 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePURSUhInT: In Search of Informative Hint Points Based on Layer Clustering for Knowledge Distillation
Feb 26, 2021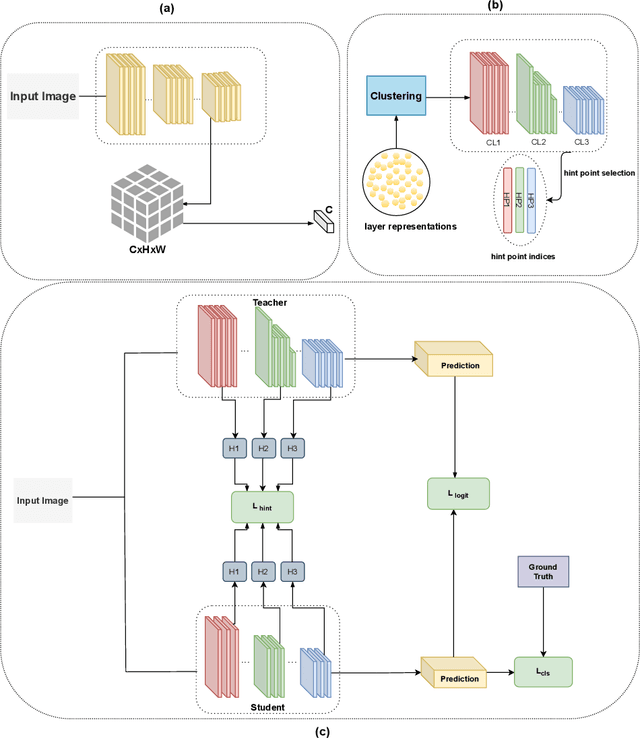
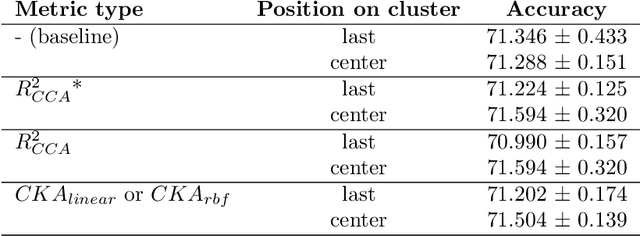
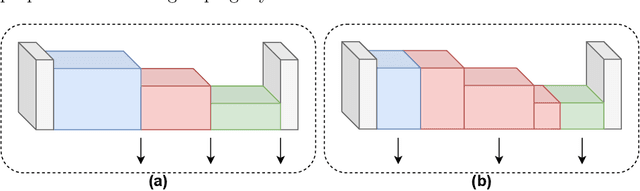
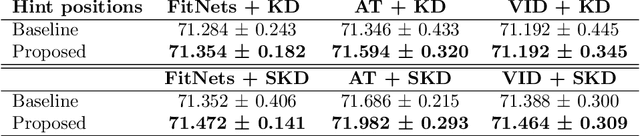
We propose a novel knowledge distillation methodology for compressing deep neural networks. One of the most efficient methods for knowledge distillation is hint distillation, where the student model is injected with information (hints) from several different layers of the teacher model. Although the selection of hint points can drastically alter the compression performance, there is no systematic approach for selecting them, other than brute-force hyper-parameter search. We propose a clustering based hint selection methodology, where the layers of teacher model are clustered with respect to several metrics and the cluster centers are used as the hint points. The proposed approach is validated in CIFAR-100 dataset, where ResNet-110 network was used as the teacher model. Our results show that hint points selected by our algorithm results in superior compression performance with respect to state-of-the-art knowledge distillation algorithms on the same student models and datasets.