 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Trust Estimation in Human-Robot Collaboration Using Beta Reputation at Fine-grained Timescales
Nov 04, 2024



When interacting with each other, humans adjust their behavior based on perceived trust. However, to achieve similar adaptability, robots must accurately estimate human trust at sufficiently granular timescales during the human-robot collaboration task. A beta reputation is a popular way to formalize a mathematical estimation of human trust. However, it relies on binary performance, which updates trust estimations only after each task concludes. Additionally, manually crafting a reward function is the usual method of building a performance indicator, which is labor-intensive and time-consuming. These limitations prevent efficiently capturing continuous changes in trust at more granular timescales throughout the collaboration task. Therefore, this paper presents a new framework for the estimation of human trust using a beta reputation at fine-grained timescales. To achieve granularity in beta reputation, we utilize continuous reward values to update trust estimations at each timestep of a task. We construct a continuous reward function using maximum entropy optimization to eliminate the need for the laborious specification of a performance indicator. The proposed framework improves trust estimations by increasing accuracy, eliminating the need for manually crafting a reward function, and advancing toward developing more intelligent robots. The source code is publicly available. https://github.com/resuldagdanov/robot-learning-human-trust
Self-Improving Safety Performance of Reinforcement Learning Based Driving with Black-Box Verification Algorithms
Oct 29, 2022



In this work, we propose a self-improving artificial intelligence system for enhancing the safety performance of reinforcement learning (RL) based autonomous driving (AD) agents based on black-box verification methods. RL methods have enjoyed popularity among AD applications in recent years. That being said, existing RL algorithms' performance strongly depends on the diversity of training scenarios. Lack of safety-critical scenarios in the training phase might lead to poor generalization performance in real-world driving applications. We propose a novel framework, where the weaknesses of the training set are explored via black-box verification methods. After the discovery of AD failure scenarios, the training of the RL agent is re-initiated to improve the performance of the previously unsafe scenarios. Simulation results show that the proposed approach efficiently discovers such safety failures in RL-based adaptive cruise control (ACC) applications and significantly reduces the number of vehicle collisions through iterative applications of our method.
DeFIX: Detecting and Fixing Failure Scenarios with Reinforcement Learning in Imitation Learning Based Autonomous Driving
Oct 29, 2022



Safely navigating through an urban environment without violating any traffic rules is a crucial performance target for reliable autonomous driving. In this paper, we present a Reinforcement Learning (RL) based methodology to DEtect and FIX (DeFIX) failures of an Imitation Learning (IL) agent by extracting infraction spots and re-constructing mini-scenarios on these infraction areas to train an RL agent for fixing the shortcomings of the IL approach. DeFIX is a continuous learning framework, where extraction of failure scenarios and training of RL agents are executed in an infinite loop. After each new policy is trained and added to the library of policies, a policy classifier method effectively decides on which policy to activate at each step during the evaluation. It is demonstrated that even with only one RL agent trained on failure scenario of an IL agent, DeFIX method is either competitive or does outperform state-of-the-art IL and RL based autonomous urban driving benchmarks. We trained and validated our approach on the most challenging map (Town05) of CARLA simulator which involves complex, realistic, and adversarial driving scenarios. The source code is publicly available at https://github.com/data-and-decision-lab/DeFIX
* 6 pages, 4 figures, 2 tables, published in IEEE International Conference on Intelligent Transportation Systems (ITSC), October 12, 2022, Macau, China
Investigating Value of Curriculum Reinforcement Learning in Autonomous Driving Under Diverse Road and Weather Conditions
Mar 14, 2021
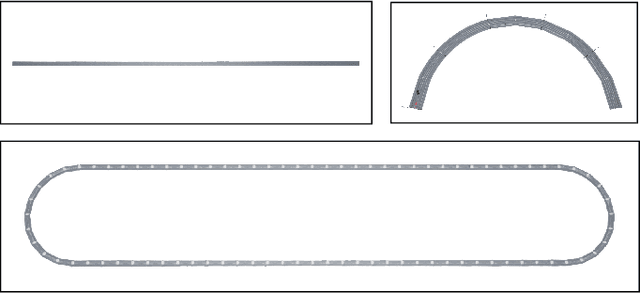
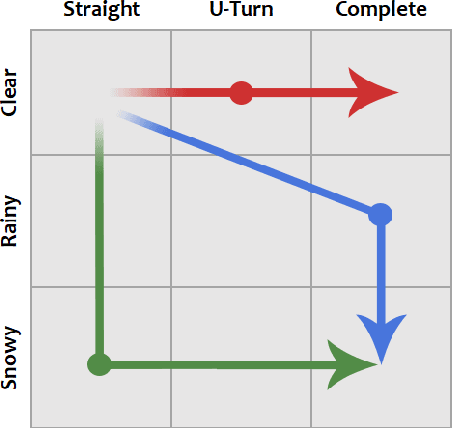
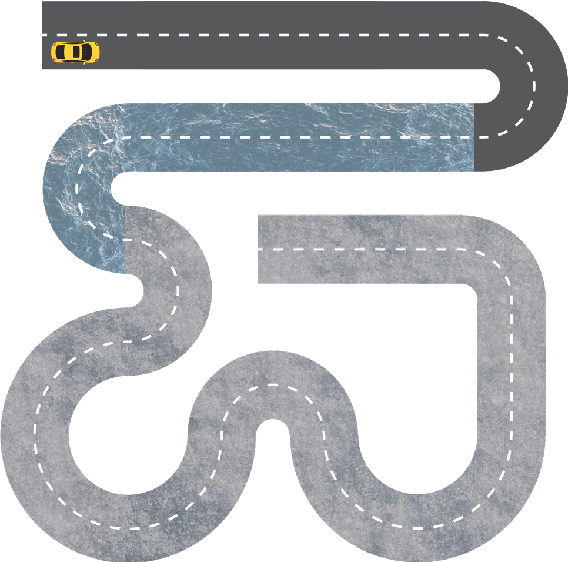
Applications of reinforcement learning (RL) are popular in autonomous driving tasks. That being said, tuning the performance of an RL agent and guaranteeing the generalization performance across variety of different driving scenarios is still largely an open problem. In particular, getting good performance on complex road and weather conditions require exhaustive tuning and computation time. Curriculum RL, which focuses on solving simpler automation tasks in order to transfer knowledge to complex tasks, is attracting attention in RL community. The main contribution of this paper is a systematic study for investigating the value of curriculum reinforcement learning in autonomous driving applications. For this purpose, we setup several different driving scenarios in a realistic driving simulator, with varying road complexity and weather conditions. Next, we train and evaluate performance of RL agents on different sequences of task combinations and curricula. Results show that curriculum RL can yield significant gains in complex driving tasks, both in terms of driving performance and sample complexity. Results also demonstrate that different curricula might enable different benefits, which hints future research directions for automated curriculum training.