 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIQ-Flow: Mechanism Design for Inducing Cooperative Behavior to Self-Interested Agents in Sequential Social Dilemmas
Mar 04, 2023Achieving and maintaining cooperation between agents to accomplish a common objective is one of the central goals of Multi-Agent Reinforcement Learning (MARL). Nevertheless in many real-world scenarios, separately trained and specialized agents are deployed into a shared environment, or the environment requires multiple objectives to be achieved by different coexisting parties. These variations among specialties and objectives are likely to cause mixed motives that eventually result in a social dilemma where all the parties are at a loss. In order to resolve this issue, we propose the Incentive Q-Flow (IQ-Flow) algorithm, which modifies the system's reward setup with an incentive regulator agent such that the cooperative policy also corresponds to the self-interested policy for the agents. Unlike the existing methods that learn to incentivize self-interested agents, IQ-Flow does not make any assumptions about agents' policies or learning algorithms, which enables the generalization of the developed framework to a wider array of applications. IQ-Flow performs an offline evaluation of the optimality of the learned policies using the data provided by other agents to determine cooperative and self-interested policies. Next, IQ-Flow uses meta-gradient learning to estimate how policy evaluation changes according to given incentives and modifies the incentive such that the greedy policy for cooperative objective and self-interested objective yield the same actions. We present the operational characteristics of IQ-Flow in Iterated Matrix Games. We demonstrate that IQ-Flow outperforms the state-of-the-art incentive design algorithm in Escape Room and 2-Player Cleanup environments. We further demonstrate that the pretrained IQ-Flow mechanism significantly outperforms the performance of the shared reward setup in the 2-Player Cleanup environment.
Evaluating Generalization and Transfer Capacity of Multi-Agent Reinforcement Learning Across Variable Number of Agents
Nov 28, 2021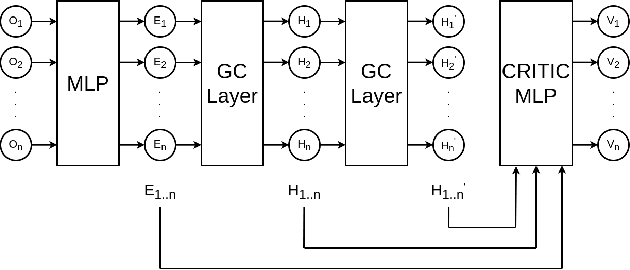


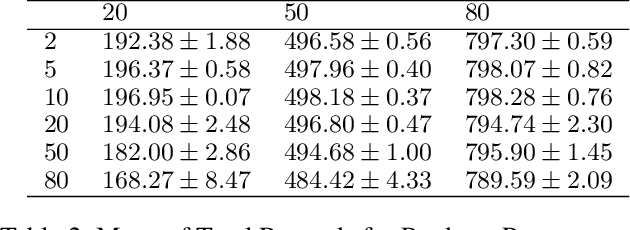
Multi-agent Reinforcement Learning (MARL) problems often require cooperation among agents in order to solve a task. Centralization and decentralization are two approaches used for cooperation in MARL. While fully decentralized methods are prone to converge to suboptimal solutions due to partial observability and nonstationarity, the methods involving centralization suffer from scalability limitations and lazy agent problem. Centralized training decentralized execution paradigm brings out the best of these two approaches; however, centralized training still has an upper limit of scalability not only for acquired coordination performance but also for model size and training time. In this work, we adopt the centralized training with decentralized execution paradigm and investigate the generalization and transfer capacity of the trained models across variable number of agents. This capacity is assessed by training variable number of agents in a specific MARL problem and then performing greedy evaluations with variable number of agents for each training configuration. Thus, we analyze the evaluation performance for each combination of agent count for training versus evaluation. We perform experimental evaluations on predator prey and traffic junction environments and demonstrate that it is possible to obtain similar or higher evaluation performance by training with less agents. We conclude that optimal number of agents to perform training may differ from the target number of agents and argue that transfer across large number of agents can be a more efficient solution to scaling up than directly increasing number of agents during training.