 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Active-Inactive Obstacle Classification for Time-Optimal Collision Avoidance
Mar 20, 2024Time-optimal obstacle avoidance is a prevalent problem encountered in various fields, including robotics and autonomous vehicles, where the task involves determining a path for a moving vehicle to reach its goal while navigating around obstacles within its environment. This problem becomes increasingly challenging as the number of obstacles in the environment rises. We propose an iterative active-inactive obstacle approach, which involves identifying a subset of the obstacles as "active", that considers solely the effect of the "active" obstacles on the path of the moving vehicle. The remaining obstacles are considered "inactive" and are not considered in the path planning process. The obstacles are classified as 'active' on the basis of previous findings derived from prior iterations. This approach allows for a more efficient calculation of the optimal path by reducing the number of obstacles that need to be considered. The effectiveness of the proposed method is demonstrated with two different dynamic models using the various number of obstacles. The results show that the proposed method is able to find the optimal path in a timely manner, while also being able to handle a large number of obstacles in the environment and the constraints on the motion of the object.
Reinforcement Learning Based Self-play and State Stacking Techniques for Noisy Air Combat Environment
Mar 06, 2023Reinforcement learning (RL) has recently proven itself as a powerful instrument for solving complex problems and even surpassed human performance in several challenging applications. This signifies that RL algorithms can be used in the autonomous air combat problem, which has been studied for many years. The complexity of air combat arises from aggressive close-range maneuvers and agile enemy behaviors. In addition to these complexities, there may be uncertainties in real-life scenarios due to sensor errors, which prevent estimation of the actual position of the enemy. In this case, autonomous aircraft should be successful even in the noisy environments. In this study, we developed an air combat simulation, which provides noisy observations to the agents, therefore, make the air combat problem even more challenging. Thus, we present a state stacking method for noisy RL environments as a noise reduction technique. In our extensive set of experiments, the proposed method significantly outperforms the baseline algorithms in terms of the winning ratio, where the performance improvement is even more pronounced in the high noise levels. In addition, we incorporate a self-play scheme to our training process by periodically updating the enemy with a frozen copy of the training agent. By this way, the training agent performs air combat simulations to an enemy with smarter strategies, which improves the performance and robustness of the agents. In our simulations, we demonstrate that the self-play scheme provides important performance gains compared to the classical RL training.
IQ-Flow: Mechanism Design for Inducing Cooperative Behavior to Self-Interested Agents in Sequential Social Dilemmas
Mar 04, 2023Achieving and maintaining cooperation between agents to accomplish a common objective is one of the central goals of Multi-Agent Reinforcement Learning (MARL). Nevertheless in many real-world scenarios, separately trained and specialized agents are deployed into a shared environment, or the environment requires multiple objectives to be achieved by different coexisting parties. These variations among specialties and objectives are likely to cause mixed motives that eventually result in a social dilemma where all the parties are at a loss. In order to resolve this issue, we propose the Incentive Q-Flow (IQ-Flow) algorithm, which modifies the system's reward setup with an incentive regulator agent such that the cooperative policy also corresponds to the self-interested policy for the agents. Unlike the existing methods that learn to incentivize self-interested agents, IQ-Flow does not make any assumptions about agents' policies or learning algorithms, which enables the generalization of the developed framework to a wider array of applications. IQ-Flow performs an offline evaluation of the optimality of the learned policies using the data provided by other agents to determine cooperative and self-interested policies. Next, IQ-Flow uses meta-gradient learning to estimate how policy evaluation changes according to given incentives and modifies the incentive such that the greedy policy for cooperative objective and self-interested objective yield the same actions. We present the operational characteristics of IQ-Flow in Iterated Matrix Games. We demonstrate that IQ-Flow outperforms the state-of-the-art incentive design algorithm in Escape Room and 2-Player Cleanup environments. We further demonstrate that the pretrained IQ-Flow mechanism significantly outperforms the performance of the shared reward setup in the 2-Player Cleanup environment.
Scalable Planning and Learning Framework Development for Swarm-to-Swarm Engagement Problems
Dec 06, 2022



Development of guidance, navigation and control frameworks/algorithms for swarms attracted significant attention in recent years. That being said, algorithms for planning swarm allocations/trajectories for engaging with enemy swarms is largely an understudied problem. Although small-scale scenarios can be addressed with tools from differential game theory, existing approaches fail to scale for large-scale multi-agent pursuit evasion (PE) scenarios. In this work, we propose a reinforcement learning (RL) based framework to decompose to large-scale swarm engagement problems into a number of independent multi-agent pursuit-evasion games. We simulate a variety of multi-agent PE scenarios, where finite time capture is guaranteed under certain conditions. The calculated PE statistics are provided as a reward signal to the high level allocation layer, which uses an RL algorithm to allocate controlled swarm units to eliminate enemy swarm units with maximum efficiency. We verify our approach in large-scale swarm-to-swarm engagement simulations.
Self-Improving Safety Performance of Reinforcement Learning Based Driving with Black-Box Verification Algorithms
Oct 29, 2022



In this work, we propose a self-improving artificial intelligence system for enhancing the safety performance of reinforcement learning (RL) based autonomous driving (AD) agents based on black-box verification methods. RL methods have enjoyed popularity among AD applications in recent years. That being said, existing RL algorithms' performance strongly depends on the diversity of training scenarios. Lack of safety-critical scenarios in the training phase might lead to poor generalization performance in real-world driving applications. We propose a novel framework, where the weaknesses of the training set are explored via black-box verification methods. After the discovery of AD failure scenarios, the training of the RL agent is re-initiated to improve the performance of the previously unsafe scenarios. Simulation results show that the proposed approach efficiently discovers such safety failures in RL-based adaptive cruise control (ACC) applications and significantly reduces the number of vehicle collisions through iterative applications of our method.
DeFIX: Detecting and Fixing Failure Scenarios with Reinforcement Learning in Imitation Learning Based Autonomous Driving
Oct 29, 2022



Safely navigating through an urban environment without violating any traffic rules is a crucial performance target for reliable autonomous driving. In this paper, we present a Reinforcement Learning (RL) based methodology to DEtect and FIX (DeFIX) failures of an Imitation Learning (IL) agent by extracting infraction spots and re-constructing mini-scenarios on these infraction areas to train an RL agent for fixing the shortcomings of the IL approach. DeFIX is a continuous learning framework, where extraction of failure scenarios and training of RL agents are executed in an infinite loop. After each new policy is trained and added to the library of policies, a policy classifier method effectively decides on which policy to activate at each step during the evaluation. It is demonstrated that even with only one RL agent trained on failure scenario of an IL agent, DeFIX method is either competitive or does outperform state-of-the-art IL and RL based autonomous urban driving benchmarks. We trained and validated our approach on the most challenging map (Town05) of CARLA simulator which involves complex, realistic, and adversarial driving scenarios. The source code is publicly available at https://github.com/data-and-decision-lab/DeFIX
* 6 pages, 4 figures, 2 tables, published in IEEE International Conference on Intelligent Transportation Systems (ITSC), October 12, 2022, Macau, China
A Scalable Reinforcement Learning Approach for Attack Allocation in Swarm to Swarm Engagement Problems
Oct 15, 2022



In this work we propose a reinforcement learning (RL) framework that controls the density of a large-scale swarm for engaging with adversarial swarm attacks. Although there is a significant amount of existing work in applying artificial intelligence methods to swarm control, analysis of interactions between two adversarial swarms is a rather understudied area. Most of the existing work in this subject develop strategies by making hard assumptions regarding the strategy and dynamics of the adversarial swarm. Our main contribution is the formulation of the swarm to swarm engagement problem as a Markov Decision Process and development of RL algorithms that can compute engagement strategies without the knowledge of strategy/dynamics of the adversarial swarm. Simulation results show that the developed framework can handle a wide array of large-scale engagement scenarios in an efficient manner.
Obstacle Identification and Ellipsoidal Decomposition for Fast Motion Planning in Unknown Dynamic Environments
Sep 28, 2022

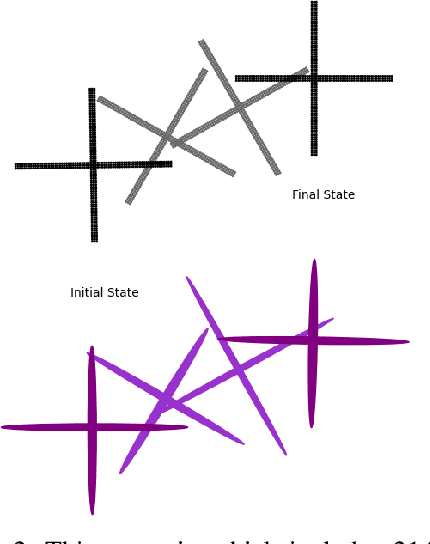

Collision avoidance in the presence of dynamic obstacles in unknown environments is one of the most critical challenges for unmanned systems. In this paper, we present a method that identifies obstacles in terms of ellipsoids to estimate linear and angular obstacle velocities. Our proposed method is based on the idea of any object can be approximately expressed by ellipsoids. To achieve this, we propose a method based on variational Bayesian estimation of Gaussian mixture model, the Kyachiyan algorithm, and a refinement algorithm. Our proposed method does not require knowledge of the number of clusters and can operate in real-time, unlike existing optimization-based methods. In addition, we define an ellipsoid-based feature vector to match obstacles given two timely close point frames. Our method can be applied to any environment with static and dynamic obstacles, including the ones with rotating obstacles. We compare our algorithm with other clustering methods and show that when coupled with a trajectory planner, the overall system can efficiently traverse unknown environments in the presence of dynamic obstacles.
Evaluating Generalization and Transfer Capacity of Multi-Agent Reinforcement Learning Across Variable Number of Agents
Nov 28, 2021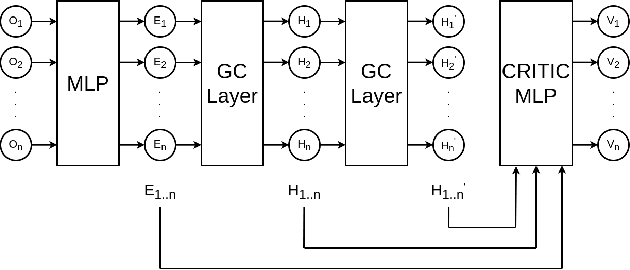


Multi-agent Reinforcement Learning (MARL) problems often require cooperation among agents in order to solve a task. Centralization and decentralization are two approaches used for cooperation in MARL. While fully decentralized methods are prone to converge to suboptimal solutions due to partial observability and nonstationarity, the methods involving centralization suffer from scalability limitations and lazy agent problem. Centralized training decentralized execution paradigm brings out the best of these two approaches; however, centralized training still has an upper limit of scalability not only for acquired coordination performance but also for model size and training time. In this work, we adopt the centralized training with decentralized execution paradigm and investigate the generalization and transfer capacity of the trained models across variable number of agents. This capacity is assessed by training variable number of agents in a specific MARL problem and then performing greedy evaluations with variable number of agents for each training configuration. Thus, we analyze the evaluation performance for each combination of agent count for training versus evaluation. We perform experimental evaluations on predator prey and traffic junction environments and demonstrate that it is possible to obtain similar or higher evaluation performance by training with less agents. We conclude that optimal number of agents to perform training may differ from the target number of agents and argue that transfer across large number of agents can be a more efficient solution to scaling up than directly increasing number of agents during training.
Investigating Value of Curriculum Reinforcement Learning in Autonomous Driving Under Diverse Road and Weather Conditions
Mar 14, 2021
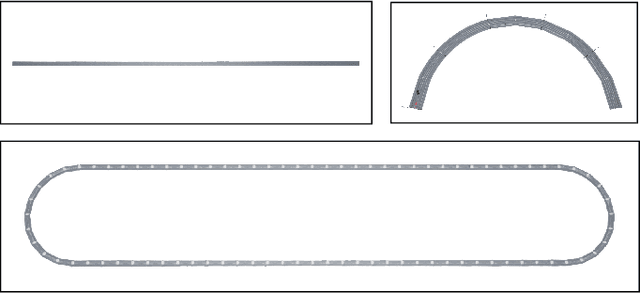
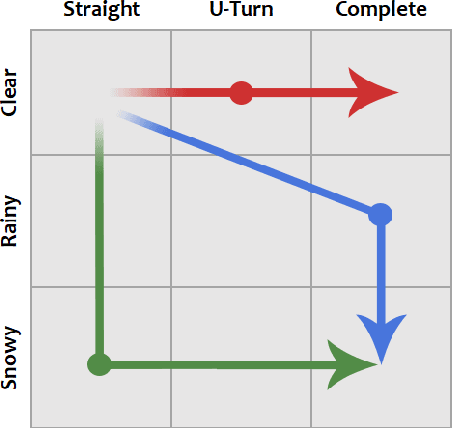
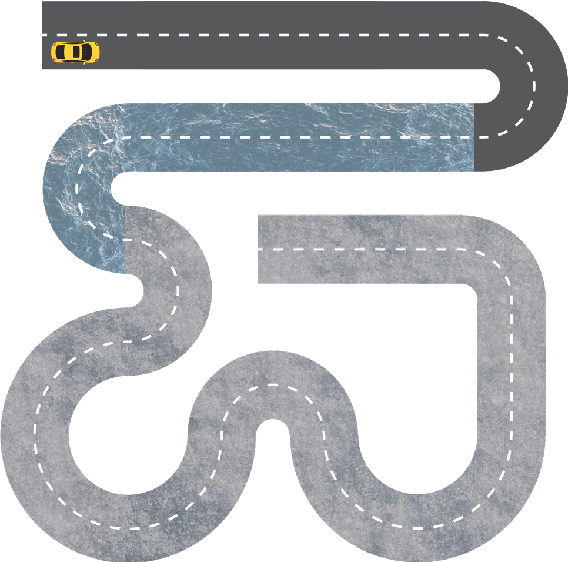
Applications of reinforcement learning (RL) are popular in autonomous driving tasks. That being said, tuning the performance of an RL agent and guaranteeing the generalization performance across variety of different driving scenarios is still largely an open problem. In particular, getting good performance on complex road and weather conditions require exhaustive tuning and computation time. Curriculum RL, which focuses on solving simpler automation tasks in order to transfer knowledge to complex tasks, is attracting attention in RL community. The main contribution of this paper is a systematic study for investigating the value of curriculum reinforcement learning in autonomous driving applications. For this purpose, we setup several different driving scenarios in a realistic driving simulator, with varying road complexity and weather conditions. Next, we train and evaluate performance of RL agents on different sequences of task combinations and curricula. Results show that curriculum RL can yield significant gains in complex driving tasks, both in terms of driving performance and sample complexity. Results also demonstrate that different curricula might enable different benefits, which hints future research directions for automated curriculum training.