 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwitter Referral Behaviours on News Consumption with Ensemble Clustering of Click-Stream Data in Turkish Media
Feb 04, 2022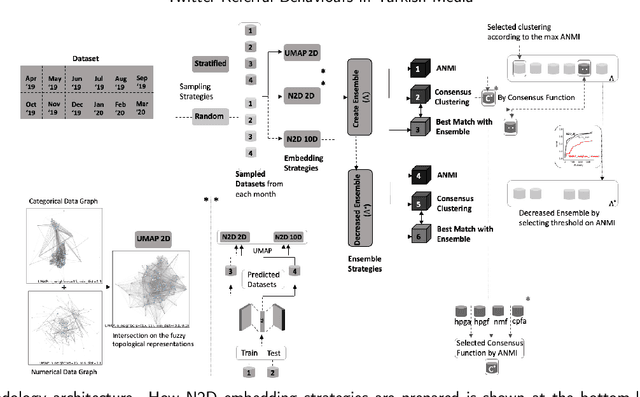
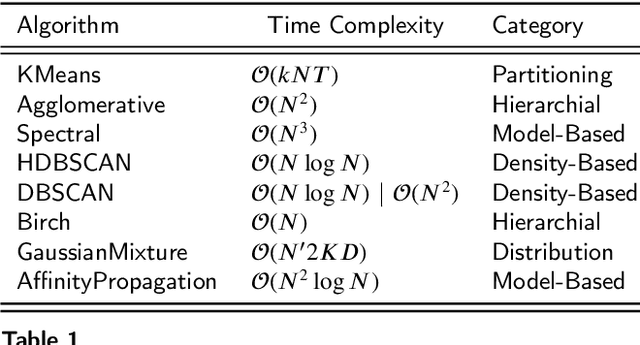
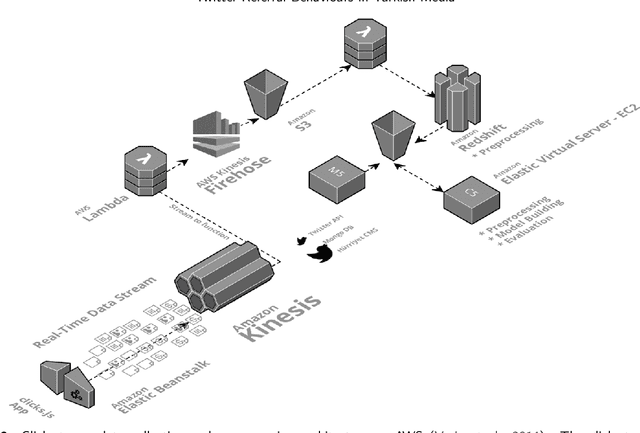
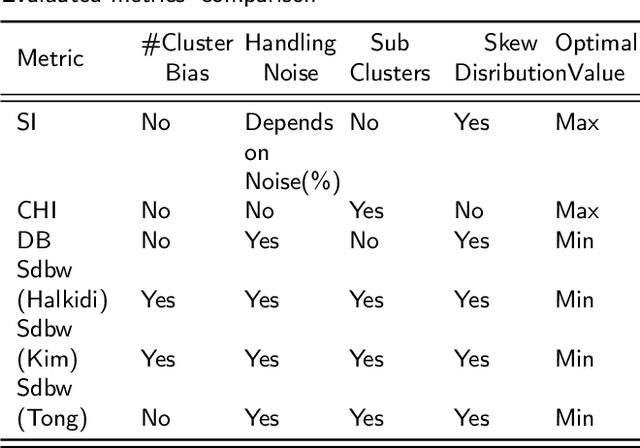
Click-stream data, which comes with a massive volume generated by the human activities on the websites, has become a prominent feature to identify readers' characteristics by the newsrooms after the digitization of the news outlets. It is essential to have elastic architectures to process the streaming data, particularly for unprecedented traffic, enabling conducting more comprehensive analyses such as recommending mostly related articles to the readers. Although the nature of click-stream data has a similar logic within the websites, it has inherent limitations to recognize human behaviors when looking from a broad perspective, which brings the need of limiting the problem in niche areas. This study investigates the anonymized readers' click activities in the organizations' websites to identify news consumption patterns following referrals from Twitter, who incidentally reach but propensity is mainly the routed news content. The investigation is widened to a broad perspective by linking the log data with news content to enrich the insights rather than sticking into the web journey. The methodologies on ensemble cluster analysis with mixed-type embedding strategies are applied and compared to find similar reader groups and interests independent from time. Our results demonstrate that the quality of clustering mixed-type data set approaches to optimal internal validation scores when embedded by Uniform Manifold Approximation and Projection (UMAP) and using consensus function as a key to access the most applicable hyper parameter configurations in the given ensemble rather than using consensus function results directly. Evaluation of the resulting clusters highlights specific clusters repeatedly present in the samples, which provide insights to the news organizations and overcome the degradation of the modeling behaviors due to the change in the interest over time.
PURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021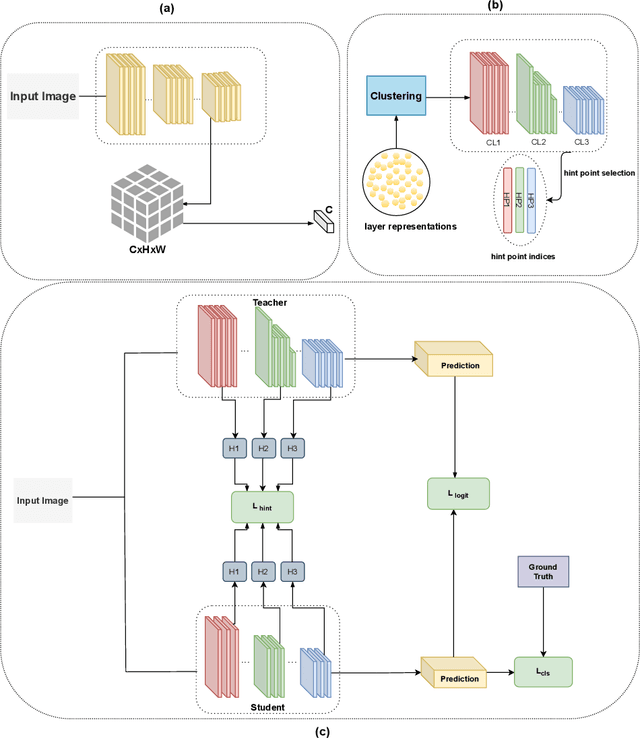
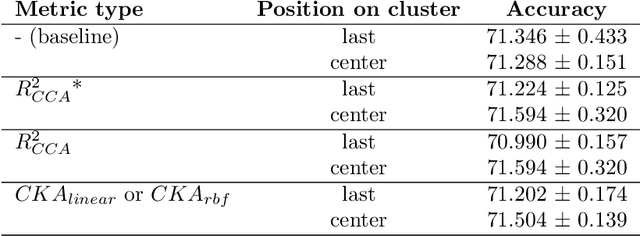
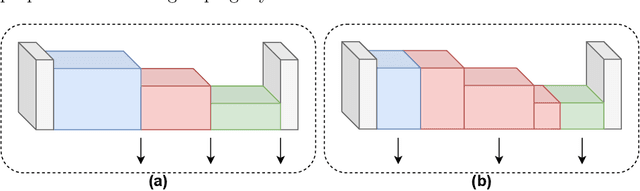
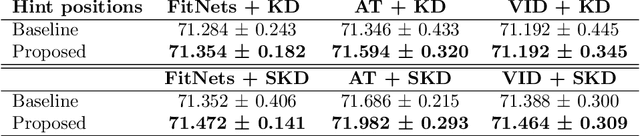
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.
A Whole Slide Image Grading Benchmark and Tissue Classification for Cervical Cancer Precursor Lesions with Inter-Observer Variability
Dec 26, 2018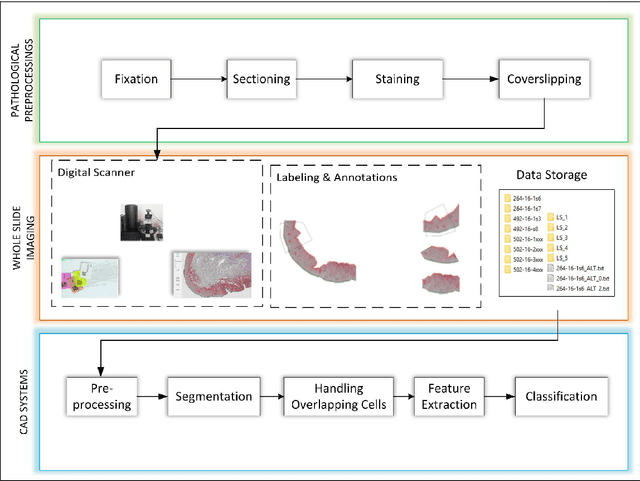

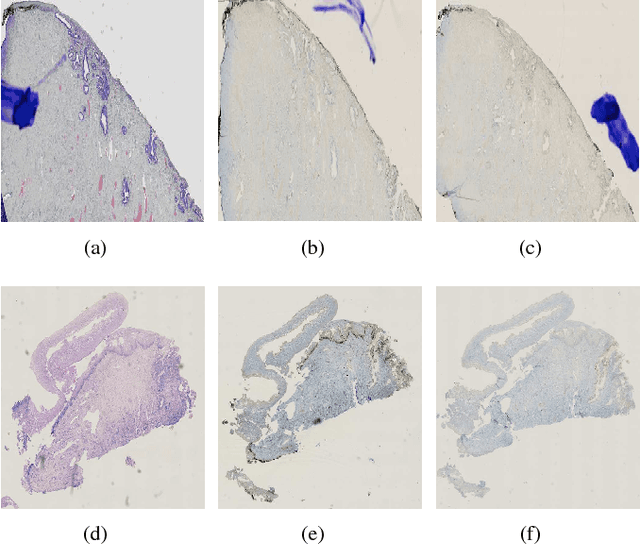

The cervical cancer developing from the precancerous lesions caused by the Human Papilloma Virus (HPV) has been one of the preventable cancers with the help of periodic screening. There are two types of grading conventions widely accepted among pathologists. On the other hand, inter-observer variability is an important issue for final diagnosis. In this paper, a whole-slide image grading benchmark for cervical cancer precursor lesions is introduced. The papillae of the cervical epithelium and overlapping cell problems are handled and a tissue classification method with a novel morphological feature exploiting the relative orientation between the BM and the major axis of all nuclei is developed and its performance is evaluated. Besides, the inter-observer variability is also revealed by a thorough comparison among pathologists' decisions, as well as, the final diagnosis.
Online Adaptive Decision Fusion Framework Based on Entropic Projections onto Convex Sets with Application to Wildfire Detection in Video
Jan 25, 2011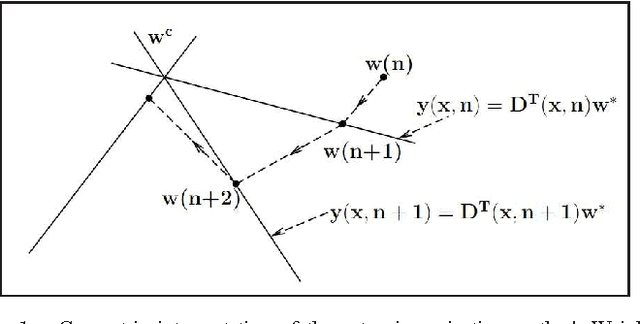



In this paper, an Entropy functional based online Adaptive Decision Fusion (EADF) framework is developed for image analysis and computer vision applications. In this framework, it is assumed that the compound algorithm consists of several sub-algorithms each of which yielding its own decision as a real number centered around zero, representing the confidence level of that particular sub-algorithm. Decision values are linearly combined with weights which are updated online according to an active fusion method based on performing entropic projections onto convex sets describing sub-algorithms. It is assumed that there is an oracle, who is usually a human operator, providing feedback to the decision fusion method. A video based wildfire detection system is developed to evaluate the performance of the algorithm in handling the problems where data arrives sequentially. In this case, the oracle is the security guard of the forest lookout tower verifying the decision of the combined algorithm. Simulation results are presented. The EADF framework is also tested with a standard dataset.