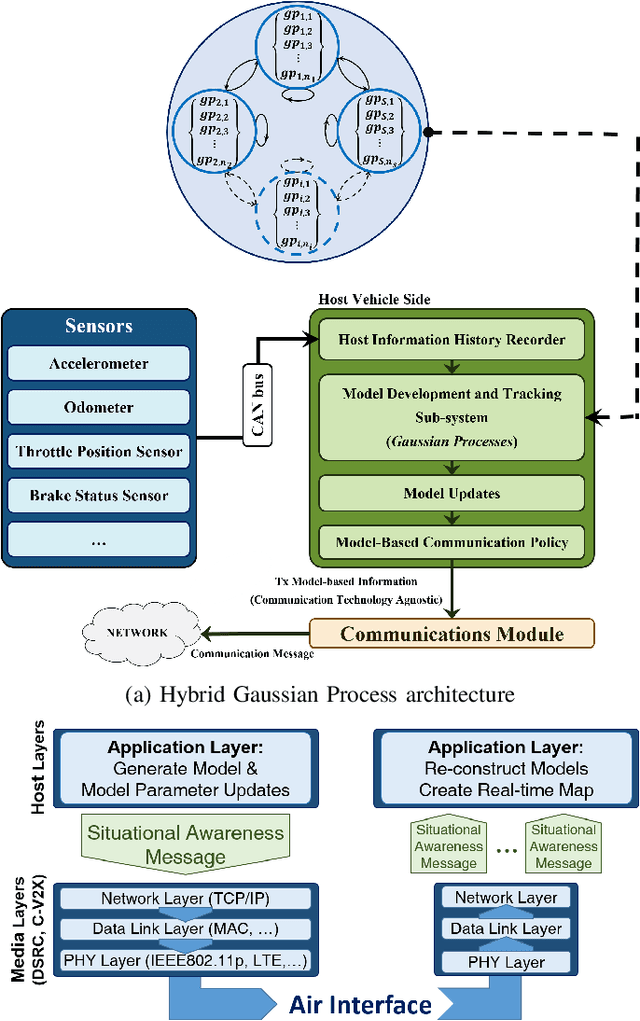
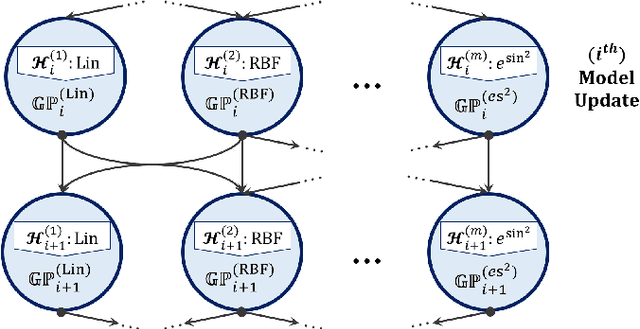
Scalable communication is of utmost importance for reliable dissemination of time-sensitive information in cooperative vehicular ad-hoc networks (VANETs), which is, in turn, an essential prerequisite for the proper operation of the critical cooperative safety applications. The model-based communication (MBC) is a recently-explored scalability solution proposed in the literature, which has shown a promising potential to reduce the channel congestion to a great extent. In this work, based on the MBC notion, a technology-agnostic hybrid model selection policy for Vehicle-to-Everything (V2X) communication is proposed which benefits from the characteristics of the non-parametric Bayesian inference techniques, specifically Gaussian Processes. The results show the effectiveness of the proposed communication architecture on both reducing the required message exchange rate and increasing the remote agent tracking precision.
MNIST Dataset Classification Utilizing k-NN Classifier with Modified Sliding Window Metric
Oct 02, 2018
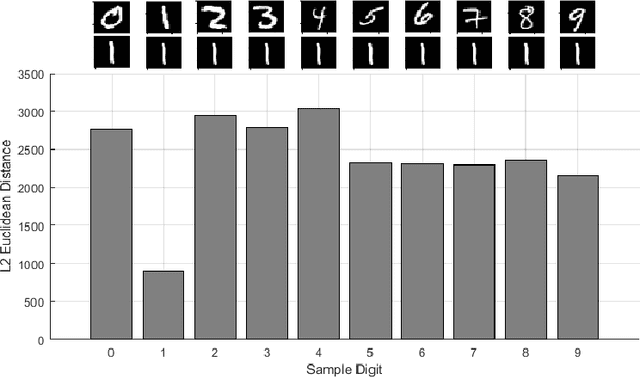

The MNIST dataset of the handwritten digits is known as one of the commonly used datasets for machine learning and computer vision research. We aim a widely applicable classification problem and apply a simple but still efficient K-nearest neighbor classifier with an enhanced heuristic. We evaluate the performance of the K-nearest neighbor classification algorithm on the MNIST dataset where the L2 Euclidean distance metric is compared to a modified distance metric which utilizes the sliding window technique in order to avoid performance degradation due to slight spatial misalignment. Accuracy metric and confusion matrices are used as the performance indicators to compare the performance of the baseline algorithm versus the enhanced sliding window method and results show significant improvement using this simple method.